 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are Overparameterized Text Encoders
Oct 18, 2024



Large language models (LLMs) demonstrate strong performance as text embedding models when finetuned with supervised contrastive training. However, their large size balloons inference time and memory requirements. In this paper, we show that by pruning the last $p\%$ layers of an LLM before supervised training for only 1000 steps, we can achieve a proportional reduction in memory and inference time. We evaluate four different state-of-the-art LLMs on text embedding tasks and find that our method can prune up to 30\% of layers with negligible impact on performance and up to 80\% with only a modest drop. With only three lines of code, our method is easily implemented in any pipeline for transforming LLMs to text encoders. We also propose $\text{L}^3 \text{Prune}$, a novel layer-pruning strategy based on the model's initial loss that provides two optimal pruning configurations: a large variant with negligible performance loss and a small variant for resource-constrained settings. On average, the large variant prunes 21\% of the parameters with a $-0.3$ performance drop, and the small variant only suffers from a $-5.1$ decrease while pruning 74\% of the model. We consider these results strong evidence that LLMs are overparameterized for text embedding tasks, and can be easily pruned.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
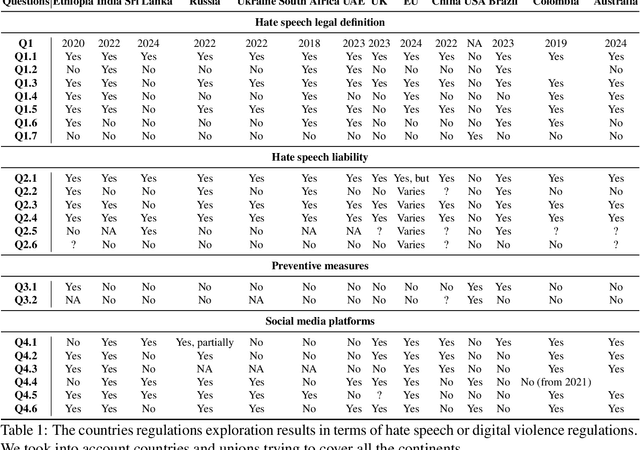
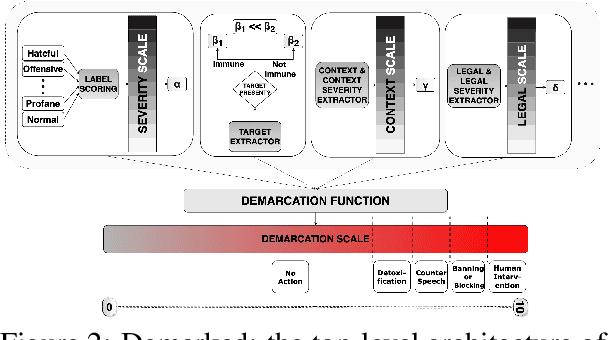

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
Optimizing Foundation Model Inference on a Many-tiny-core Open-source RISC-V Platform
May 29, 2024Transformer-based foundation models have become crucial for various domains, most notably natural language processing (NLP) or computer vision (CV). These models are predominantly deployed on high-performance GPUs or hardwired accelerators with highly customized, proprietary instruction sets. Until now, limited attention has been given to RISC-V-based general-purpose platforms. In our work, we present the first end-to-end inference results of transformer models on an open-source many-tiny-core RISC-V platform implementing distributed Softmax primitives and leveraging ISA extensions for SIMD floating-point operand streaming and instruction repetition, as well as specialized DMA engines to minimize costly main memory accesses and to tolerate their latency. We focus on two foundational transformer topologies, encoder-only and decoder-only models. For encoder-only models, we demonstrate a speedup of up to 12.8x between the most optimized implementation and the baseline version. We reach over 79% FPU utilization and 294 GFLOPS/W, outperforming State-of-the-Art (SoA) accelerators by more than 2x utilizing the HW platform while achieving comparable throughput per computational unit. For decoder-only topologies, we achieve 16.1x speedup in the Non-Autoregressive (NAR) mode and up to 35.6x speedup in the Autoregressive (AR) mode compared to the baseline implementation. Compared to the best SoA dedicated accelerator, we achieve 2.04x higher FPU utilization.
ITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers
Jul 10, 2023



Transformer networks have emerged as the state-of-the-art approach for natural language processing tasks and are gaining popularity in other domains such as computer vision and audio processing. However, the efficient hardware acceleration of transformer models poses new challenges due to their high arithmetic intensities, large memory requirements, and complex dataflow dependencies. In this work, we propose ITA, a novel accelerator architecture for transformers and related models that targets efficient inference on embedded systems by exploiting 8-bit quantization and an innovative softmax implementation that operates exclusively on integer values. By computing on-the-fly in streaming mode, our softmax implementation minimizes data movement and energy consumption. ITA achieves competitive energy efficiency with respect to state-of-the-art transformer accelerators with 16.9 TOPS/W, while outperforming them in area efficiency with 5.93 TOPS/mm$^2$ in 22 nm fully-depleted silicon-on-insulator technology at 0.8 V.
Automatic detection of lesion load change in Multiple Sclerosis using convolutional neural networks with segmentation confidence
Apr 05, 2019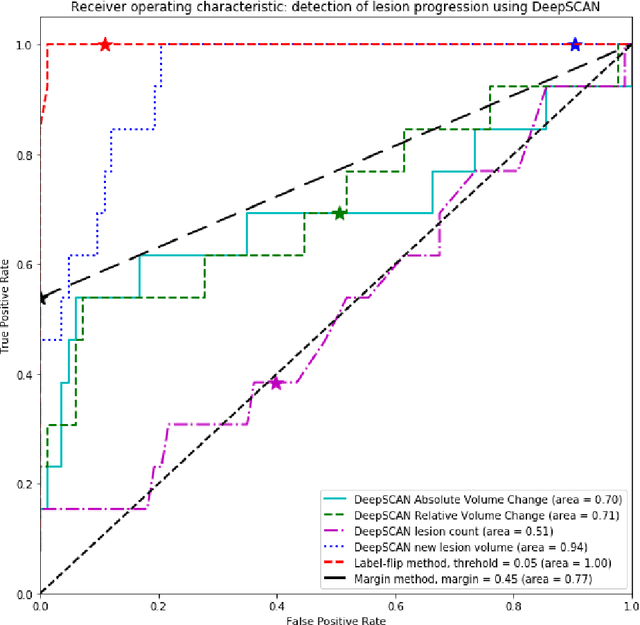
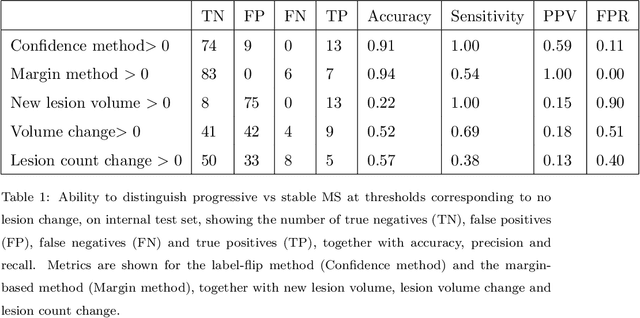
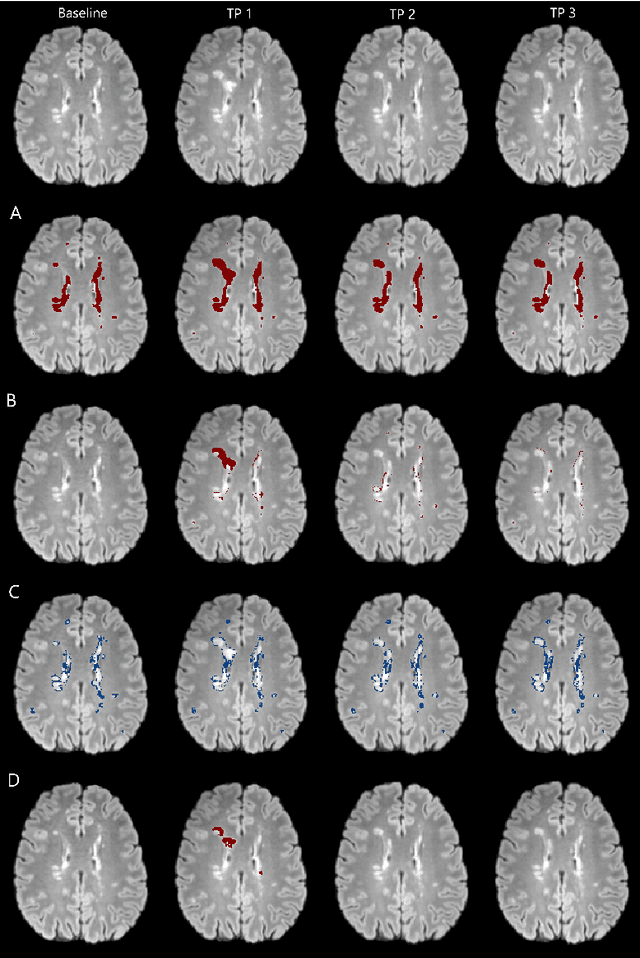
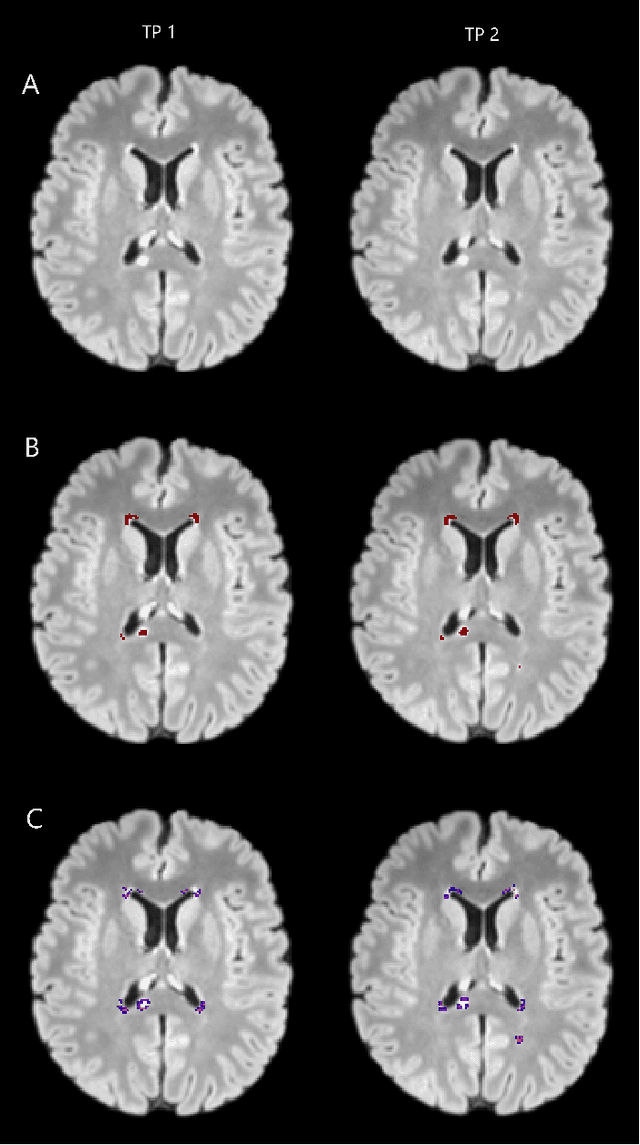
The detection of new or enlarged white-matter lesions in multiple sclerosis is a vital task in the monitoring of patients undergoing disease-modifying treatment for multiple sclerosis. However, the definition of 'new or enlarged' is not fixed, and it is known that lesion-counting is highly subjective, with high degree of inter- and intra-rater variability. Automated methods for lesion quantification hold the potential to make the detection of new and enlarged lesions consistent and repeatable. However, the majority of lesion segmentation algorithms are not evaluated for their ability to separate progressive from stable patients, despite this being a pressing clinical use-case. In this paper we show that change in volumetric measurements of lesion load alone is not a good method for performing this separation, even for highly performing segmentation methods. Instead, we propose a method for identifying lesion changes of high certainty, and establish on a dataset of longitudinal multiple sclerosis cases that this method is able to separate progressive from stable timepoints with a very high level of discrimination (AUC = 0.99), while changes in lesion volume are much less able to perform this separation (AUC = 0.71). Validation of the method on a second external dataset confirms that the method is able to generalize beyond the setting in which it was trained, achieving an accuracy of 83% in separating stable and progressive timepoints. Both lesion volume and count have previously been shown to be strong predictors of disease course across a population. However, we demonstrate that for individual patients, changes in these measures are not an adequate means of establishing no evidence of disease activity. Meanwhile, directly detecting tissue which changes, with high confidence, from non-lesion to lesion is a feasible methodology for identifying radiologically active patients.