 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Calibration: Provably Optimal Decoding in LLMs
May 11, 2026LLM decoding often relies on the model's predictive distribution to generate an output. Consequently, misalignment with respect to the true generating distribution leads to suboptimal decisions in practice. While a natural solution is to calibrate the model's output distribution, for LLMs, this is ill-posed at the combinatorially vast level of free-form language. We address this by building on the insight that in many tasks, these free-form outputs can be interpreted in a semantically meaningful latent structure, for example, discrete class labels, integers, or sets. We introduce task calibration as a paradigm to calibrate the model's predictive distribution in the task-induced latent space. We apply a decision-theoretic result to show that Minimum Bayes Risk (MBR) decoding on the task-calibrated latent distribution is the optimal decoding strategy on latent model beliefs. Empirically, it consistently improves generation quality across different tasks and baselines. We also introduce Task Calibration Error (TCE), an application-aware calibration metric that quantifies the excess loss due to miscalibration. Our work demonstrates that task calibration enables more reliable model decisions across various tasks and applications.
Incentive Aware AI Regulations: A Credal Characterisation
Mar 05, 2026While high-stakes ML applications demand strict regulations, strategic ML providers often evade them to lower development costs. To address this challenge, we cast AI regulation as a mechanism design problem under uncertainty and introduce regulation mechanisms: a framework that maps empirical evidence from models to a license for some market share. The providers can select from a set of licenses, effectively forcing them to bet on their model's ability to fulfil regulation. We aim at regulation mechanisms that achieve perfect market outcome, i.e. (a) drive non-compliant providers to self-exclude, and (b) ensure participation from compliant providers. We prove that a mechanism has perfect market outcome if and only if the set of non-compliant distributions forms a credal set, i.e., a closed, convex set of probability measures. This result connects mechanism design and imprecise probability by establishing a duality between regulation mechanisms and the set of non-compliant distributions. We also demonstrate these mechanisms in practice via experiments on regulating use of spurious features for prediction and fairness. Our framework provides new insights at the intersection of mechanism design and imprecise probability, offering a foundation for development of enforceable AI regulations.
Detecting Object Tracking Failure via Sequential Hypothesis Testing
Feb 13, 2026Real-time online object tracking in videos constitutes a core task in computer vision, with wide-ranging applications including video surveillance, motion capture, and robotics. Deployed tracking systems usually lack formal safety assurances to convey when tracking is reliable and when it may fail, at best relying on heuristic measures of model confidence to raise alerts. To obtain such assurances we propose interpreting object tracking as a sequential hypothesis test, wherein evidence for or against tracking failures is gradually accumulated over time. Leveraging recent advancements in the field, our sequential test (formalized as an e-process) quickly identifies when tracking failures set in whilst provably containing false alerts at a desired rate, and thus limiting potentially costly re-calibration or intervention steps. The approach is computationally light-weight, requires no extra training or fine-tuning, and is in principle model-agnostic. We propose both supervised and unsupervised variants by leveraging either ground-truth or solely internal tracking information, and demonstrate its effectiveness for two established tracking models across four video benchmarks. As such, sequential testing can offer a statistically grounded and efficient mechanism to incorporate safety assurances into real-time tracking systems.
Equity by Design: Fairness-Driven Recommendation in Heterogeneous Two-Sided Markets
Feb 12, 2026Two-sided marketplaces embody heterogeneity in incentives: producers seek exposure while consumers seek relevance, and balancing these competing objectives through constrained optimization is now a standard practice. Yet real platforms face finer-grained complexity: consumers differ in preferences and engagement patterns, producers vary in catalog value and capacity, and business objectives impose additional constraints beyond raw relevance. We formalize two-sided fairness under these realistic conditions, extending prior work from soft single-item allocations to discrete multi-item recommendations. We introduce Conditional Value-at-Risk (CVaR) as a consumer-side objective that compresses group-level utility disparities, and integrate business constraints directly into the optimization. Our experiments reveal that the "free fairness" regime, where producer constraints impose no consumer cost, disappears in multi item settings. Strikingly, moderate fairness constraints can improve business metrics by diversifying exposure away from saturated producers. Scalable solvers match exact solutions at a fraction of the runtime, making fairness-aware allocation practical at scale. These findings reframe fairness not as a tax on platform efficiency but as a lever for sustainable marketplace health.
Read Your Own Mind: Reasoning Helps Surface Self-Confidence Signals in LLMs
May 28, 2025We study the source of uncertainty in DeepSeek R1-32B by analyzing its self-reported verbal confidence on question answering (QA) tasks. In the default answer-then-confidence setting, the model is regularly over-confident, whereas semantic entropy - obtained by sampling many responses - remains reliable. We hypothesize that this is because of semantic entropy's larger test-time compute, which lets us explore the model's predictive distribution. We show that granting DeepSeek the budget to explore its distribution by forcing a long chain-of-thought before the final answer greatly improves its verbal score effectiveness, even on simple fact-retrieval questions that normally require no reasoning. Furthermore, a separate reader model that sees only the chain can reconstruct very similar confidences, indicating the verbal score might be merely a statistic of the alternatives surfaced during reasoning. Our analysis concludes that reliable uncertainty estimation requires explicit exploration of the generative space, and self-reported confidence is trustworthy only after such exploration.
On Calibration in Multi-Distribution Learning
Dec 18, 2024
Modern challenges of robustness, fairness, and decision-making in machine learning have led to the formulation of multi-distribution learning (MDL) frameworks in which a predictor is optimized across multiple distributions. We study the calibration properties of MDL to better understand how the predictor performs uniformly across the multiple distributions. Through classical results on decomposing proper scoring losses, we first derive the Bayes optimal rule for MDL, demonstrating that it maximizes the generalized entropy of the associated loss function. Our analysis reveals that while this approach ensures minimal worst-case loss, it can lead to non-uniform calibration errors across the multiple distributions and there is an inherent calibration-refinement trade-off, even at Bayes optimality. Our results highlight a critical limitation: despite the promise of MDL, one must use caution when designing predictors tailored to multiple distributions so as to minimize disparity.
Learning to Defer to a Population: A Meta-Learning Approach
Mar 05, 2024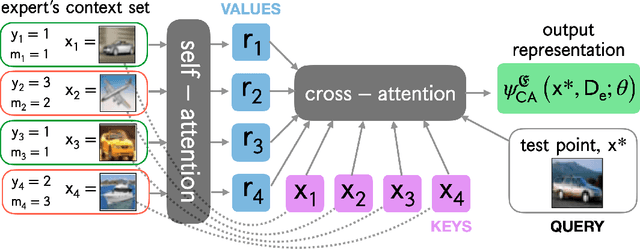



The learning to defer (L2D) framework allows autonomous systems to be safe and robust by allocating difficult decisions to a human expert. All existing work on L2D assumes that each expert is well-identified, and if any expert were to change, the system should be re-trained. In this work, we alleviate this constraint, formulating an L2D system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert's abilities. In the experiments, we validate our methods on image recognition, traffic sign detection, and skin lesion diagnosis benchmarks.
Learning to Defer to Multiple Experts: Consistent Surrogate Losses, Confidence Calibration, and Conformal Ensembles
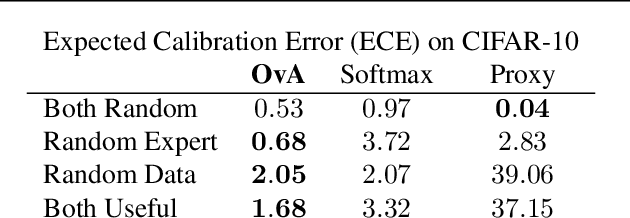
Oct 30, 2022We study the statistical properties of learning to defer (L2D) to multiple experts. In particular, we address the open problems of deriving a consistent surrogate loss, confidence calibration, and principled ensembling of experts. Firstly, we derive two consistent surrogates -- one based on a softmax parameterization, the other on a one-vs-all (OvA) parameterization -- that are analogous to the single expert losses proposed by Mozannar and Sontag (2020) and Verma and Nalisnick (2022), respectively. We then study the frameworks' ability to estimate P( m_j = y | x ), the probability that the jth expert will correctly predict the label for x. Theory shows the softmax-based loss causes mis-calibration to propagate between the estimates while the OvA-based loss does not (though in practice, we find there are trade offs). Lastly, we propose a conformal inference technique that chooses a subset of experts to query when the system defers. We perform empirical validation on tasks for galaxy, skin lesion, and hate speech classification.
Calibrated Learning to Defer with One-vs-All Classifiers
Feb 08, 2022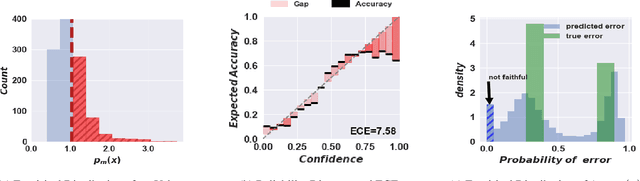
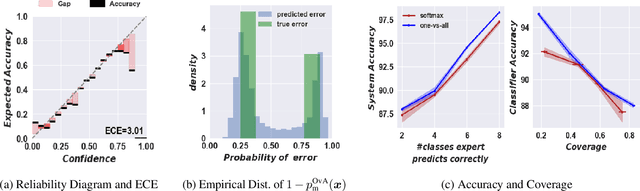
The learning to defer (L2D) framework has the potential to make AI systems safer. For a given input, the system can defer the decision to a human if the human is more likely than the model to take the correct action. We study the calibration of L2D systems, investigating if the probabilities they output are sound. We find that Mozannar & Sontag's (2020) multiclass framework is not calibrated with respect to expert correctness. Moreover, it is not even guaranteed to produce valid probabilities due to its parameterization being degenerate for this purpose. We propose an L2D system based on one-vs-all classifiers that is able to produce calibrated probabilities of expert correctness. Furthermore, our loss function is also a consistent surrogate for multiclass L2D, like Mozannar & Sontag's (2020). Our experiments verify that not only is our system calibrated, but this benefit comes at no cost to accuracy. Our model's accuracy is always comparable (and often superior) to Mozannar & Sontag's (2020) model's in tasks ranging from hate speech detection to galaxy classification to diagnosis of skin lesions.
Automatic detection of lesion load change in Multiple Sclerosis using convolutional neural networks with segmentation confidence
Apr 05, 2019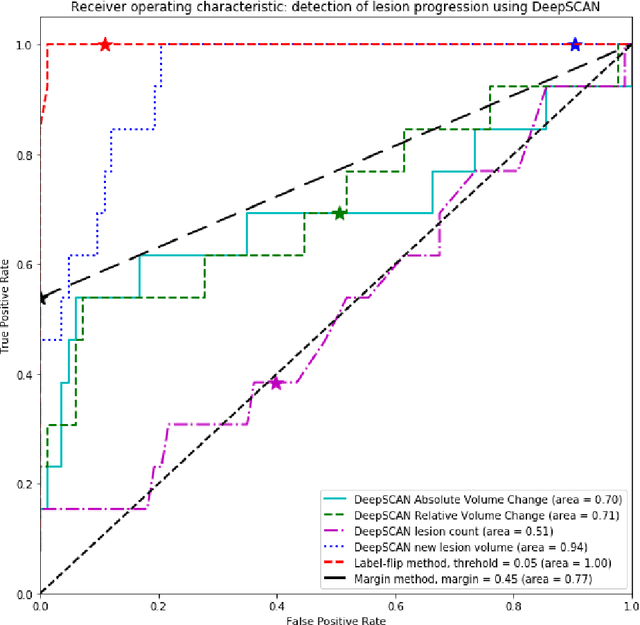
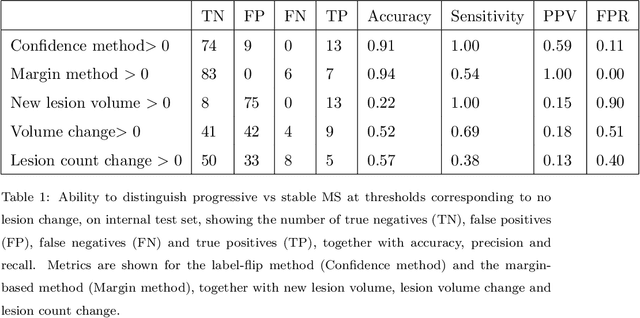
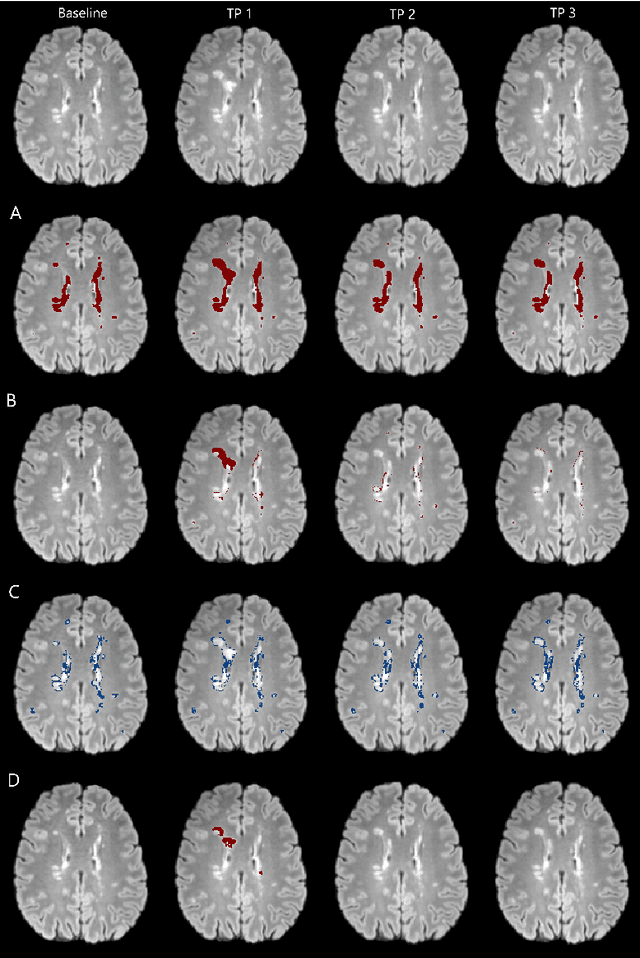
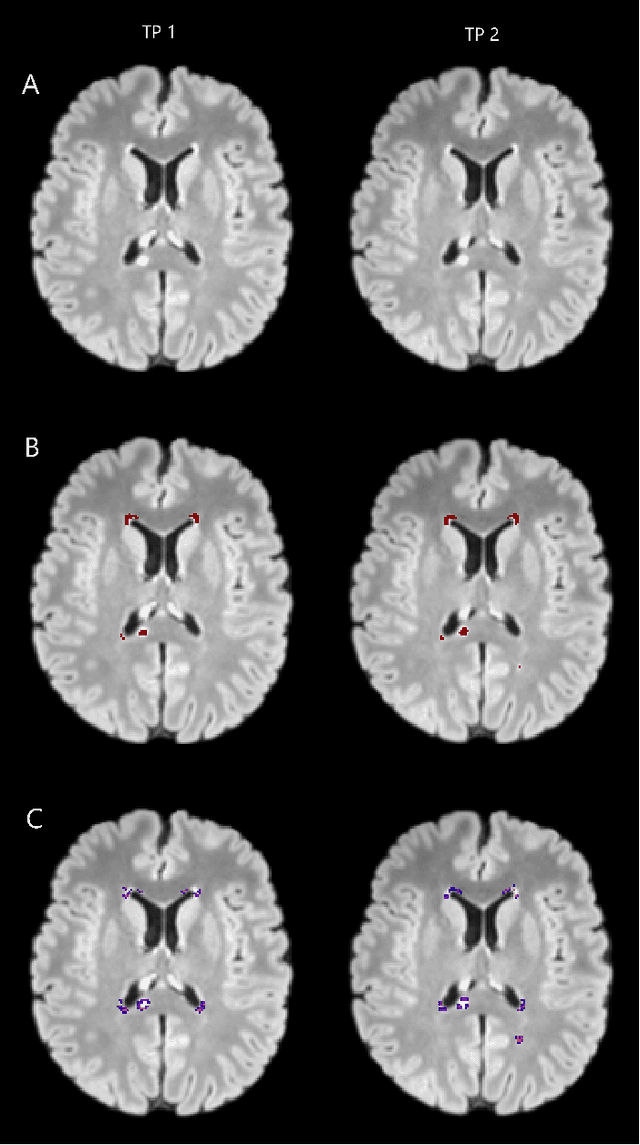
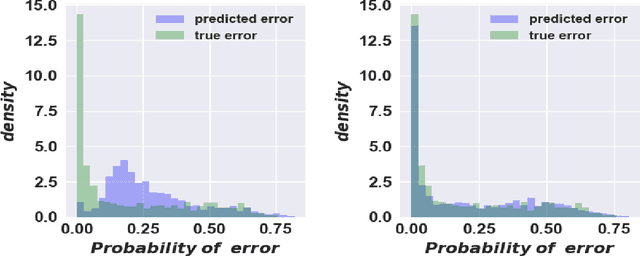
The detection of new or enlarged white-matter lesions in multiple sclerosis is a vital task in the monitoring of patients undergoing disease-modifying treatment for multiple sclerosis. However, the definition of 'new or enlarged' is not fixed, and it is known that lesion-counting is highly subjective, with high degree of inter- and intra-rater variability. Automated methods for lesion quantification hold the potential to make the detection of new and enlarged lesions consistent and repeatable. However, the majority of lesion segmentation algorithms are not evaluated for their ability to separate progressive from stable patients, despite this being a pressing clinical use-case. In this paper we show that change in volumetric measurements of lesion load alone is not a good method for performing this separation, even for highly performing segmentation methods. Instead, we propose a method for identifying lesion changes of high certainty, and establish on a dataset of longitudinal multiple sclerosis cases that this method is able to separate progressive from stable timepoints with a very high level of discrimination (AUC = 0.99), while changes in lesion volume are much less able to perform this separation (AUC = 0.71). Validation of the method on a second external dataset confirms that the method is able to generalize beyond the setting in which it was trained, achieving an accuracy of 83% in separating stable and progressive timepoints. Both lesion volume and count have previously been shown to be strong predictors of disease course across a population. However, we demonstrate that for individual patients, changes in these measures are not an adequate means of establishing no evidence of disease activity. Meanwhile, directly detecting tissue which changes, with high confidence, from non-lesion to lesion is a feasible methodology for identifying radiologically active patients.