 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the optimal state-feedback via supervised imitation learning
Paper and Code
Jan 07, 2019

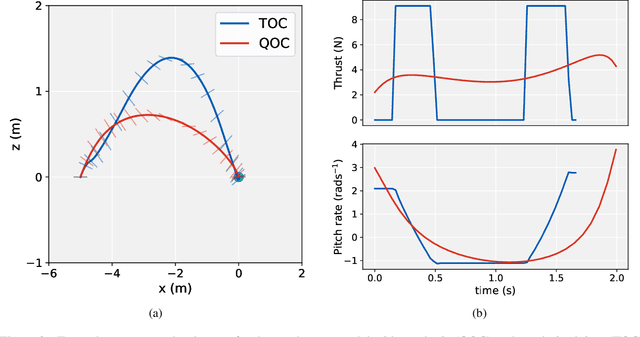

Imitation learning is a control design paradigm that seeks to learn a control policy reproducing demonstrations from experts. By substituting expert's demonstrations for optimal behaviours, the same paradigm leads to the design of control policies closely approximating the optimal state-feedback. This approach requires training a machine learning algorithm (in our case deep neural networks) directly on state-control pairs originating from optimal trajectories. We have shown in previous work that, when restricted to relatively low-dimensional state and control spaces, this approach is very successful in several deterministic, non-linear problems in continuous-time. In this work, we refine our previous studies using as test case a simple quadcopter model with quadratic and time-optimal objective functions. We describe in detail the best learning pipeline we have developed and that is able to approximate via deep neural networks the state-feedback map to a very high accuracy. We introduce the use of the softplus activation function in the hidden units showing how it results in a smoother control profile whilst retaining the benefits of ReLUs. We show how to evaluate the optimality of the trained state-feedback, and find that already with two layers the objective function reached and its optimal value differ by less than one percent. We later consider also an additional metric linked to the system asymptotic behaviour - time taken to converge to the policy's fixed point. With respect to these metrics, we show that improvements in the mean average error do not necessarily correspond to significant improvements.