 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Propagation on Continuous-Time Dynamic Graphs
Jun 04, 2024



Learning Continuous-Time Dynamic Graphs (C-TDGs) requires accurately modeling spatio-temporal information on streams of irregularly sampled events. While many methods have been proposed recently, we find that most message passing-, recurrent- or self-attention-based methods perform poorly on long-range tasks. These tasks require correlating information that occurred "far" away from the current event, either spatially (higher-order node information) or along the time dimension (events occurred in the past). To address long-range dependencies, we introduce Continuous-Time Graph Anti-Symmetric Network (CTAN). Grounded within the ordinary differential equations framework, our method is designed for efficient propagation of information. In this paper, we show how CTAN's (i) long-range modeling capabilities are substantiated by theoretical findings and how (ii) its empirical performance on synthetic long-range benchmarks and real-world benchmarks is superior to other methods. Our results motivate CTAN's ability to propagate long-range information in C-TDGs as well as the inclusion of long-range tasks as part of temporal graph models evaluation.
Learning-Based Link Anomaly Detection in Continuous-Time Dynamic Graphs
May 28, 2024Anomaly detection in continuous-time dynamic graphs is an emerging field yet under-explored in the context of learning-based approaches. In this paper, we pioneer structured analyses of link-level anomalies and graph representation learning for identifying anomalous links in these graphs. First, we introduce a fine-grain taxonomy for edge-level anomalies leveraging structural, temporal, and contextual graph properties. We present a method for generating and injecting such typed anomalies into graphs. Next, we introduce a novel method to generate continuous-time dynamic graphs with consistent patterns across time, structure, and context. To allow temporal graph methods to learn the link anomaly detection task, we extend the generic link prediction setting by: (1) conditioning link existence on contextual edge attributes; and (2) refining the training regime to accommodate diverse perturbations in the negative edge sampler. Building on this, we benchmark methods for anomaly detection. Comprehensive experiments on synthetic and real-world datasets -- featuring synthetic and labeled organic anomalies and employing six state-of-the-art learning methods -- validate our taxonomy and generation processes for anomalies and benign graphs, as well as our approach to adapting link prediction methods for anomaly detection. Our results further reveal that different learning methods excel in capturing different aspects of graph normality and detecting different types of anomalies. We conclude with a comprehensive list of findings highlighting opportunities for future research.
GCNH: A Simple Method For Representation Learning On Heterophilous Graphs
Apr 21, 2023Graph Neural Networks (GNNs) are well-suited for learning on homophilous graphs, i.e., graphs in which edges tend to connect nodes of the same type. Yet, achievement of consistent GNN performance on heterophilous graphs remains an open research problem. Recent works have proposed extensions to standard GNN architectures to improve performance on heterophilous graphs, trading off model simplicity for prediction accuracy. However, these models fail to capture basic graph properties, such as neighborhood label distribution, which are fundamental for learning. In this work, we propose GCN for Heterophily (GCNH), a simple yet effective GNN architecture applicable to both heterophilous and homophilous scenarios. GCNH learns and combines separate representations for a node and its neighbors, using one learned importance coefficient per layer to balance the contributions of center nodes and neighborhoods. We conduct extensive experiments on eight real-world graphs and a set of synthetic graphs with varying degrees of heterophily to demonstrate how the design choices for GCNH lead to a sizable improvement over a vanilla GCN. Moreover, GCNH outperforms state-of-the-art models of much higher complexity on four out of eight benchmarks, while producing comparable results on the remaining datasets. Finally, we discuss and analyze the lower complexity of GCNH, which results in fewer trainable parameters and faster training times than other methods, and show how GCNH mitigates the oversmoothing problem.
2-hop Neighbor Class Similarity : A graph structural metric indicative of graph neural network performance
Dec 26, 2022



Graph Neural Networks (GNNs) achieve state-of-the-art performance on graph-structured data across numerous domains. Their underlying ability to represent nodes as summaries of their vicinities has proven effective for homophilous graphs in particular, in which same-type nodes tend to connect. On heterophilous graphs, in which different-type nodes are likely connected, GNNs perform less consistently, as neighborhood information might be less representative or even misleading. On the other hand, GNN performance is not inferior on all heterophilous graphs, and there is a lack of understanding of what other graph properties affect GNN performance. In this work, we highlight the limitations of the widely used homophily ratio and the recent Cross-Class Neighborhood Similarity (CCNS) metric in estimating GNN performance. To overcome these limitations, we introduce 2-hop Neighbor Class Similarity (2NCS), a new quantitative graph structural property that correlates with GNN performance more strongly and consistently than alternative metrics. 2NCS considers two-hop neighborhoods as a theoretically derived consequence of the two-step label propagation process governing GCN's training-inference process. Experiments on one synthetic and eight real-world graph datasets confirm consistent improvements over existing metrics in estimating the accuracy of GCN- and GAT-based architectures on the node classification task.
Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
Mar 25, 2022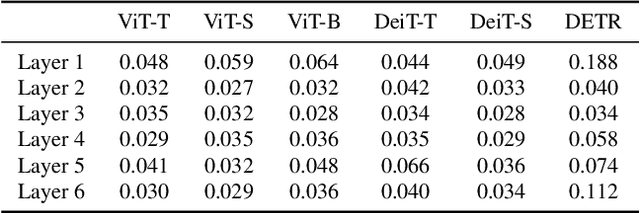
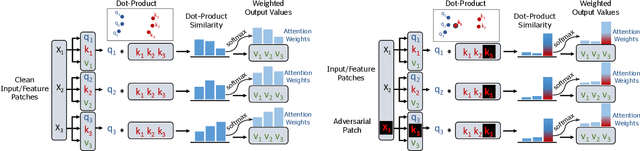
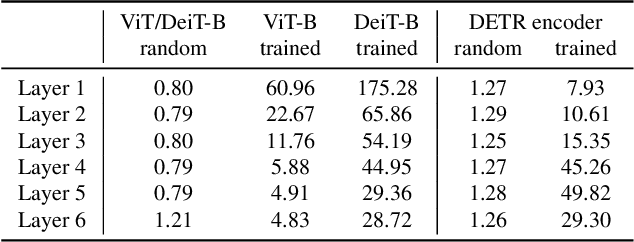
Neural architectures based on attention such as vision transformers are revolutionizing image recognition. Their main benefit is that attention allows reasoning about all parts of a scene jointly. In this paper, we show how the global reasoning of (scaled) dot-product attention can be the source of a major vulnerability when confronted with adversarial patch attacks. We provide a theoretical understanding of this vulnerability and relate it to an adversary's ability to misdirect the attention of all queries to a single key token under the control of the adversarial patch. We propose novel adversarial objectives for crafting adversarial patches which target this vulnerability explicitly. We show the effectiveness of the proposed patch attacks on popular image classification (ViTs and DeiTs) and object detection models (DETR). We find that adversarial patches occupying 0.5% of the input can lead to robust accuracies as low as 0% for ViT on ImageNet, and reduce the mAP of DETR on MS COCO to less than 3%.
Widen The Backdoor To Let More Attackers In
Oct 09, 2021


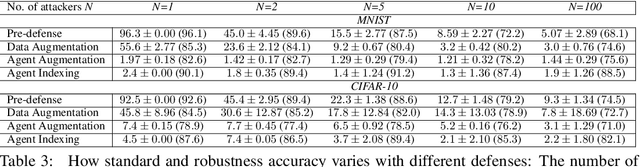
As collaborative learning and the outsourcing of data collection become more common, malicious actors (or agents) which attempt to manipulate the learning process face an additional obstacle as they compete with each other. In backdoor attacks, where an adversary attempts to poison a model by introducing malicious samples into the training data, adversaries have to consider that the presence of additional backdoor attackers may hamper the success of their own backdoor. In this paper, we investigate the scenario of a multi-agent backdoor attack, where multiple non-colluding attackers craft and insert triggered samples in a shared dataset which is used by a model (a defender) to learn a task. We discover a clear backfiring phenomenon: increasing the number of attackers shrinks each attacker's attack success rate (ASR). We then exploit this phenomenon to minimize the collective ASR of attackers and maximize defender's robustness accuracy by (i) artificially augmenting the number of attackers, and (ii) indexing to remove the attacker's sub-dataset from the model for inference, hence proposing 2 defenses.
They See Me Rollin': Inherent Vulnerability of the Rolling Shutter in CMOS Image Sensors
Jan 25, 2021



Cameras have become a fundamental component of vision-based intelligent systems. As a balance between production costs and image quality, most modern cameras use Complementary Metal-Oxide Semiconductor image sensors that implement an electronic rolling shutter mechanism, where image rows are captured consecutively rather than all-at-once. In this paper, we describe how the electronic rolling shutter can be exploited using a bright, modulated light source (e.g., an inexpensive, off-the-shelf laser), to inject fine-grained image disruptions. These disruptions substantially affect camera-based computer vision systems, where high-frequency data is crucial in extracting informative features from objects. We study the fundamental factors affecting a rolling shutter attack, such as environmental conditions, angle of the incident light, laser to camera distance, and aiming precision. We demonstrate how these factors affect the intensity of the injected distortion and how an adversary can take them into account by modeling the properties of the camera. We introduce a general pipeline of a practical attack, which consists of: (i) profiling several properties of the target camera and (ii) partially simulating the attack to find distortions that satisfy the adversary's goal. Then, we instantiate the attack to the scenario of object detection, where the adversary's goal is to maximally disrupt the detection of objects in the image. We show that the adversary can modulate the laser to hide up to 75% of objects perceived by state-of-the-art detectors while controlling the amount of perturbation to keep the attack inconspicuous. Our results indicate that rolling shutter attacks can substantially reduce the performance and reliability of vision-based intelligent systems.
Speaker Anonymization with Distribution-Preserving X-Vector Generation for the VoicePrivacy Challenge 2020
Oct 26, 2020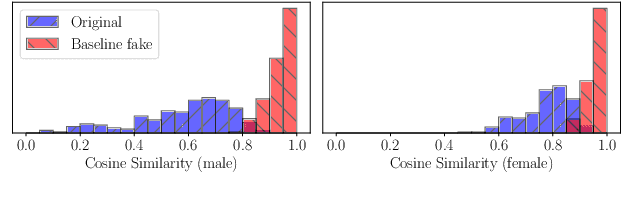
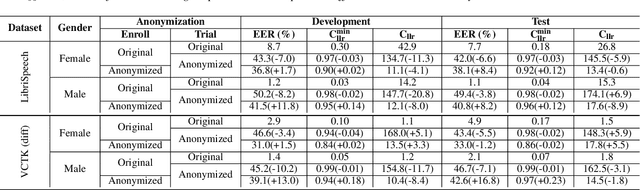
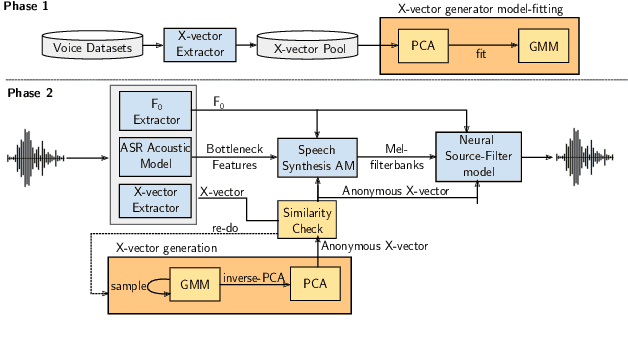
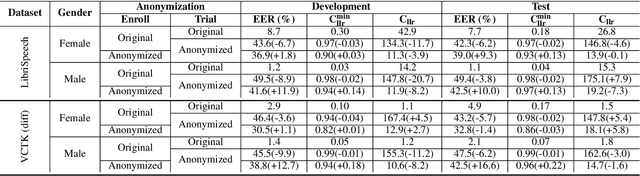
In this paper, we present a Distribution-Preserving Voice Anonymization technique, as our submission to the VoicePrivacy Challenge 2020. We notice that the challenge baseline system generates fake X-vectors which are very similar to each other, significantly more so than those extracted from organic speakers. This difference arises from averaging many X-vectors from a pool of speakers in the anonymization processs, causing a loss of information. We propose a new method to generate fake X-vectors which overcomes these limitations by preserving the distributional properties of X-vectors and their intra-similarity. We use population data to learn the properties of the X-vector space, before fitting a generative model which we use to sample fake X-vectors. We show how this approach generates X-vectors that more closely follow the expected intra-similarity distribution of organic speaker X-vectors. Our method can be easily integrated with others as the anonymization component of the system and removes the need to distribute a pool of speakers to use during the anonymization. Our approach leads to an increase in EER of up to 16.8\% in males and 8.4\% in females in scenarios where enrollment and trial utterances are anonymized versus the baseline solution, demonstrating the diversity of our generated voices.
SLAP: Improving Physical Adversarial Examples with Short-Lived Adversarial Perturbations
Jul 08, 2020
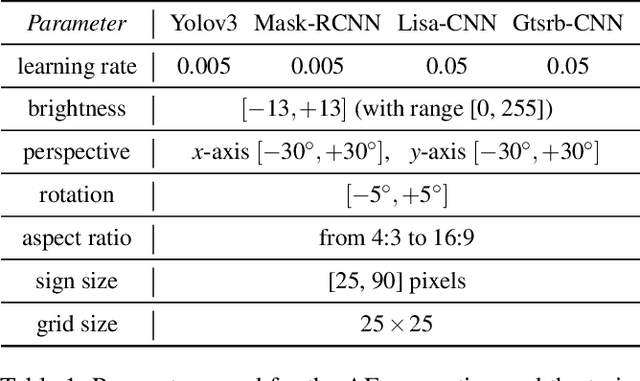

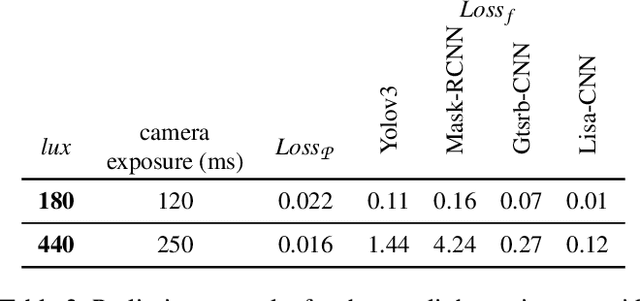
Whilst significant research effort into adversarial examples (AE) has emerged in recent years, the main vector to realize these attacks in the real-world currently relies on static adversarial patches, which are limited in their conspicuousness and can not be modified once deployed. In this paper, we propose Short-Lived Adversarial Perturbations (SLAP), a novel technique that allows adversaries to realize robust, dynamic real-world AE from a distance. As we show in this paper, such attacks can be achieved using a light projector to shine a specifically crafted adversarial image in order to perturb real-world objects and transform them into AE. This allows the adversary greater control over the attack compared to adversarial patches: (i) projections can be dynamically turned on and off or modified at will, (ii) projections do not suffer from the locality constraint imposed by patches, making them harder to detect. We study the feasibility of SLAP in the self-driving scenario, targeting both object detector and traffic sign recognition tasks. We demonstrate that the proposed method generates AE that are robust to different environmental conditions for several networks and lighting conditions: we successfully cause misclassifications of state-of-the-art networks such as Yolov3 and Mask-RCNN with up to 98% success rate for a variety of angles and distances. Additionally, we demonstrate that AE generated with SLAP can bypass SentiNet, a recent AE detection method which relies on the fact that adversarial patches generate highly salient and localized areas in the input images.
Seeing Red: PPG Biometrics Using Smartphone Cameras
Apr 15, 2020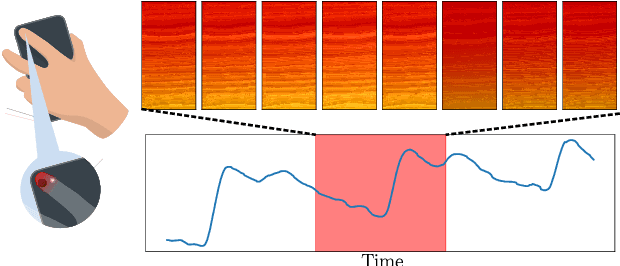
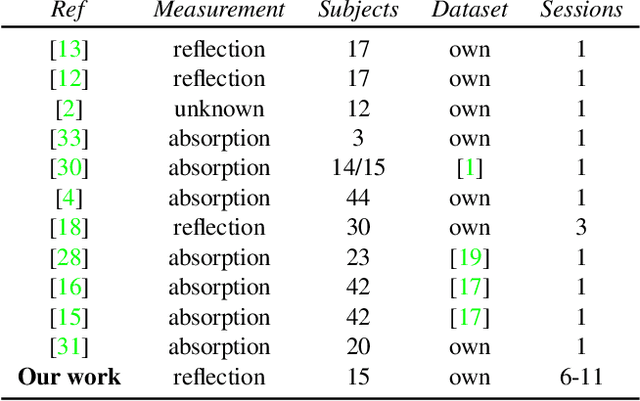
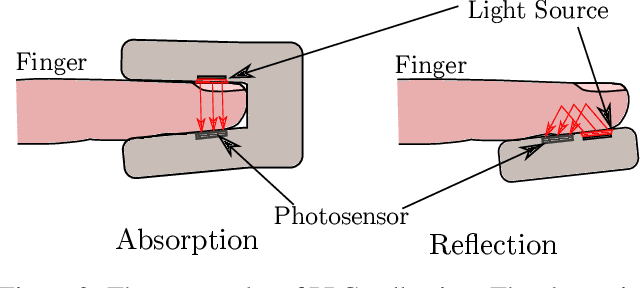
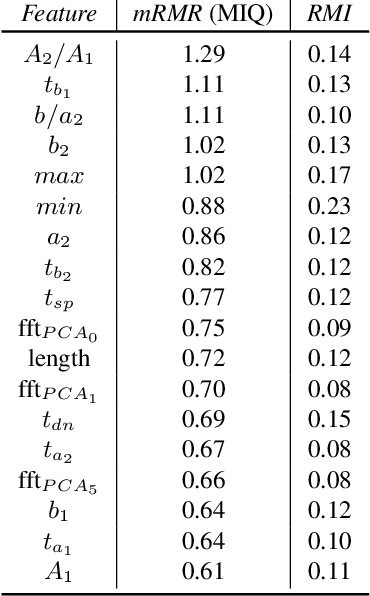
In this paper, we propose a system that enables photoplethysmogram (PPG)-based authentication by using a smartphone camera. PPG signals are obtained by recording a video from the camera as users are resting their finger on top of the camera lens. The signals can be extracted based on subtle changes in the video that are due to changes in the light reflection properties of the skin as the blood flows through the finger. We collect a dataset of PPG measurements from a set of 15 users over the course of 6-11 sessions per user using an iPhone X for the measurements. We design an authentication pipeline that leverages the uniqueness of each individual's cardiovascular system, identifying a set of distinctive features from each heartbeat. We conduct a set of experiments to evaluate the recognition performance of the PPG biometric trait, including cross-session scenarios which have been disregarded in previous work. We found that when aggregating sufficient samples for the decision we achieve an EER as low as 8%, but that the performance greatly decreases in the cross-session scenario, with an average EER of 20%.