 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attribute Open Set Recognition
Aug 14, 2022
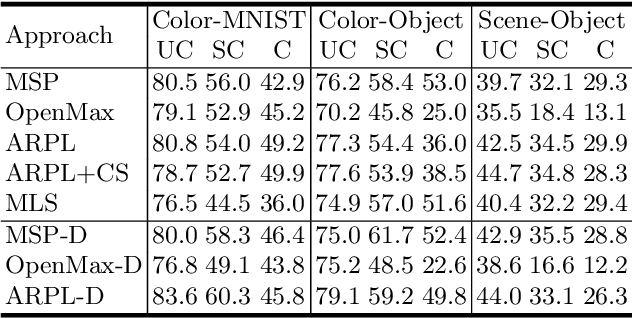
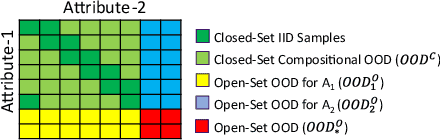
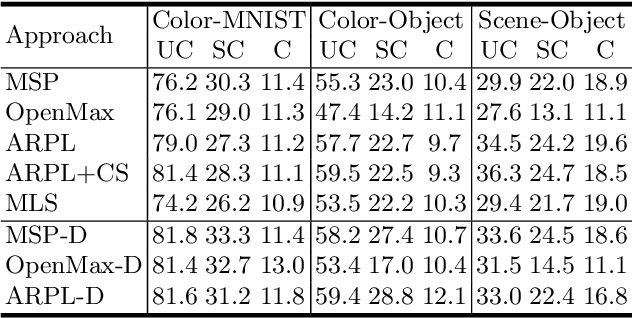
Open Set Recognition (OSR) extends image classification to an open-world setting, by simultaneously classifying known classes and identifying unknown ones. While conventional OSR approaches can detect Out-of-Distribution (OOD) samples, they cannot provide explanations indicating which underlying visual attribute(s) (e.g., shape, color or background) cause a specific sample to be unknown. In this work, we introduce a novel problem setup that generalizes conventional OSR to a multi-attribute setting, where multiple visual attributes are simultaneously recognized. Here, OOD samples can be not only identified but also categorized by their unknown attribute(s). We propose simple extensions of common OSR baselines to handle this novel scenario. We show that these baselines are vulnerable to shortcuts when spurious correlations exist in the training dataset. This leads to poor OOD performance which, according to our experiments, is mainly due to unintended cross-attribute correlations of the predicted confidence scores. We provide an empirical evidence showing that this behavior is consistent across different baselines on both synthetic and real world datasets.
Overcoming Shortcut Learning in a Target Domain by Generalizing Basic Visual Factors from a Source Domain
Jul 20, 2022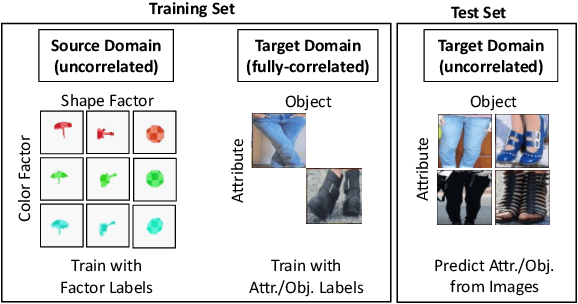
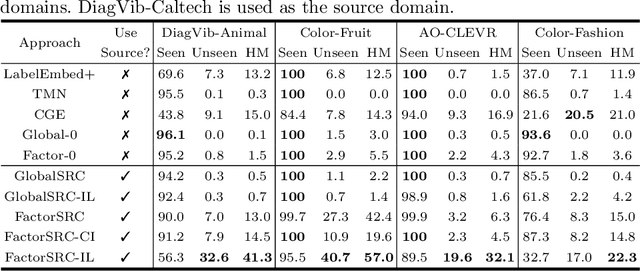
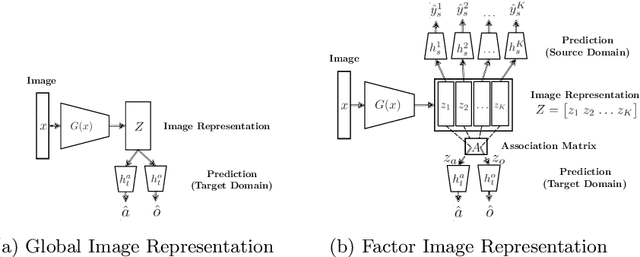
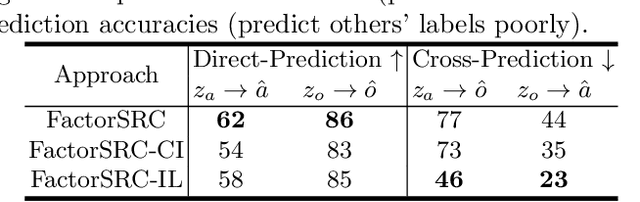
Shortcut learning occurs when a deep neural network overly relies on spurious correlations in the training dataset in order to solve downstream tasks. Prior works have shown how this impairs the compositional generalization capability of deep learning models. To address this problem, we propose a novel approach to mitigate shortcut learning in uncontrolled target domains. Our approach extends the training set with an additional dataset (the source domain), which is specifically designed to facilitate learning independent representations of basic visual factors. We benchmark our idea on synthetic target domains where we explicitly control shortcut opportunities as well as real-world target domains. Furthermore, we analyze the effect of different specifications of the source domain and the network architecture on compositional generalization. Our main finding is that leveraging data from a source domain is an effective way to mitigate shortcut learning. By promoting independence across different factors of variation in the learned representations, networks can learn to consider only predictive factors and ignore potential shortcut factors during inference.
Generative diffeomorphic atlas construction from brain and spinal cord MRI data
Jul 05, 2017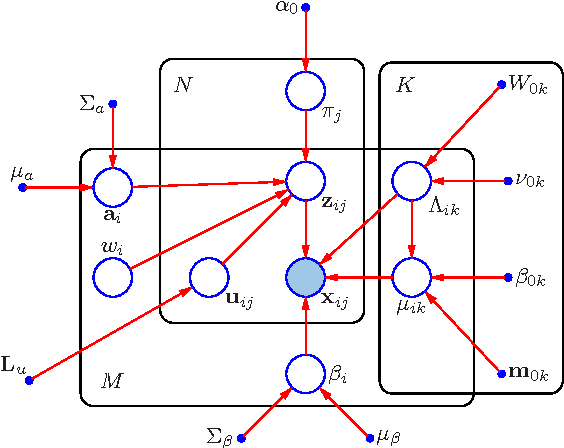


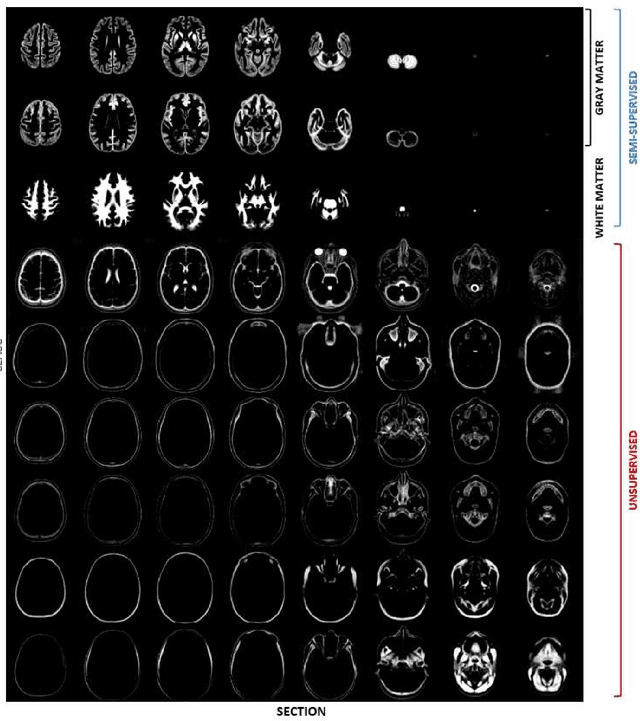
In this paper we will focus on the potential and on the challenges associated with the development of an integrated brain and spinal cord modelling framework for processing MR neuroimaging data. The aim of the work is to explore how a hierarchical generative model of imaging data, which captures simultaneously the distribution of signal intensities and the variability of anatomical shapes across a large population of subjects, can serve to quantitatively investigate, in vivo, the morphology of the central nervous system (CNS). In fact, the generality of the proposed Bayesian approach, which extends the hierarchical structure of the segmentation method implemented in the SPM software, allows processing simultaneously information relative to different compartments of the CNS, namely the brain and the spinal cord, without having to resort to organ specific solutions (e.g. tools optimised only for the brain, or only for the spinal cord), which are inevitably harder to integrate and generalise.