 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance Scattering Transforms
Nov 12, 2025Machine learning and data processing techniques relying on covariance information are widespread as they identify meaningful patterns in unsupervised and unlabeled settings. As a prominent example, Principal Component Analysis (PCA) projects data points onto the eigenvectors of their covariance matrix, capturing the directions of maximum variance. This mapping, however, falls short in two directions: it fails to capture information in low-variance directions, relevant when, e.g., the data contains high-variance noise; and it provides unstable results in low-sample regimes, especially when covariance eigenvalues are close. CoVariance Neural Networks (VNNs), i.e., graph neural networks using the covariance matrix as a graph, show improved stability to estimation errors and learn more expressive functions in the covariance spectrum than PCA, but require training and operate in a labeled setup. To get the benefits of both worlds, we propose Covariance Scattering Transforms (CSTs), deep untrained networks that sequentially apply filters localized in the covariance spectrum to the input data and produce expressive hierarchical representations via nonlinearities. We define the filters as covariance wavelets that capture specific and detailed covariance spectral patterns. We improve CSTs' computational and memory efficiency via a pruning mechanism, and we prove that their error due to finite-sample covariance estimations is less sensitive to close covariance eigenvalues compared to PCA, improving their stability. Our experiments on age prediction from cortical thickness measurements on 4 datasets collecting patients with neurodegenerative diseases show that CSTs produce stable representations in low-data settings, as VNNs but without any training, and lead to comparable or better predictions w.r.t. more complex learning models.
Graph-Aware Diffusion for Signal Generation
Oct 06, 2025We study the problem of generating graph signals from unknown distributions defined over given graphs, relevant to domains such as recommender systems or sensor networks. Our approach builds on generative diffusion models, which are well established in vision and graph generation but remain underexplored for graph signals. Existing methods lack generality, either ignoring the graph structure in the forward process or designing graph-aware mechanisms tailored to specific domains. We adopt a forward process that incorporates the graph through the heat equation. Rather than relying on the standard formulation, we consider a time-warped coefficient to mitigate the exponential decay of the drift term, yielding a graph-aware generative diffusion model (GAD). We analyze its forward dynamics, proving convergence to a Gaussian Markov random field with covariance parametrized by the graph Laplacian, and interpret the backward dynamics as a sequence of graph-signal denoising problems. Finally, we demonstrate the advantages of GAD on synthetic data, real traffic speed measurements, and a temperature sensor network.
Precision Neural Networks: Joint Graph And Relational Learning
Sep 18, 2025CoVariance Neural Networks (VNNs) perform convolutions on the graph determined by the covariance matrix of the data, which enables expressive and stable covariance-based learning. However, covariance matrices are typically dense, fail to encode conditional independence, and are often precomputed in a task-agnostic way, which may hinder performance. To overcome these limitations, we study Precision Neural Networks (PNNs), i.e., VNNs on the precision matrix -- the inverse covariance. The precision matrix naturally encodes statistical independence, often exhibits sparsity, and preserves the covariance spectral structure. To make precision estimation task-aware, we formulate an optimization problem that jointly learns the network parameters and the precision matrix, and solve it via alternating optimization, by sequentially updating the network weights and the precision estimate. We theoretically bound the distance between the estimated and true precision matrices at each iteration, and demonstrate the effectiveness of joint estimation compared to two-step approaches on synthetic and real-world data.
CoVariance Filters and Neural Networks over Hilbert Spaces
Sep 16, 2025CoVariance Neural Networks (VNNs) perform graph convolutions on the empirical covariance matrix of signals defined over finite-dimensional Hilbert spaces, motivated by robustness and transferability properties. Yet, little is known about how these arguments extend to infinite-dimensional Hilbert spaces. In this work, we take a first step by introducing a novel convolutional learning framework for signals defined over infinite-dimensional Hilbert spaces, centered on the (empirical) covariance operator. We constructively define Hilbert coVariance Filters (HVFs) and design Hilbert coVariance Networks (HVNs) as stacks of HVF filterbanks with nonlinear activations. We propose a principled discretization procedure, and we prove that empirical HVFs can recover the Functional PCA (FPCA) of the filtered signals. We then describe the versatility of our framework with examples ranging from multivariate real-valued functions to reproducing kernel Hilbert spaces. Finally, we validate HVNs on both synthetic and real-world time-series classification tasks, showing robust performance compared to MLP and FPCA-based classifiers.
Directed Semi-Simplicial Learning with Applications to Brain Activity Decoding
May 23, 2025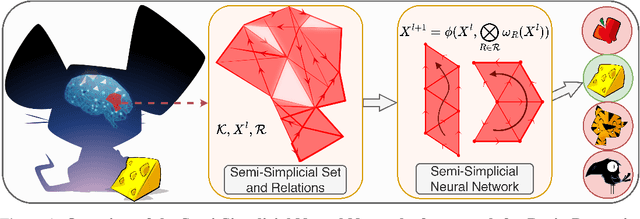
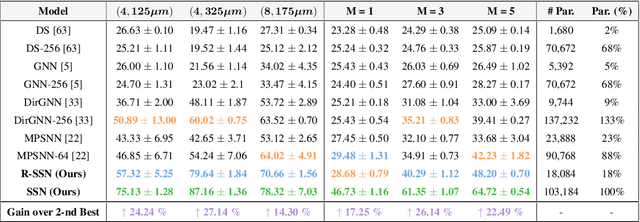
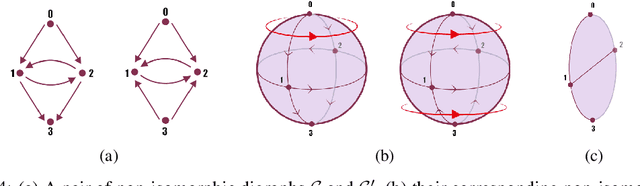
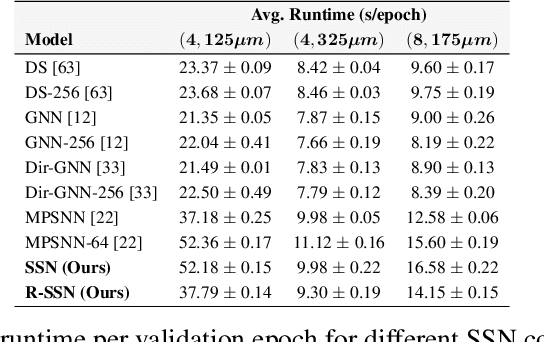
Graph Neural Networks (GNNs) excel at learning from pairwise interactions but often overlook multi-way and hierarchical relationships. Topological Deep Learning (TDL) addresses this limitation by leveraging combinatorial topological spaces. However, existing TDL models are restricted to undirected settings and fail to capture the higher-order directed patterns prevalent in many complex systems, e.g., brain networks, where such interactions are both abundant and functionally significant. To fill this gap, we introduce Semi-Simplicial Neural Networks (SSNs), a principled class of TDL models that operate on semi-simplicial sets -- combinatorial structures that encode directed higher-order motifs and their directional relationships. To enhance scalability, we propose Routing-SSNs, which dynamically select the most informative relations in a learnable manner. We prove that SSNs are strictly more expressive than standard graph and TDL models. We then introduce a new principled framework for brain dynamics representation learning, grounded in the ability of SSNs to provably recover topological descriptors shown to successfully characterize brain activity. Empirically, SSNs achieve state-of-the-art performance on brain dynamics classification tasks, outperforming the second-best model by up to 27%, and message passing GNNs by up to 50% in accuracy. Our results highlight the potential of principled topological models for learning from structured brain data, establishing a unique real-world case study for TDL. We also test SSNs on standard node classification and edge regression tasks, showing competitive performance. We will make the code and data publicly available.
Sparse Covariance Neural Networks
Oct 02, 2024
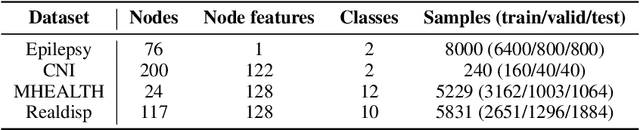
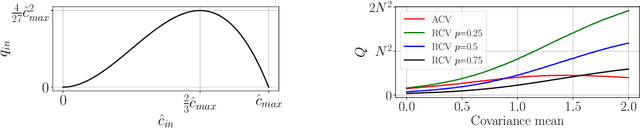
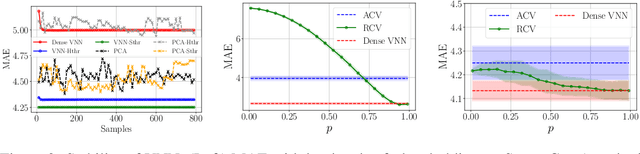
Covariance Neural Networks (VNNs) perform graph convolutions on the covariance matrix of tabular data and achieve success in a variety of applications. However, the empirical covariance matrix on which the VNNs operate may contain many spurious correlations, making VNNs' performance inconsistent due to these noisy estimates and decreasing their computational efficiency. To tackle this issue, we put forth Sparse coVariance Neural Networks (S-VNNs), a framework that applies sparsification techniques on the sample covariance matrix before convolution. When the true covariance matrix is sparse, we propose hard and soft thresholding to improve covariance estimation and reduce computational cost. Instead, when the true covariance is dense, we propose stochastic sparsification where data correlations are dropped in probability according to principled strategies. We show that S-VNNs are more stable than nominal VNNs as well as sparse principal component analysis. By analyzing the impact of sparsification on their behavior, we provide novel connections between S-VNN stability and data distribution. We support our theoretical findings with experimental results on various application scenarios, ranging from brain data to human action recognition, and show an improved task performance, stability, and computational efficiency of S-VNNs compared with nominal VNNs.
Spatiotemporal Covariance Neural Networks
Sep 16, 2024Modeling spatiotemporal interactions in multivariate time series is key to their effective processing, but challenging because of their irregular and often unknown structure. Statistical properties of the data provide useful biases to model interdependencies and are leveraged by correlation and covariance-based networks as well as by processing pipelines relying on principal component analysis (PCA). However, PCA and its temporal extensions suffer instabilities in the covariance eigenvectors when the corresponding eigenvalues are close to each other, making their application to dynamic and streaming data settings challenging. To address these issues, we exploit the analogy between PCA and graph convolutional filters to introduce the SpatioTemporal coVariance Neural Network (STVNN), a relational learning model that operates on the sample covariance matrix of the time series and leverages joint spatiotemporal convolutions to model the data. To account for the streaming and non-stationary setting, we consider an online update of the parameters and sample covariance matrix. We prove the STVNN is stable to the uncertainties introduced by these online estimations, thus improving over temporal PCA-based methods. Experimental results corroborate our theoretical findings and show that STVNN is competitive for multivariate time series processing, it adapts to changes in the data distribution, and it is orders of magnitude more stable than online temporal PCA.
* Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD) 2024
Fair CoVariance Neural Networks
Sep 13, 2024Covariance-based data processing is widespread across signal processing and machine learning applications due to its ability to model data interconnectivities and dependencies. However, harmful biases in the data may become encoded in the sample covariance matrix and cause data-driven methods to treat different subpopulations unfairly. Existing works such as fair principal component analysis (PCA) mitigate these effects, but remain unstable in low sample regimes, which in turn may jeopardize the fairness goal. To address both biases and instability, we propose Fair coVariance Neural Networks (FVNNs), which perform graph convolutions on the covariance matrix for both fair and accurate predictions. Our FVNNs provide a flexible model compatible with several existing bias mitigation techniques. In particular, FVNNs allow for mitigating the bias in two ways: first, they operate on fair covariance estimates that remove biases from their principal components; second, they are trained in an end-to-end fashion via a fairness regularizer in the loss function so that the model parameters are tailored to solve the task directly in a fair manner. We prove that FVNNs are intrinsically fairer than analogous PCA approaches thanks to their stability in low sample regimes. We validate the robustness and fairness of our model on synthetic and real-world data, showcasing the flexibility of FVNNs along with the tradeoff between fair and accurate performance.
Higher-Order Topological Directionality and Directed Simplicial Neural Networks
Sep 12, 2024
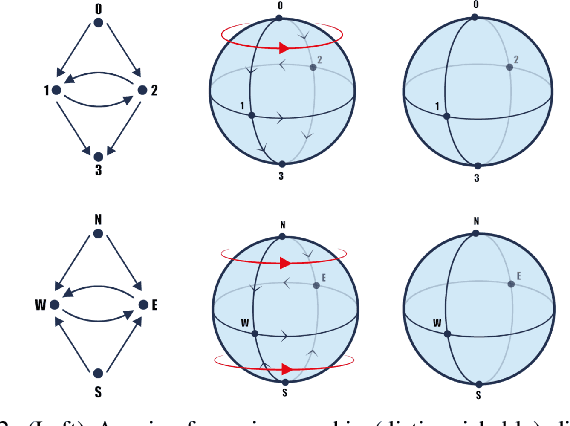


Topological Deep Learning (TDL) has emerged as a paradigm to process and learn from signals defined on higher-order combinatorial topological spaces, such as simplicial or cell complexes. Although many complex systems have an asymmetric relational structure, most TDL models forcibly symmetrize these relationships. In this paper, we first introduce a novel notion of higher-order directionality and we then design Directed Simplicial Neural Networks (Dir-SNNs) based on it. Dir-SNNs are message-passing networks operating on directed simplicial complexes able to leverage directed and possibly asymmetric interactions among the simplices. To our knowledge, this is the first TDL model using a notion of higher-order directionality. We theoretically and empirically prove that Dir-SNNs are more expressive than their directed graph counterpart in distinguishing isomorphic directed graphs. Experiments on a synthetic source localization task demonstrate that Dir-SNNs outperform undirected SNNs when the underlying complex is directed, and perform comparably when the underlying complex is undirected.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024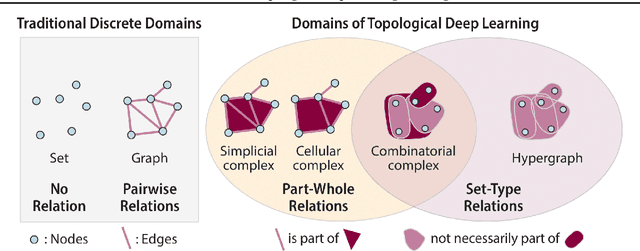
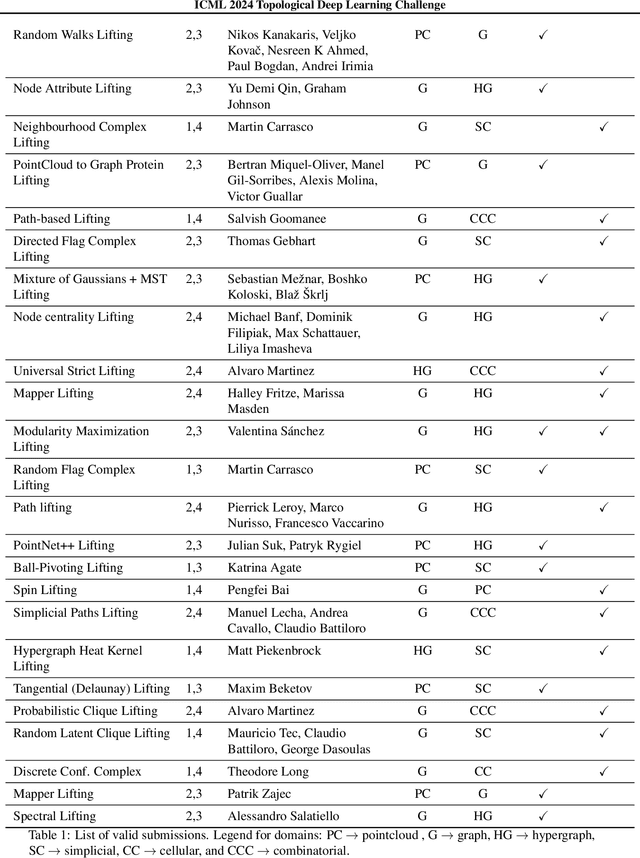
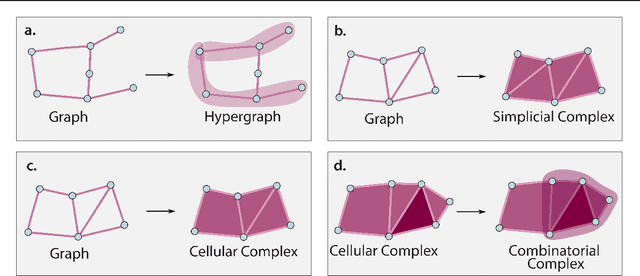
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.