 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Hate Speech Detection via Cross-Lingual Nearest Neighbor Retrieval with Limited Labeled Data
May 20, 2025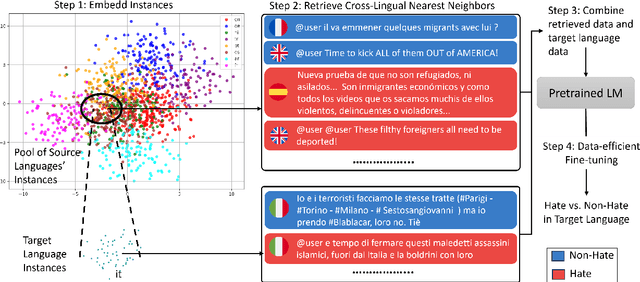
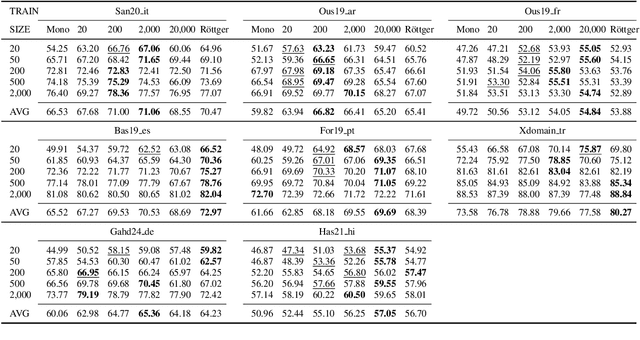
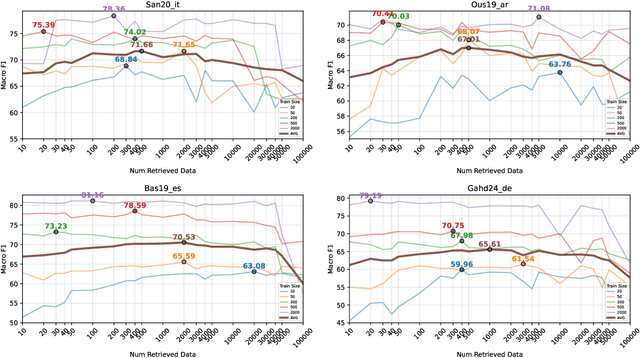
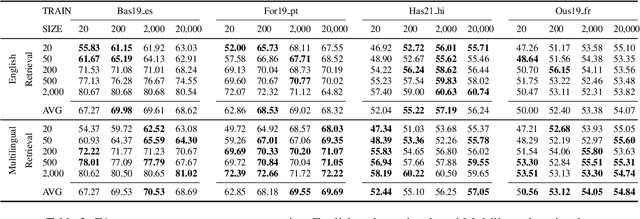
Considering the importance of detecting hateful language, labeled hate speech data is expensive and time-consuming to collect, particularly for low-resource languages. Prior work has demonstrated the effectiveness of cross-lingual transfer learning and data augmentation in improving performance on tasks with limited labeled data. To develop an efficient and scalable cross-lingual transfer learning approach, we leverage nearest-neighbor retrieval to augment minimal labeled data in the target language, thereby enhancing detection performance. Specifically, we assume access to a small set of labeled training instances in the target language and use these to retrieve the most relevant labeled examples from a large multilingual hate speech detection pool. We evaluate our approach on eight languages and demonstrate that it consistently outperforms models trained solely on the target language data. Furthermore, in most cases, our method surpasses the current state-of-the-art. Notably, our approach is highly data-efficient, retrieving as small as 200 instances in some cases while maintaining superior performance. Moreover, it is scalable, as the retrieval pool can be easily expanded, and the method can be readily adapted to new languages and tasks. We also apply maximum marginal relevance to mitigate redundancy and filter out highly similar retrieved instances, resulting in improvements in some languages.
Can Prompting LLMs Unlock Hate Speech Detection across Languages? A Zero-shot and Few-shot Study
May 09, 2025Despite growing interest in automated hate speech detection, most existing approaches overlook the linguistic diversity of online content. Multilingual instruction-tuned large language models such as LLaMA, Aya, Qwen, and BloomZ offer promising capabilities across languages, but their effectiveness in identifying hate speech through zero-shot and few-shot prompting remains underexplored. This work evaluates LLM prompting-based detection across eight non-English languages, utilizing several prompting techniques and comparing them to fine-tuned encoder models. We show that while zero-shot and few-shot prompting lag behind fine-tuned encoder models on most of the real-world evaluation sets, they achieve better generalization on functional tests for hate speech detection. Our study also reveals that prompt design plays a critical role, with each language often requiring customized prompting techniques to maximize performance.
Differentiating Emigration from Return Migration of Scholars Using Name-Based Nationality Detection Models
May 09, 2025Most web and digital trace data do not include information about an individual's nationality due to privacy concerns. The lack of data on nationality can create challenges for migration research. It can lead to a left-censoring issue since we are uncertain about the migrant's country of origin. Once we observe an emigration event, if we know the nationality, we can differentiate it from return migration. We propose methods to detect the nationality with the least available data, i.e., full names. We use the detected nationality in comparison with the country of academic origin, which is a common approach in studying the migration of researchers. We gathered 2.6 million unique name-nationality pairs from Wikipedia and categorized them into families of nationalities with three granularity levels to use as our training data. Using a character-based machine learning model, we achieved a weighted F1 score of 84% for the broadest and 67% for the most granular, country-level categorization. In our empirical study, we used the trained and tested model to assign nationality to 8+ million scholars' full names in Scopus data. Our results show that using the country of first publication as a proxy for nationality underestimates the size of return flows, especially for countries with a more diverse academic workforce, such as the USA, Australia, and Canada. We found that around 48% of emigration from the USA was return migration once we used the country of name origin, in contrast to 33% based on academic origin. In the most recent period, 79% of scholars whose affiliation has consistently changed from the USA to China, and are considered emigrants, have Chinese names in contrast to 41% with a Chinese academic origin. Our proposed methods for addressing left-censoring issues are beneficial for other research that uses digital trace data to study migration.
Are BabyLMs Second Language Learners?
Oct 28, 2024

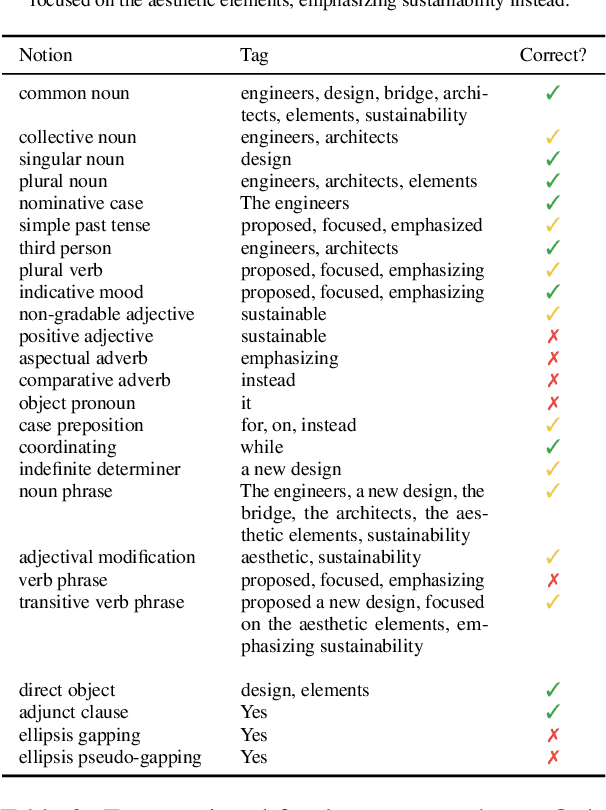

This paper describes a linguistically-motivated approach to the 2024 edition of the BabyLM Challenge (Warstadt et al. 2023). Rather than pursuing a first language learning (L1) paradigm, we approach the challenge from a second language (L2) learning perspective. In L2 learning, there is a stronger focus on learning explicit linguistic information, such as grammatical notions, definitions of words or different ways of expressing a meaning. This makes L2 learning potentially more efficient and concise. We approximate this using data from Wiktionary, grammar examples either generated by an LLM or sourced from grammar books, and paraphrase data. We find that explicit information about word meaning (in our case, Wiktionary) does not boost model performance, while grammatical information can give a small improvement. The most impactful data ingredient is sentence paraphrases, with our two best models being trained on 1) a mix of paraphrase data and data from the BabyLM pretraining dataset, and 2) exclusively paraphrase data.
FNR: A Similarity and Transformer-Based Approachto Detect Multi-Modal FakeNews in Social Media
Dec 02, 2021
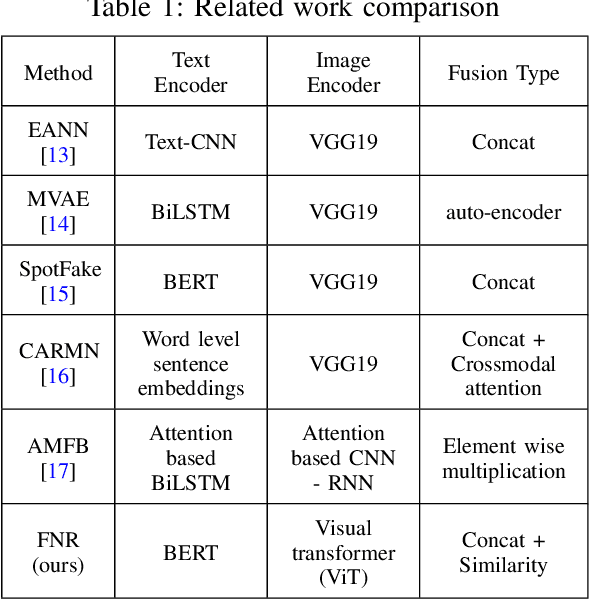
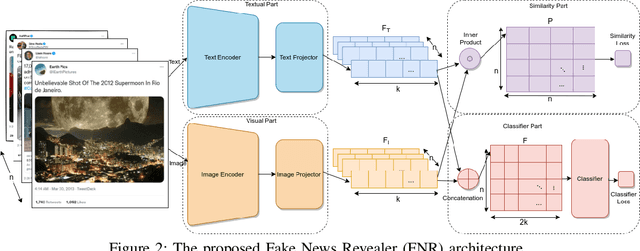

The availability and interactive nature of social media have made them the primary source of news around the globe. The popularity of social media tempts criminals to pursue their immoral intentions by producing and disseminating fake news using seductive text and misleading images. Therefore, verifying social media news and spotting fakes is crucial. This work aims to analyze multi-modal features from texts and images in social media for detecting fake news. We propose a Fake News Revealer (FNR) method that utilizes transform learning to extract contextual and semantic features and contrastive loss to determine the similarity between image and text. We applied FNR on two real social media datasets. The results show the proposed method achieves higher accuracies in detecting fake news compared to the previous works.