 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Visual Classification with Guided Cropping
Sep 12, 2023Pretrained vision-language models, such as CLIP, show promising zero-shot performance across a wide variety of datasets. For closed-set classification tasks, however, there is an inherent limitation: CLIP image encoders are typically designed to extract generic image-level features that summarize superfluous or confounding information for the target tasks. This results in degradation of classification performance, especially when objects of interest cover small areas of input images. In this work, we propose CLIP with Guided Cropping (GC-CLIP), where we use an off-the-shelf zero-shot object detection model in a preprocessing step to increase focus of zero-shot classifier to the object of interest and minimize influence of extraneous image regions. We empirically show that our approach improves zero-shot classification results across architectures and datasets, favorably for small objects.
Multi-Attribute Open Set Recognition
Aug 14, 2022
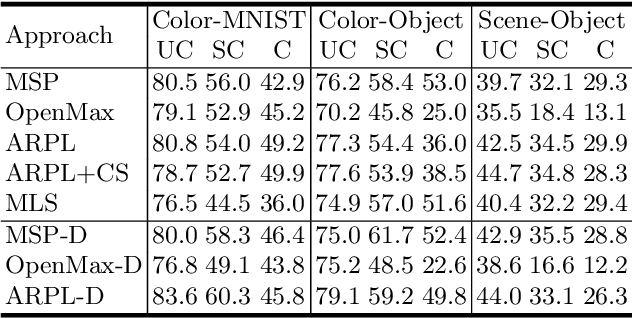
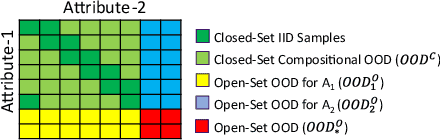
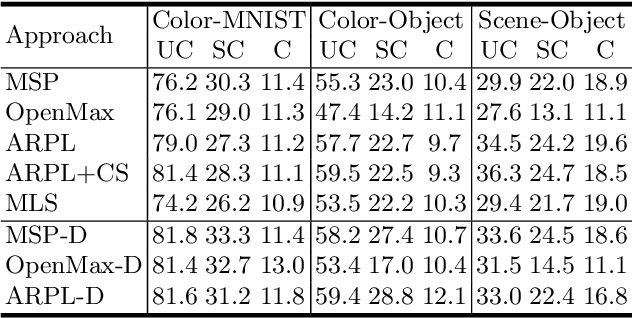
Open Set Recognition (OSR) extends image classification to an open-world setting, by simultaneously classifying known classes and identifying unknown ones. While conventional OSR approaches can detect Out-of-Distribution (OOD) samples, they cannot provide explanations indicating which underlying visual attribute(s) (e.g., shape, color or background) cause a specific sample to be unknown. In this work, we introduce a novel problem setup that generalizes conventional OSR to a multi-attribute setting, where multiple visual attributes are simultaneously recognized. Here, OOD samples can be not only identified but also categorized by their unknown attribute(s). We propose simple extensions of common OSR baselines to handle this novel scenario. We show that these baselines are vulnerable to shortcuts when spurious correlations exist in the training dataset. This leads to poor OOD performance which, according to our experiments, is mainly due to unintended cross-attribute correlations of the predicted confidence scores. We provide an empirical evidence showing that this behavior is consistent across different baselines on both synthetic and real world datasets.
Overcoming Shortcut Learning in a Target Domain by Generalizing Basic Visual Factors from a Source Domain
Jul 20, 2022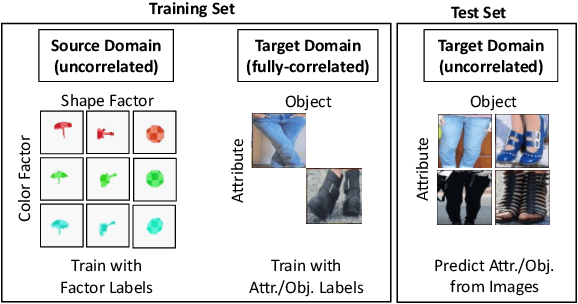
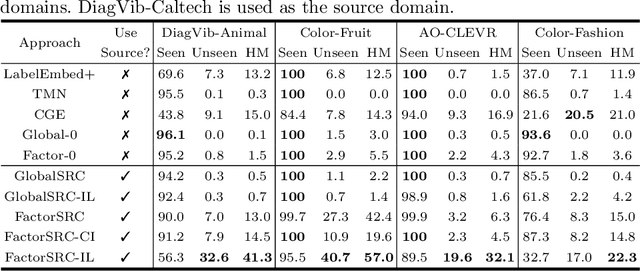
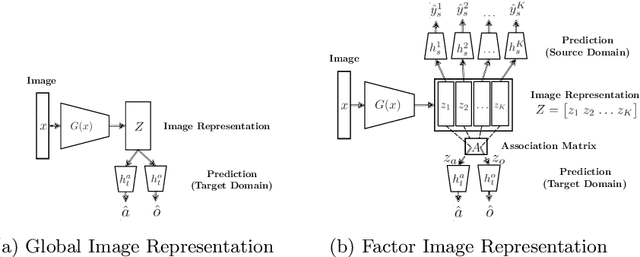
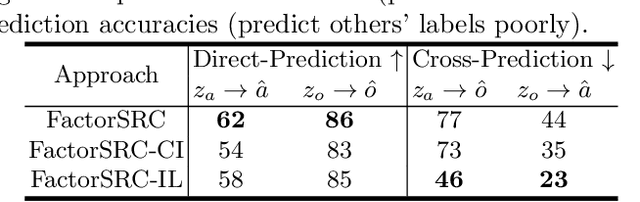
Shortcut learning occurs when a deep neural network overly relies on spurious correlations in the training dataset in order to solve downstream tasks. Prior works have shown how this impairs the compositional generalization capability of deep learning models. To address this problem, we propose a novel approach to mitigate shortcut learning in uncontrolled target domains. Our approach extends the training set with an additional dataset (the source domain), which is specifically designed to facilitate learning independent representations of basic visual factors. We benchmark our idea on synthetic target domains where we explicitly control shortcut opportunities as well as real-world target domains. Furthermore, we analyze the effect of different specifications of the source domain and the network architecture on compositional generalization. Our main finding is that leveraging data from a source domain is an effective way to mitigate shortcut learning. By promoting independence across different factors of variation in the learned representations, networks can learn to consider only predictive factors and ignore potential shortcut factors during inference.
Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
Mar 25, 2022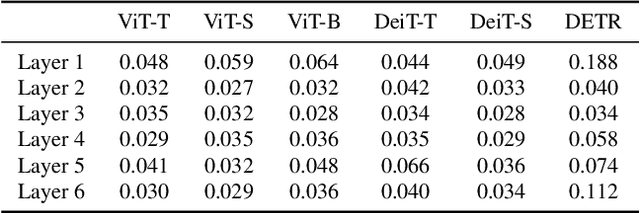
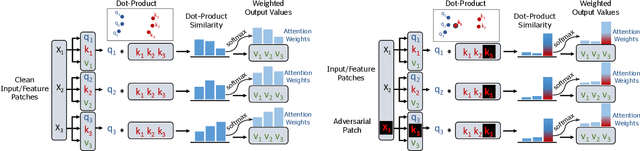
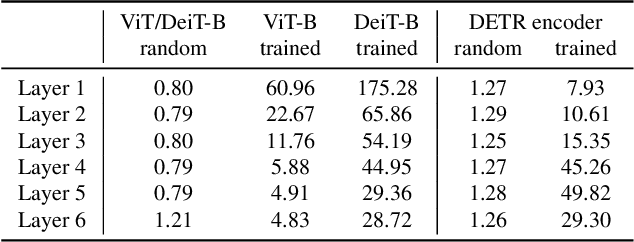
Neural architectures based on attention such as vision transformers are revolutionizing image recognition. Their main benefit is that attention allows reasoning about all parts of a scene jointly. In this paper, we show how the global reasoning of (scaled) dot-product attention can be the source of a major vulnerability when confronted with adversarial patch attacks. We provide a theoretical understanding of this vulnerability and relate it to an adversary's ability to misdirect the attention of all queries to a single key token under the control of the adversarial patch. We propose novel adversarial objectives for crafting adversarial patches which target this vulnerability explicitly. We show the effectiveness of the proposed patch attacks on popular image classification (ViTs and DeiTs) and object detection models (DETR). We find that adversarial patches occupying 0.5% of the input can lead to robust accuracies as low as 0% for ViT on ImageNet, and reduce the mAP of DETR on MS COCO to less than 3%.
Grid Saliency for Context Explanations of Semantic Segmentation
Jul 30, 2019
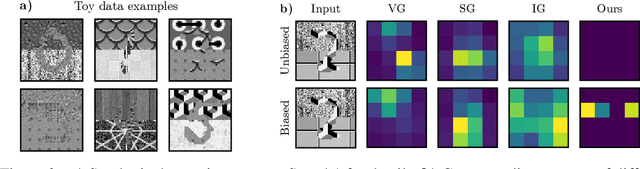
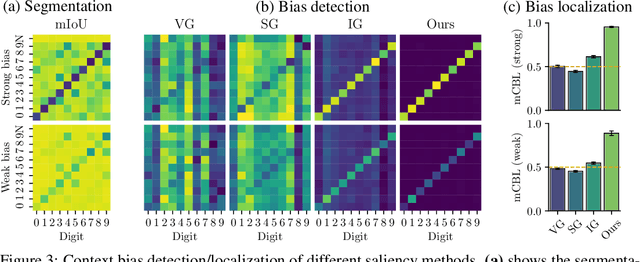
Recently, there has been a growing interest in developing saliency methods that provide visual explanations of network predictions. Still, the usability of existing methods is limited to image classification models. To overcome this limitation, we extend the existing approaches to generate grid saliencies, which provide spatially coherent visual explanations for (pixel-level) dense prediction networks. As the proposed grid saliency allows to spatially disentangle the object and its context, we specifically explore its potential to produce context explanations for semantic segmentation networks, discovering which context most influences the class predictions inside a target object area. We investigate the effectiveness of grid saliency on a synthetic dataset with an artificially induced bias between objects and their context as well as on the real-world Cityscapes dataset using state-of-the-art segmentation networks. Our results show that grid saliency can be successfully used to provide easily interpretable context explanations and, moreover, can be employed for detecting and localizing contextual biases present in the data.