 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Semantic Textual Similarity via Dissimilar Span Detection
Mar 22, 2026Semantic Textual Similarity (STS) is a crucial component of many Natural Language Processing (NLP) applications. However, existing approaches typically reduce semantic nuances to a single score, limiting interpretability. To address this, we introduce the task of Dissimilar Span Detection (DSD), which aims to identify semantically differing spans between pairs of texts. This can help users understand which particular words or tokens negatively affect the similarity score, or be used to improve performance in STS-dependent downstream tasks. Furthermore, we release a new dataset suitable for the task, the Span Similarity Dataset (SSD), developed through a semi-automated pipeline combining large language models (LLMs) with human verification. We propose and evaluate different baseline methods for DSD, both unsupervised, based on LIME, SHAP, LLMs, and our own method, as well as an additional supervised approach. While LLMs and supervised models achieve the highest performance, overall results remain low, highlighting the complexity of the task. Finally, we set up an additional experiment that shows how DSD can lead to increased performance in the specific task of paraphrase detection.
Self-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
Low-Resource, High-Impact: Building Corpora for Inclusive Language Technologies
Dec 16, 2025This tutorial (https://tum-nlp.github.io/low-resource-tutorial) is designed for NLP practitioners, researchers, and developers working with multilingual and low-resource languages who seek to create more equitable and socially impactful language technologies. Participants will walk away with a practical toolkit for building end-to-end NLP pipelines for underrepresented languages -- from data collection and web crawling to parallel sentence mining, machine translation, and downstream applications such as text classification and multimodal reasoning. The tutorial presents strategies for tackling the challenges of data scarcity and cultural variance, offering hands-on methods and modeling frameworks. We will focus on fair, reproducible, and community-informed development approaches, grounded in real-world scenarios. We will showcase a diverse set of use cases covering over 10 languages from different language families and geopolitical contexts, including both digitally resource-rich and severely underrepresented languages.
EmoBench-UA: A Benchmark Dataset for Emotion Detection in Ukrainian
May 29, 2025While Ukrainian NLP has seen progress in many texts processing tasks, emotion classification remains an underexplored area with no publicly available benchmark to date. In this work, we introduce EmoBench-UA, the first annotated dataset for emotion detection in Ukrainian texts. Our annotation schema is adapted from the previous English-centric works on emotion detection (Mohammad et al., 2018; Mohammad, 2022) guidelines. The dataset was created through crowdsourcing using the Toloka.ai platform ensuring high-quality of the annotation process. Then, we evaluate a range of approaches on the collected dataset, starting from linguistic-based baselines, synthetic data translated from English, to large language models (LLMs). Our findings highlight the challenges of emotion classification in non-mainstream languages like Ukrainian and emphasize the need for further development of Ukrainian-specific models and training resources.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Data-Efficient Hate Speech Detection via Cross-Lingual Nearest Neighbor Retrieval with Limited Labeled Data
May 20, 2025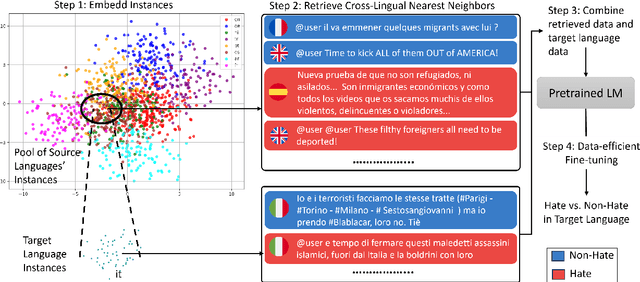
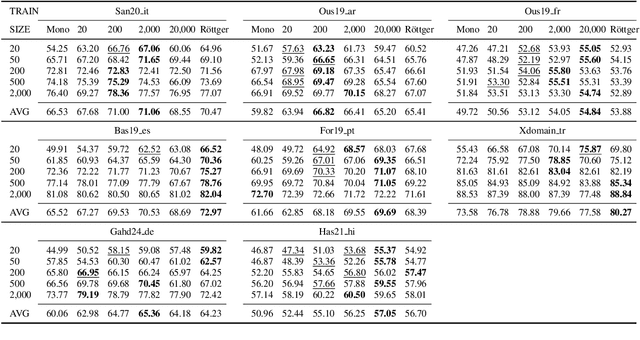
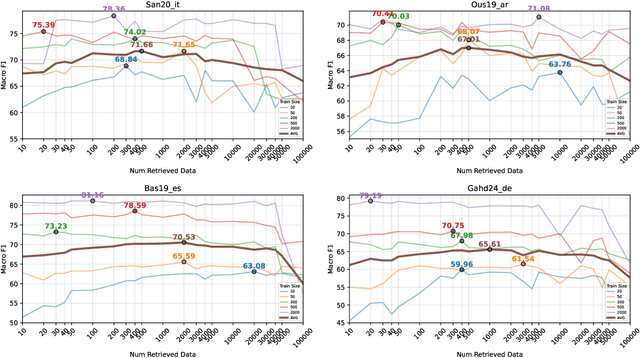
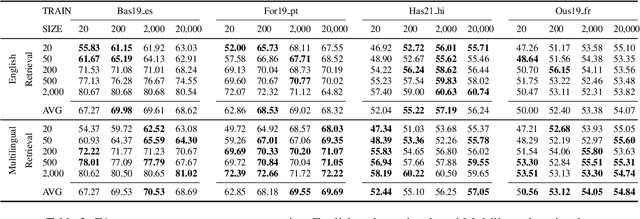
Considering the importance of detecting hateful language, labeled hate speech data is expensive and time-consuming to collect, particularly for low-resource languages. Prior work has demonstrated the effectiveness of cross-lingual transfer learning and data augmentation in improving performance on tasks with limited labeled data. To develop an efficient and scalable cross-lingual transfer learning approach, we leverage nearest-neighbor retrieval to augment minimal labeled data in the target language, thereby enhancing detection performance. Specifically, we assume access to a small set of labeled training instances in the target language and use these to retrieve the most relevant labeled examples from a large multilingual hate speech detection pool. We evaluate our approach on eight languages and demonstrate that it consistently outperforms models trained solely on the target language data. Furthermore, in most cases, our method surpasses the current state-of-the-art. Notably, our approach is highly data-efficient, retrieving as small as 200 instances in some cases while maintaining superior performance. Moreover, it is scalable, as the retrieval pool can be easily expanded, and the method can be readily adapted to new languages and tasks. We also apply maximum marginal relevance to mitigate redundancy and filter out highly similar retrieved instances, resulting in improvements in some languages.
Can Prompting LLMs Unlock Hate Speech Detection across Languages? A Zero-shot and Few-shot Study
May 09, 2025Despite growing interest in automated hate speech detection, most existing approaches overlook the linguistic diversity of online content. Multilingual instruction-tuned large language models such as LLaMA, Aya, Qwen, and BloomZ offer promising capabilities across languages, but their effectiveness in identifying hate speech through zero-shot and few-shot prompting remains underexplored. This work evaluates LLM prompting-based detection across eight non-English languages, utilizing several prompting techniques and comparing them to fine-tuned encoder models. We show that while zero-shot and few-shot prompting lag behind fine-tuned encoder models on most of the real-world evaluation sets, they achieve better generalization on functional tests for hate speech detection. Our study also reveals that prompt design plays a critical role, with each language often requiring customized prompting techniques to maximize performance.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Multilingual and Explainable Text Detoxification with Parallel Corpora
Dec 16, 2024Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
Crafting Tomorrow's Headlines: Neural News Generation and Detection in English, Turkish, Hungarian, and Persian
Aug 20, 2024



In the era dominated by information overload and its facilitation with Large Language Models (LLMs), the prevalence of misinformation poses a significant threat to public discourse and societal well-being. A critical concern at present involves the identification of machine-generated news. In this work, we take a significant step by introducing a benchmark dataset designed for neural news detection in four languages: English, Turkish, Hungarian, and Persian. The dataset incorporates outputs from multiple multilingual generators (in both, zero-shot and fine-tuned setups) such as BloomZ, LLaMa-2, Mistral, Mixtral, and GPT-4. Next, we experiment with a variety of classifiers, ranging from those based on linguistic features to advanced Transformer-based models and LLMs prompting. We present the detection results aiming to delve into the interpretablity and robustness of machine-generated texts detectors across all target languages.