 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Classification in Ukrainian
Apr 27, 2024The task of toxicity detection is still a relevant task, especially in the context of safe and fair LMs development. Nevertheless, labeled binary toxicity classification corpora are not available for all languages, which is understandable given the resource-intensive nature of the annotation process. Ukrainian, in particular, is among the languages lacking such resources. To our knowledge, there has been no existing toxicity classification corpus in Ukrainian. In this study, we aim to fill this gap by investigating cross-lingual knowledge transfer techniques and creating labeled corpora by: (i)~translating from an English corpus, (ii)~filtering toxic samples using keywords, and (iii)~annotating with crowdsourcing. We compare LLMs prompting and other cross-lingual transfer approaches with and without fine-tuning offering insights into the most robust and efficient baselines.
Ukrainian Texts Classification: Exploration of Cross-lingual Knowledge Transfer Approaches
Apr 02, 2024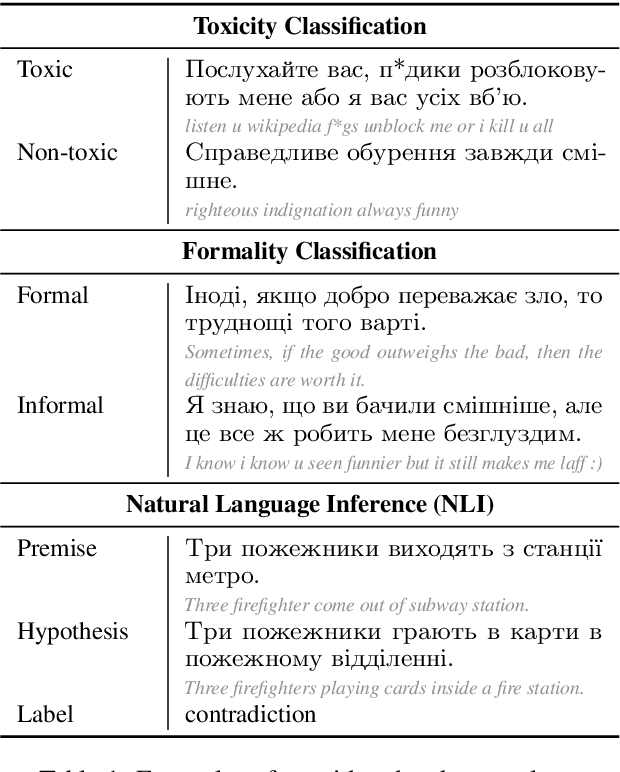
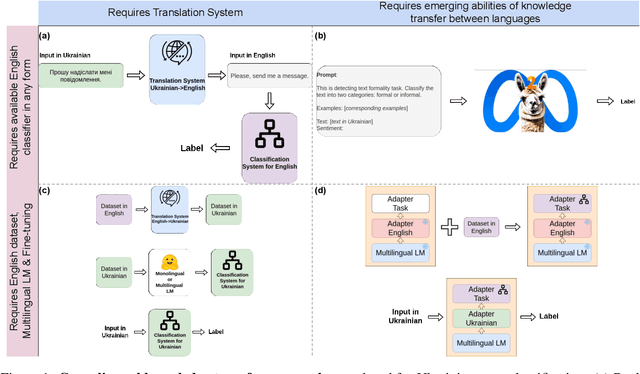
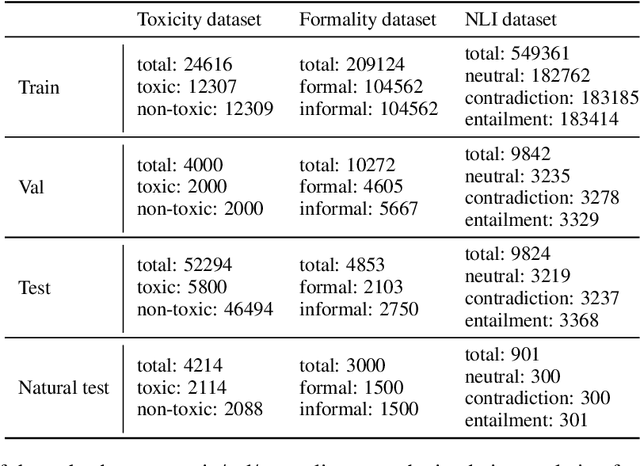
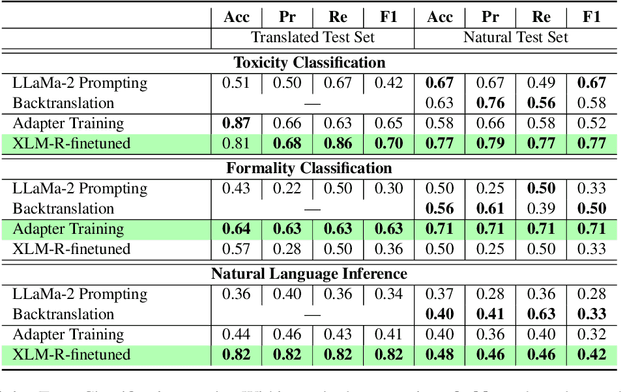
Despite the extensive amount of labeled datasets in the NLP text classification field, the persistent imbalance in data availability across various languages remains evident. Ukrainian, in particular, stands as a language that still can benefit from the continued refinement of cross-lingual methodologies. Due to our knowledge, there is a tremendous lack of Ukrainian corpora for typical text classification tasks. In this work, we leverage the state-of-the-art advances in NLP, exploring cross-lingual knowledge transfer methods avoiding manual data curation: large multilingual encoders and translation systems, LLMs, and language adapters. We test the approaches on three text classification tasks -- toxicity classification, formality classification, and natural language inference -- providing the "recipe" for the optimal setups.