 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Calibration in Multi-Distribution Learning
Dec 18, 2024
Modern challenges of robustness, fairness, and decision-making in machine learning have led to the formulation of multi-distribution learning (MDL) frameworks in which a predictor is optimized across multiple distributions. We study the calibration properties of MDL to better understand how the predictor performs uniformly across the multiple distributions. Through classical results on decomposing proper scoring losses, we first derive the Bayes optimal rule for MDL, demonstrating that it maximizes the generalized entropy of the associated loss function. Our analysis reveals that while this approach ensures minimal worst-case loss, it can lead to non-uniform calibration errors across the multiple distributions and there is an inherent calibration-refinement trade-off, even at Bayes optimality. Our results highlight a critical limitation: despite the promise of MDL, one must use caution when designing predictors tailored to multiple distributions so as to minimize disparity.
Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Representation Learning
Apr 11, 2024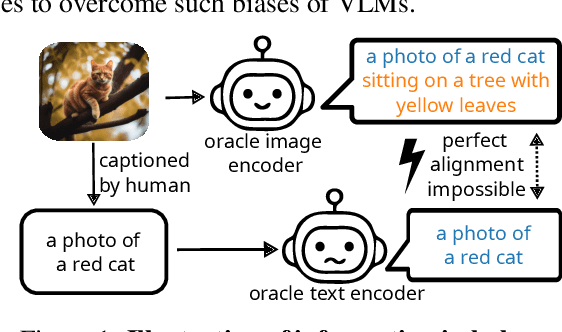



Contrastive vision-language models like CLIP have gained popularity for their versatile applicable learned representations in various downstream tasks. Despite their successes in some tasks, like zero-shot image recognition, they also perform surprisingly poor on other tasks, like attribute detection. Previous work has attributed these challenges to the modality gap, a separation of image and text in the shared representation space, and a bias towards objects over other factors, such as attributes. In this work we investigate both phenomena. We find that only a few embedding dimensions drive the modality gap. Further, we propose a measure for object bias and find that object bias does not lead to worse performance on other concepts, such as attributes. But what leads to the emergence of the modality gap and object bias? To answer this question we carefully designed an experimental setting which allows us to control the amount of shared information between the modalities. This revealed that the driving factor behind both, the modality gap and the object bias, is the information imbalance between images and captions.
Eureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems
Oct 19, 2023



In this work, we study rapid, step-wise improvements of the loss in transformers when being confronted with multi-step decision tasks. We found that transformers struggle to learn the intermediate tasks, whereas CNNs have no such issue on the tasks we studied. When transformers learn the intermediate task, they do this rapidly and unexpectedly after both training and validation loss saturated for hundreds of epochs. We call these rapid improvements Eureka-moments, since the transformer appears to suddenly learn a previously incomprehensible task. Similar leaps in performance have become known as Grokking. In contrast to Grokking, for Eureka-moments, both the validation and the training loss saturate before rapidly improving. We trace the problem back to the Softmax function in the self-attention block of transformers and show ways to alleviate the problem. These fixes improve training speed. The improved models reach 95% of the baseline model in just 20% of training steps while having a much higher likelihood to learn the intermediate task, lead to higher final accuracy and are more robust to hyper-parameters.
Zero-Shot Visual Classification with Guided Cropping
Sep 12, 2023Pretrained vision-language models, such as CLIP, show promising zero-shot performance across a wide variety of datasets. For closed-set classification tasks, however, there is an inherent limitation: CLIP image encoders are typically designed to extract generic image-level features that summarize superfluous or confounding information for the target tasks. This results in degradation of classification performance, especially when objects of interest cover small areas of input images. In this work, we propose CLIP with Guided Cropping (GC-CLIP), where we use an off-the-shelf zero-shot object detection model in a preprocessing step to increase focus of zero-shot classifier to the object of interest and minimize influence of extraneous image regions. We empirically show that our approach improves zero-shot classification results across architectures and datasets, favorably for small objects.
Multi-Attribute Open Set Recognition
Aug 14, 2022
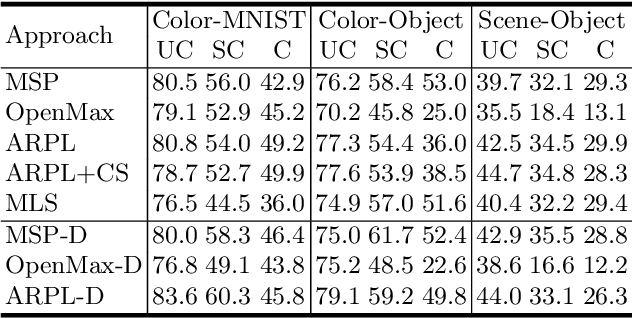
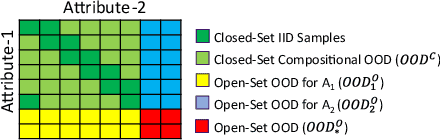
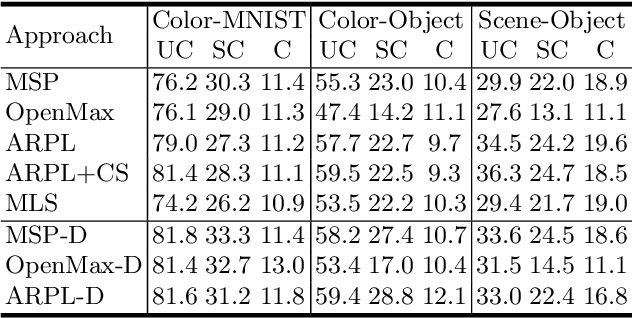
Open Set Recognition (OSR) extends image classification to an open-world setting, by simultaneously classifying known classes and identifying unknown ones. While conventional OSR approaches can detect Out-of-Distribution (OOD) samples, they cannot provide explanations indicating which underlying visual attribute(s) (e.g., shape, color or background) cause a specific sample to be unknown. In this work, we introduce a novel problem setup that generalizes conventional OSR to a multi-attribute setting, where multiple visual attributes are simultaneously recognized. Here, OOD samples can be not only identified but also categorized by their unknown attribute(s). We propose simple extensions of common OSR baselines to handle this novel scenario. We show that these baselines are vulnerable to shortcuts when spurious correlations exist in the training dataset. This leads to poor OOD performance which, according to our experiments, is mainly due to unintended cross-attribute correlations of the predicted confidence scores. We provide an empirical evidence showing that this behavior is consistent across different baselines on both synthetic and real world datasets.
Overcoming Shortcut Learning in a Target Domain by Generalizing Basic Visual Factors from a Source Domain
Jul 20, 2022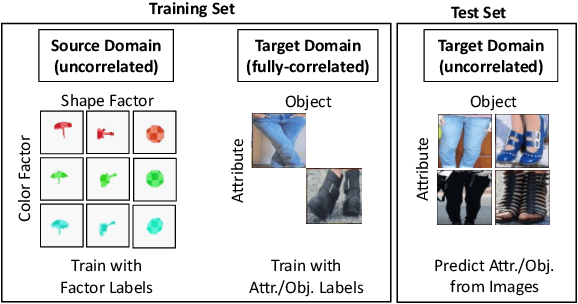
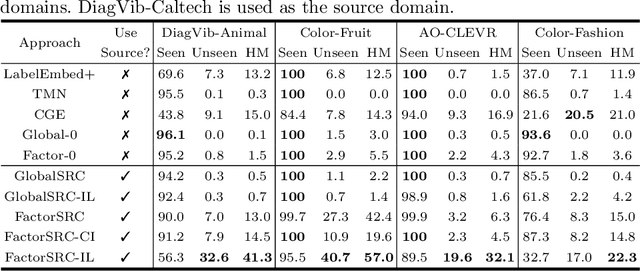
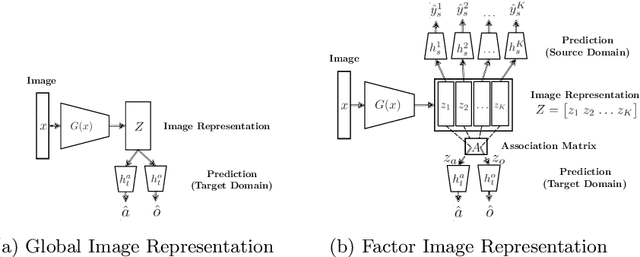
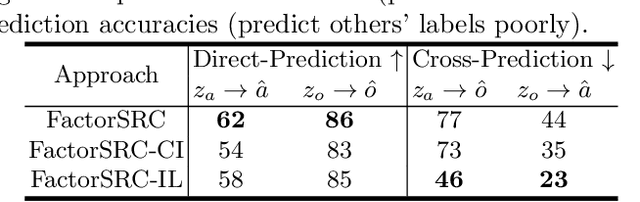
Shortcut learning occurs when a deep neural network overly relies on spurious correlations in the training dataset in order to solve downstream tasks. Prior works have shown how this impairs the compositional generalization capability of deep learning models. To address this problem, we propose a novel approach to mitigate shortcut learning in uncontrolled target domains. Our approach extends the training set with an additional dataset (the source domain), which is specifically designed to facilitate learning independent representations of basic visual factors. We benchmark our idea on synthetic target domains where we explicitly control shortcut opportunities as well as real-world target domains. Furthermore, we analyze the effect of different specifications of the source domain and the network architecture on compositional generalization. Our main finding is that leveraging data from a source domain is an effective way to mitigate shortcut learning. By promoting independence across different factors of variation in the learned representations, networks can learn to consider only predictive factors and ignore potential shortcut factors during inference.
Contrasting quadratic assignments for set-based representation learning
May 31, 2022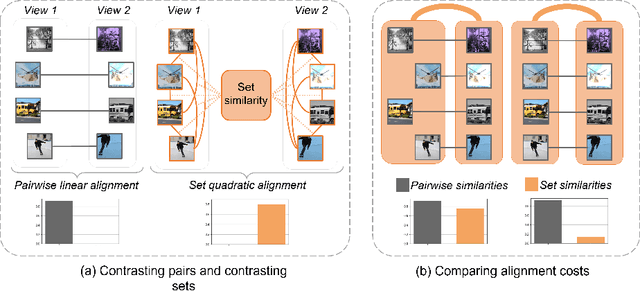

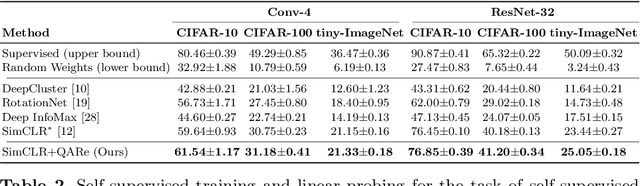
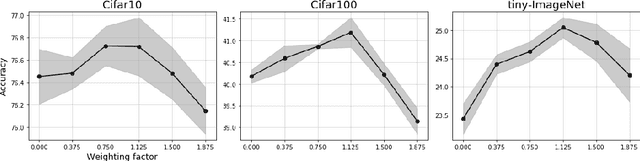
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.
DiagViB-6: A Diagnostic Benchmark Suite for Vision Models in the Presence of Shortcut and Generalization Opportunities
Aug 12, 2021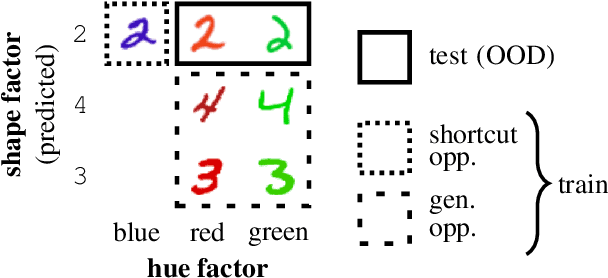


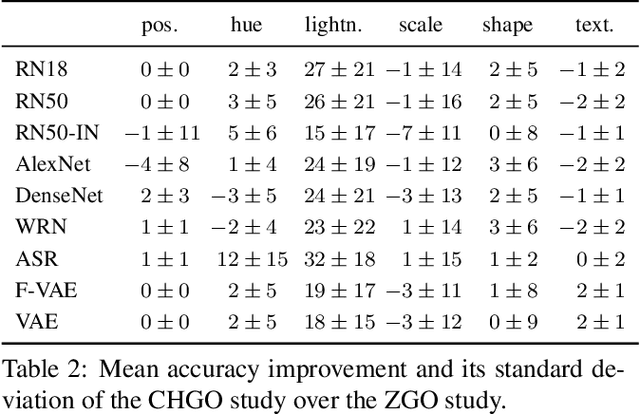
Common deep neural networks (DNNs) for image classification have been shown to rely on shortcut opportunities (SO) in the form of predictive and easy-to-represent visual factors. This is known as shortcut learning and leads to impaired generalization. In this work, we show that common DNNs also suffer from shortcut learning when predicting only basic visual object factors of variation (FoV) such as shape, color, or texture. We argue that besides shortcut opportunities, generalization opportunities (GO) are also an inherent part of real-world vision data and arise from partial independence between predicted classes and FoVs. We also argue that it is necessary for DNNs to exploit GO to overcome shortcut learning. Our core contribution is to introduce the Diagnostic Vision Benchmark suite DiagViB-6, which includes datasets and metrics to study a network's shortcut vulnerability and generalization capability for six independent FoV. In particular, DiagViB-6 allows controlling the type and degree of SO and GO in a dataset. We benchmark a wide range of popular vision architectures and show that they can exploit GO only to a limited extent.
EML Online Speech Activity Detection for the Fearless Steps Challenge Phase-III
Jun 21, 2021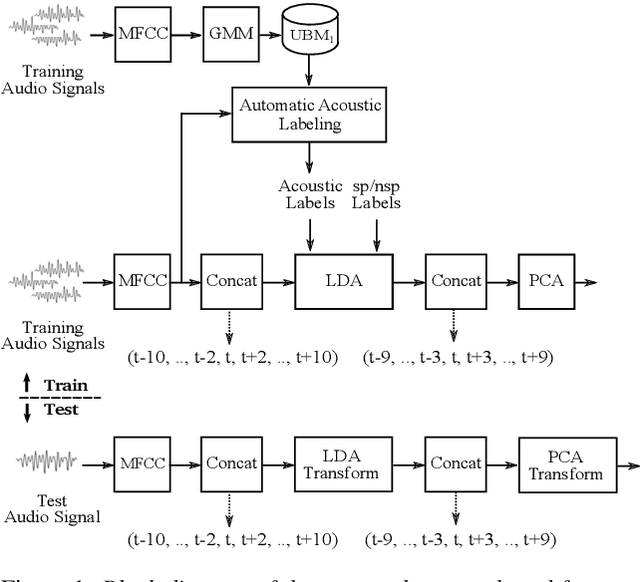

Speech Activity Detection (SAD), locating speech segments within an audio recording, is a main part of most speech technology applications. Robust SAD is usually more difficult in noisy conditions with varying signal-to-noise ratios (SNR). The Fearless Steps challenge has recently provided such data from the NASA Apollo-11 mission for different speech processing tasks including SAD. Most audio recordings are degraded by different kinds and levels of noise varying within and between channels. This paper describes the EML online algorithm for the most recent phase of this challenge. The proposed algorithm can be trained both in a supervised and unsupervised manner and assigns speech and non-speech labels at runtime approximately every 0.1 sec. The experimental results show a competitive accuracy on both development and evaluation datasets with a real-time factor of about 0.002 using a single CPU machine.
Does enhanced shape bias improve neural network robustness to common corruptions?
Apr 20, 2021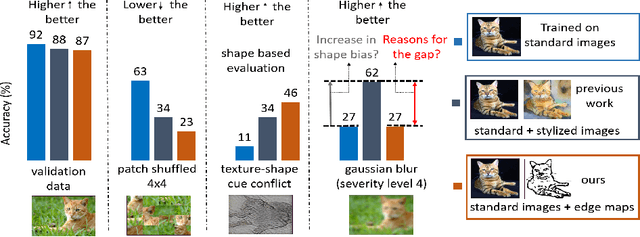
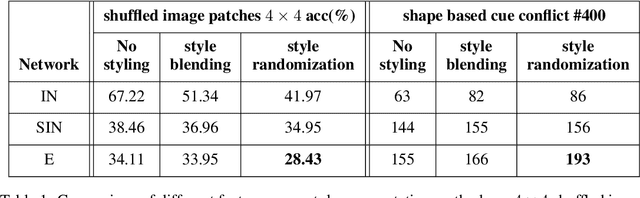

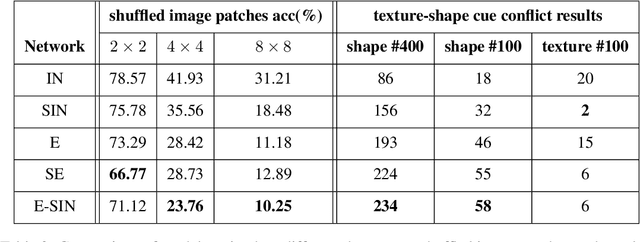
Convolutional neural networks (CNNs) learn to extract representations of complex features, such as object shapes and textures to solve image recognition tasks. Recent work indicates that CNNs trained on ImageNet are biased towards features that encode textures and that these alone are sufficient to generalize to unseen test data from the same distribution as the training data but often fail to generalize to out-of-distribution data. It has been shown that augmenting the training data with different image styles decreases this texture bias in favor of increased shape bias while at the same time improving robustness to common corruptions, such as noise and blur. Commonly, this is interpreted as shape bias increasing corruption robustness. However, this relationship is only hypothesized. We perform a systematic study of different ways of composing inputs based on natural images, explicit edge information, and stylization. While stylization is essential for achieving high corruption robustness, we do not find a clear correlation between shape bias and robustness. We conclude that the data augmentation caused by style-variation accounts for the improved corruption robustness and increased shape bias is only a byproduct.