 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Information-Theoretic Approach to Data Attribution
Apr 04, 2026Training Data Attribution (TDA) seeks to trace model predictions back to influential training examples, enhancing interpretability and safety. We formulate TDA as a Bayesian information-theoretic problem: subsets are scored by the information loss they induce - the entropy increase at a query when removed. This criterion credits examples for resolving predictive uncertainty rather than label noise. To scale to modern networks, we approximate information loss using a Gaussian Process surrogate built from tangent features. We show this aligns with classical influence scores for single-example attribution while promoting diversity for subsets. For even larger-scale retrieval, we relax to an information-gain objective and add a variance correction for scalable attribution in vector databases. Experiments show competitive performance on counterfactual sensitivity, ground-truth retrieval and coreset selection, showing that our method scales to modern architectures while bridging principled measures with practice.
Approximating Full Conformal Prediction for Neural Network Regression with Gauss-Newton Influence
Jul 27, 2025Uncertainty quantification is an important prerequisite for the deployment of deep learning models in safety-critical areas. Yet, this hinges on the uncertainty estimates being useful to the extent the prediction intervals are well-calibrated and sharp. In the absence of inherent uncertainty estimates (e.g. pretrained models predicting only point estimates), popular approaches that operate post-hoc include Laplace's method and split conformal prediction (split-CP). However, Laplace's method can be miscalibrated when the model is misspecified and split-CP requires sample splitting, and thus comes at the expense of statistical efficiency. In this work, we construct prediction intervals for neural network regressors post-hoc without held-out data. This is achieved by approximating the full conformal prediction method (full-CP). Whilst full-CP nominally requires retraining the model for every test point and candidate label, we propose to train just once and locally perturb model parameters using Gauss-Newton influence to approximate the effect of retraining. Coupled with linearization of the network, we express the absolute residual nonconformity score as a piecewise linear function of the candidate label allowing for an efficient procedure that avoids the exhaustive search over the output space. On standard regression benchmarks and bounding box localization, we show the resulting prediction intervals are locally-adaptive and often tighter than those of split-CP.
Learning to Defer to a Population: A Meta-Learning Approach
Mar 05, 2024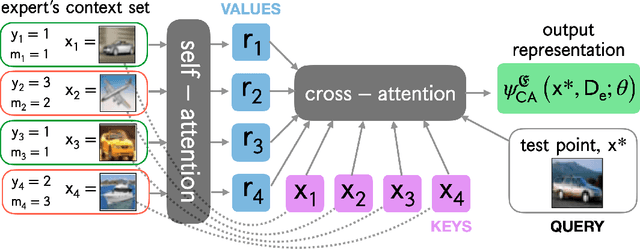



The learning to defer (L2D) framework allows autonomous systems to be safe and robust by allocating difficult decisions to a human expert. All existing work on L2D assumes that each expert is well-identified, and if any expert were to change, the system should be re-trained. In this work, we alleviate this constraint, formulating an L2D system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert's abilities. In the experiments, we validate our methods on image recognition, traffic sign detection, and skin lesion diagnosis benchmarks.
The Memory Perturbation Equation: Understanding Model's Sensitivity to Data
Oct 30, 2023



Understanding model's sensitivity to its training data is crucial but can also be challenging and costly, especially during training. To simplify such issues, we present the Memory-Perturbation Equation (MPE) which relates model's sensitivity to perturbation in its training data. Derived using Bayesian principles, the MPE unifies existing sensitivity measures, generalizes them to a wide-variety of models and algorithms, and unravels useful properties regarding sensitivities. Our empirical results show that sensitivity estimates obtained during training can be used to faithfully predict generalization on unseen test data. The proposed equation is expected to be useful for future research on robust and adaptive learning.
Exploiting Inferential Structure in Neural Processes
Jun 27, 2023Neural Processes (NPs) are appealing due to their ability to perform fast adaptation based on a context set. This set is encoded by a latent variable, which is often assumed to follow a simple distribution. However, in real-word settings, the context set may be drawn from richer distributions having multiple modes, heavy tails, etc. In this work, we provide a framework that allows NPs' latent variable to be given a rich prior defined by a graphical model. These distributional assumptions directly translate into an appropriate aggregation strategy for the context set. Moreover, we describe a message-passing procedure that still allows for end-to-end optimization with stochastic gradients. We demonstrate the generality of our framework by using mixture and Student-t assumptions that yield improvements in function modelling and test-time robustness.
Learning the optimal state-feedback via supervised imitation learning
Jan 07, 2019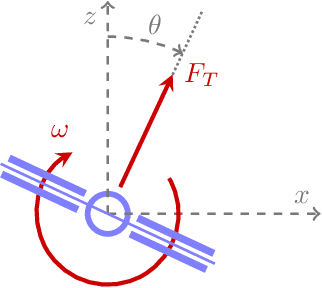

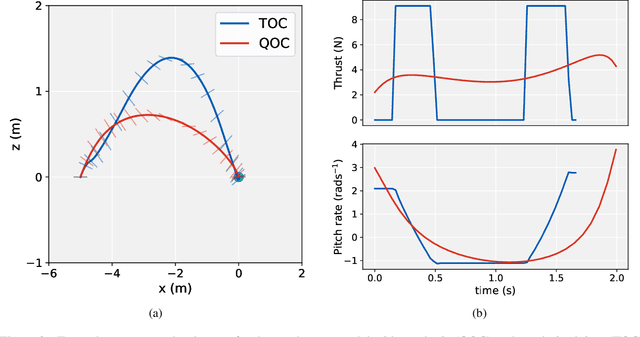

Imitation learning is a control design paradigm that seeks to learn a control policy reproducing demonstrations from experts. By substituting expert's demonstrations for optimal behaviours, the same paradigm leads to the design of control policies closely approximating the optimal state-feedback. This approach requires training a machine learning algorithm (in our case deep neural networks) directly on state-control pairs originating from optimal trajectories. We have shown in previous work that, when restricted to relatively low-dimensional state and control spaces, this approach is very successful in several deterministic, non-linear problems in continuous-time. In this work, we refine our previous studies using as test case a simple quadcopter model with quadratic and time-optimal objective functions. We describe in detail the best learning pipeline we have developed and that is able to approximate via deep neural networks the state-feedback map to a very high accuracy. We introduce the use of the softplus activation function in the hidden units showing how it results in a smoother control profile whilst retaining the benefits of ReLUs. We show how to evaluate the optimality of the trained state-feedback, and find that already with two layers the objective function reached and its optimal value differ by less than one percent. We later consider also an additional metric linked to the system asymptotic behaviour - time taken to converge to the policy's fixed point. With respect to these metrics, we show that improvements in the mean average error do not necessarily correspond to significant improvements.
On the stability analysis of optimal state feedbacks as represented by deep neural models
Dec 07, 2018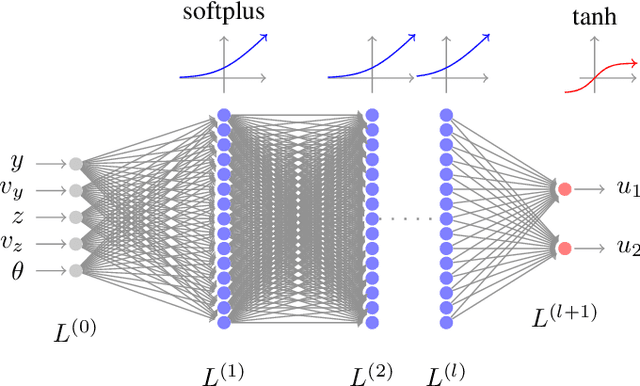
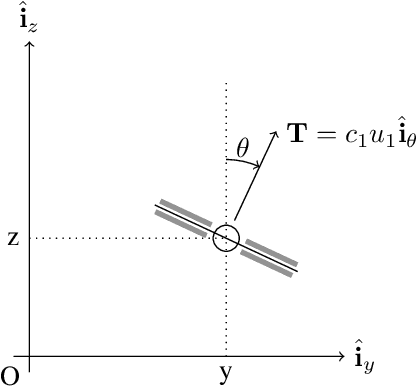
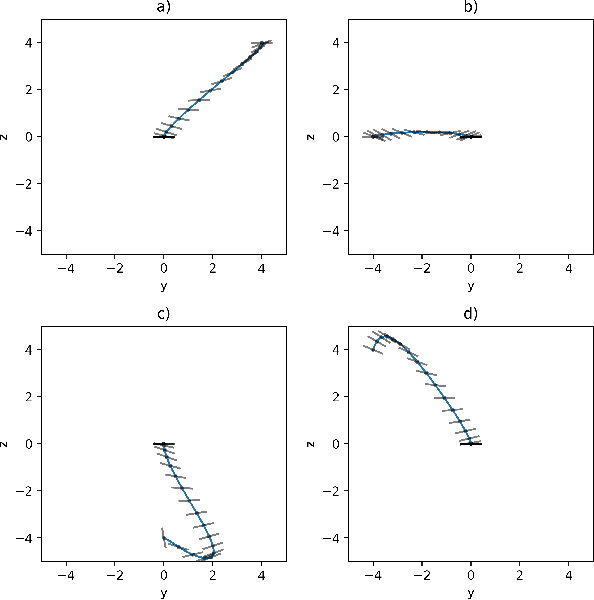
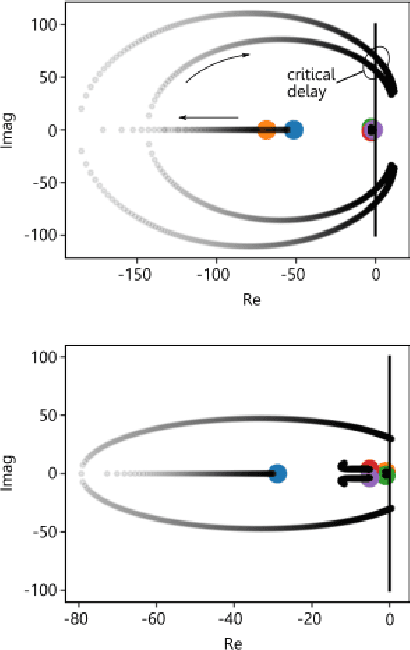
Research has shown how the optimal feedback control of several non linear systems of interest in aerospace applications can be represented by deep neural architectures and trained using techniques including imitation learning, reinforcement learning and evolutionary algorithms. Such deep architectures are here also referred to as Guidance and Control Networks, or G&CNETs. It is difficult to provide theoretical proofs on the control stability of such neural control architectures in general, and G&CNETs in particular, to perturbations, time delays or model uncertainties or to compute stability margins and trace them back to the network training process or to its architecture. In most cases the analysis of the trained network is performed via Monte Carlo experiments and practitioners renounce to any formal guarantee. This lack of validation naturally leads to scepticism especially in cases where safety and validation are of paramount importance such as is the case, for example, in the automotive or space industry. In an attempt to narrow the gap between deep learning research and control theory, we propose a new methodology based on differential algebra and automated differentiation to obtain formal guarantees on the behaviour of neural based control systems.
Machine learning and evolutionary techniques in interplanetary trajectory design
Sep 28, 2018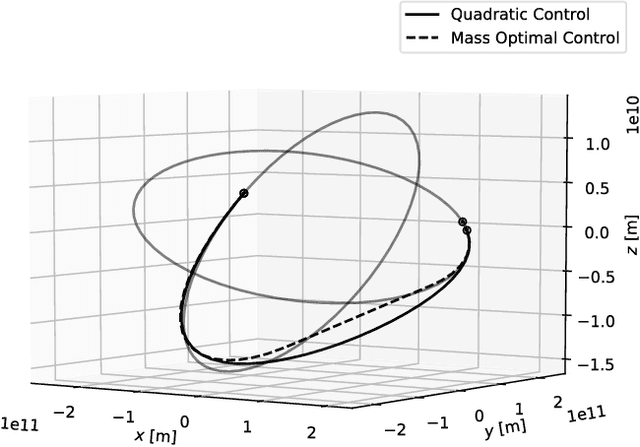
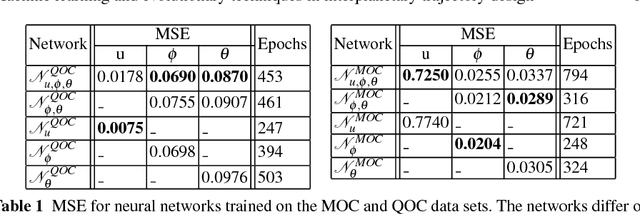
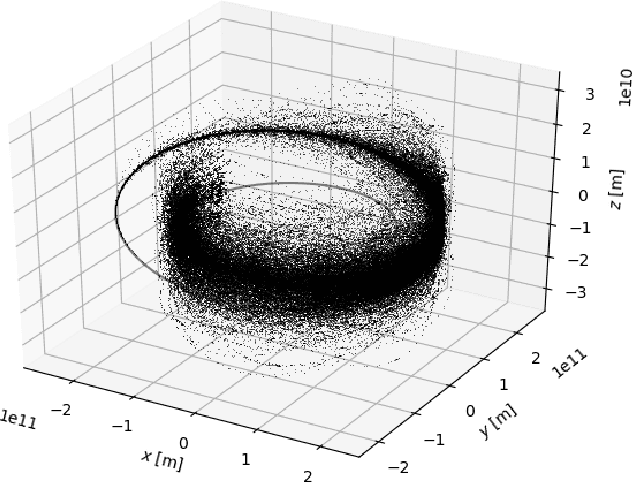
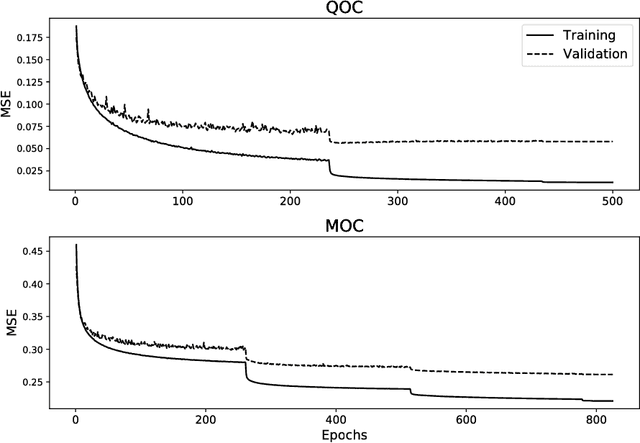
After providing a brief historical overview on the synergies between artificial intelligence research, in the areas of evolutionary computations and machine learning, and the optimal design of interplanetary trajectories, we propose and study the use of deep artificial neural networks to represent, on-board, the optimal guidance profile of an interplanetary mission. The results, limited to the chosen test case of an Earth-Mars orbital transfer, extend the findings made previously for landing scenarios and quadcopter dynamics, opening a new research area in interplanetary trajectory planning.