 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask and You Shall Receive: Optimizing Masked Language Modeling For Pretraining BabyLMs
Oct 23, 2025We describe our strategy for the 2025 edition of the BabyLM Challenge. Our main contribution is that of an improved form of Masked Language Modeling (MLM), which adapts the probabilities of the tokens masked according to the model's ability to predict them. The results show a substantial increase in performance on (Super)GLUE tasks over the standard MLM. We also incorporate sub-token embeddings, finding that this increases the model's morphological generalization capabilities. Our submission beats the baseline in the strict-small track.
EXECUTE: A Multilingual Benchmark for LLM Token Understanding
May 23, 2025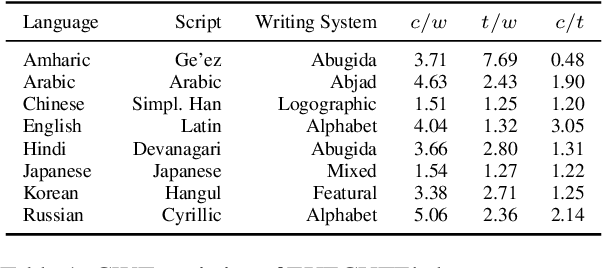
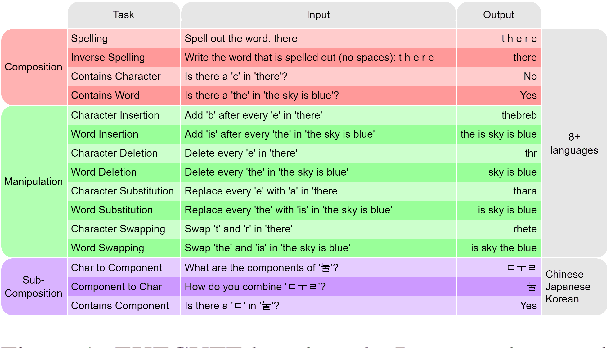
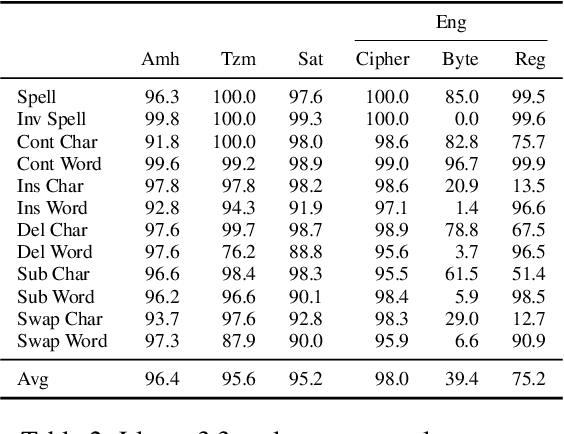
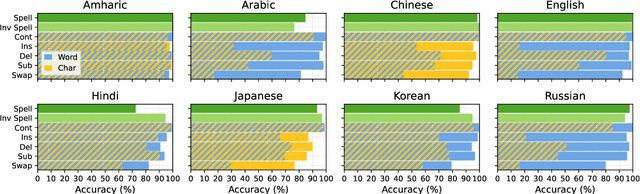
The CUTE benchmark showed that LLMs struggle with character understanding in English. We extend it to more languages with diverse scripts and writing systems, introducing EXECUTE. Our simplified framework allows easy expansion to any language. Tests across multiple LLMs reveal that challenges in other languages are not always on the character level as in English. Some languages show word-level processing issues, some show no issues at all. We also examine sub-character tasks in Chinese, Japanese, and Korean to assess LLMs' understanding of character components.
Are BabyLMs Second Language Learners?
Oct 28, 2024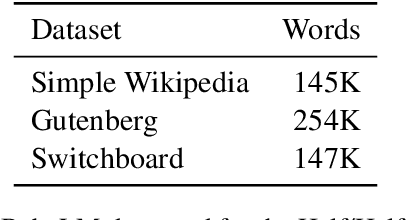


This paper describes a linguistically-motivated approach to the 2024 edition of the BabyLM Challenge (Warstadt et al. 2023). Rather than pursuing a first language learning (L1) paradigm, we approach the challenge from a second language (L2) learning perspective. In L2 learning, there is a stronger focus on learning explicit linguistic information, such as grammatical notions, definitions of words or different ways of expressing a meaning. This makes L2 learning potentially more efficient and concise. We approximate this using data from Wiktionary, grammar examples either generated by an LLM or sourced from grammar books, and paraphrase data. We find that explicit information about word meaning (in our case, Wiktionary) does not boost model performance, while grammatical information can give a small improvement. The most impactful data ingredient is sentence paraphrases, with our two best models being trained on 1) a mix of paraphrase data and data from the BabyLM pretraining dataset, and 2) exclusively paraphrase data.
Too Much Information: Keeping Training Simple for BabyLMs
Nov 03, 2023
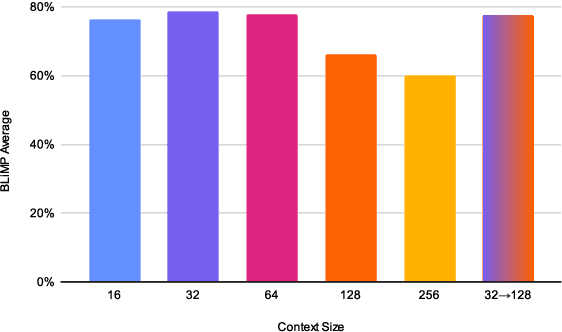


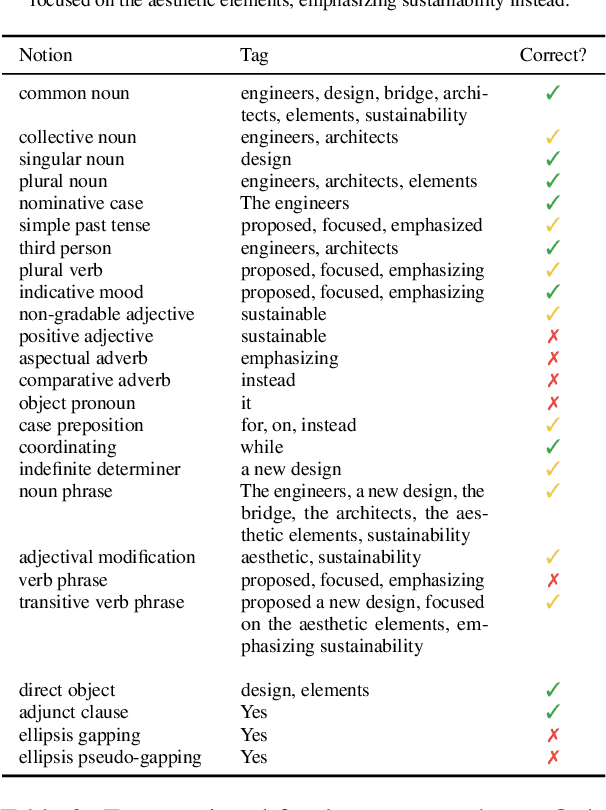
This paper details the work of the University of Groningen for the BabyLM Challenge. We follow the idea that, like babies, language models should be introduced to simpler concepts first and build off of that knowledge to understand more complex concepts. We examine this strategy of simple-then-complex through a variety of lenses, namely context size, vocabulary, and overall linguistic complexity of the data. We find that only one, context size, is truly beneficial to training a language model. However this simple change to context size gives us improvements of 2 points on average on (Super)GLUE tasks, 1 point on MSGS tasks, and 12\% on average on BLiMP tasks. Our context-limited model outperforms the baseline that was trained on 10$\times$ the amount of data.
LCT-1 at SemEval-2023 Task 10: Pre-training and Multi-task Learning for Sexism Detection and Classification
Jun 08, 2023



Misogyny and sexism are growing problems in social media. Advances have been made in online sexism detection but the systems are often uninterpretable. SemEval-2023 Task 10 on Explainable Detection of Online Sexism aims at increasing explainability of the sexism detection, and our team participated in all the proposed subtasks. Our system is based on further domain-adaptive pre-training (Gururangan et al., 2020). Building on the Transformer-based models with the domain adaptation, we compare fine-tuning with multi-task learning and show that each subtask requires a different system configuration. In our experiments, multi-task learning performs on par with standard fine-tuning for sexism detection and noticeably better for coarse-grained sexism classification, while fine-tuning is preferable for fine-grained classification.
Are Character-level Translations Worth the Wait? An Extensive Comparison of Character- and Subword-level Models for Machine Translation
Feb 28, 2023Pretrained large character-level language models have been recently revitalized and shown to be competitive with subword models across a range of NLP tasks. However, there has not been any research showing their effectiveness in neural machine translation (NMT). This work performs an extensive comparison across multiple languages and experimental conditions of state-of-the-art character- and subword-level pre-trained models (ByT5 and mT5, respectively) on NMT, and shows that the former not only are effective in translation, but frequently outperform subword models, particularly in cases where training data is limited. The only drawback of character models appears to be their inefficiency (at least 4 times slower to train and for inference). Further analysis indicates that character models are capable of implicitly translating on the word or subword level, thereby nullifying a major potential weakness of operating on the character level.
Subword-Delimited Downsampling for Better Character-Level Translation
Dec 02, 2022

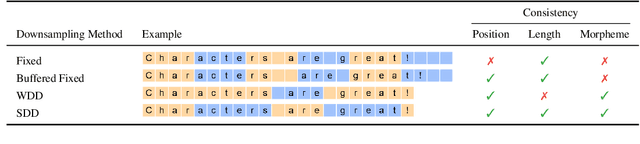

Subword-level models have been the dominant paradigm in NLP. However, character-level models have the benefit of seeing each character individually, providing the model with more detailed information that ultimately could lead to better models. Recent works have shown character-level models to be competitive with subword models, but costly in terms of time and computation. Character-level models with a downsampling component alleviate this, but at the cost of quality, particularly for machine translation. This work analyzes the problems of previous downsampling methods and introduces a novel downsampling method which is informed by subwords. This new downsampling method not only outperforms existing downsampling methods, showing that downsampling characters can be done without sacrificing quality, but also leads to promising performance compared to subword models for translation.
Patching Leaks in the Charformer for Efficient Character-Level Generation
May 27, 2022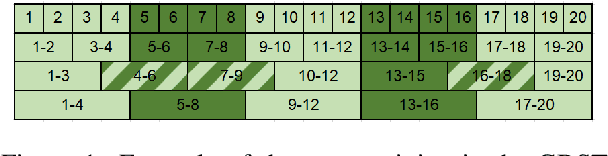

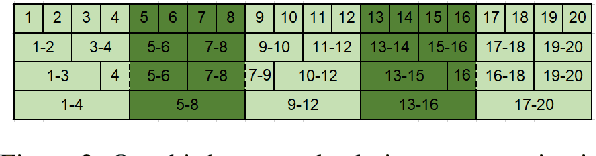
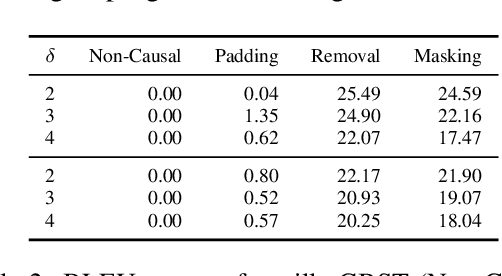
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.
The Importance of Context in Very Low Resource Language Modeling
May 10, 2022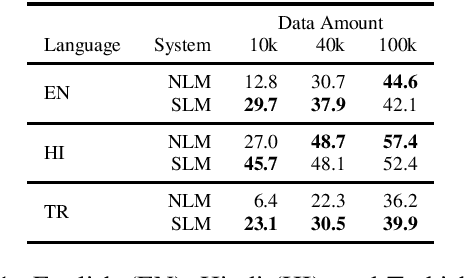
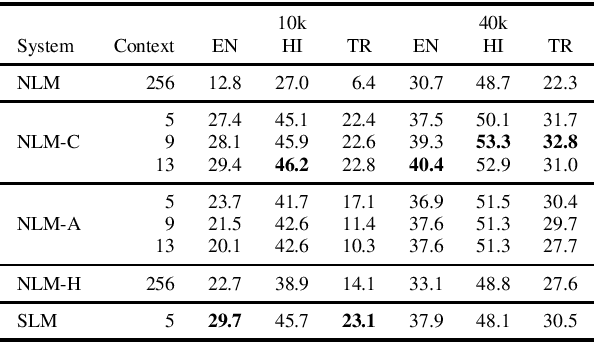
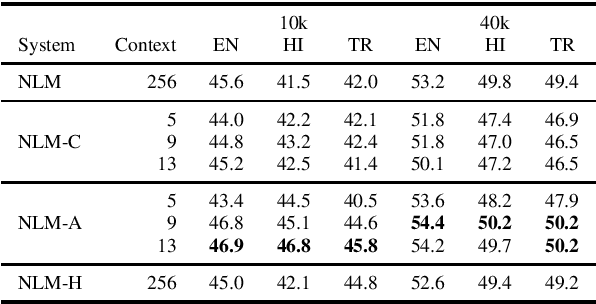
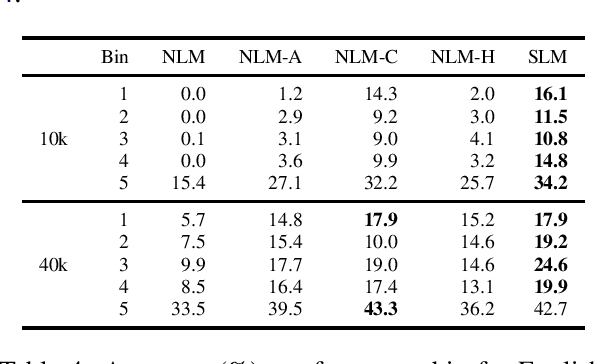
This paper investigates very low resource language model pretraining, when less than 100 thousand sentences are available. We find that, in very low resource scenarios, statistical n-gram language models outperform state-of-the-art neural models. Our experiments show that this is mainly due to the focus of the former on a local context. As such, we introduce three methods to improve a neural model's performance in the low-resource setting, finding that limiting the model's self-attention is the most effective one, improving on downstream tasks such as NLI and POS tagging by up to 5% for the languages we test on: English, Hindi, and Turkish.
Unsupervised Translation of German--Lower Sorbian: Exploring Training and Novel Transfer Methods on a Low-Resource Language
Sep 24, 2021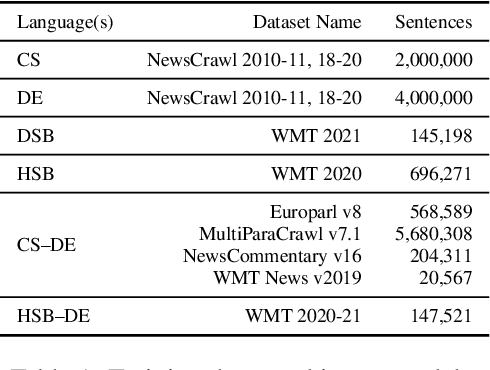
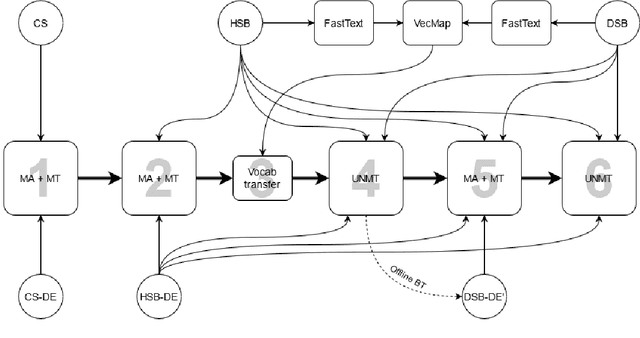
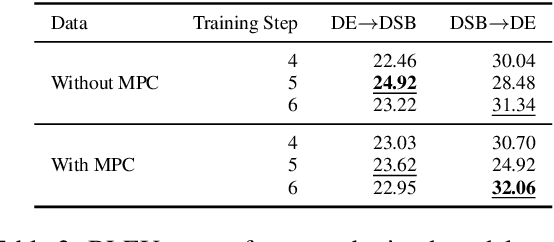
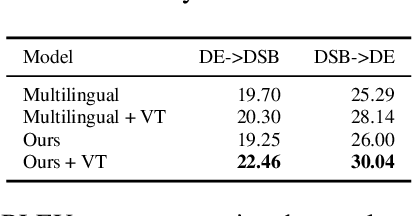
This paper describes the methods behind the systems submitted by the University of Groningen for the WMT 2021 Unsupervised Machine Translation task for German--Lower Sorbian (DE--DSB): a high-resource language to a low-resource one. Our system uses a transformer encoder-decoder architecture in which we make three changes to the standard training procedure. First, our training focuses on two languages at a time, contrasting with a wealth of research on multilingual systems. Second, we introduce a novel method for initializing the vocabulary of an unseen language, achieving improvements of 3.2 BLEU for DE$\rightarrow$DSB and 4.0 BLEU for DSB$\rightarrow$DE. Lastly, we experiment with the order in which offline and online back-translation are used to train an unsupervised system, finding that using online back-translation first works better for DE$\rightarrow$DSB by 2.76 BLEU. Our submissions ranked first (tied with another team) for DSB$\rightarrow$DE and third for DE$\rightarrow$DSB.