 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Carbon Emissions and Energy Consumption of U.S. Hyperscale Data Centers
Jun 03, 2026The rapid proliferation of hyperscale data centers (HDCs) in the US, mainly driven by the adoption of artificial intelligence, has raised concerns about this industry's environmental footprint. We compiled facility-level information on 403 US hyperscale data centers operating between May 2024 and April 2025 and estimated their electricity consumption, electricity sources, and attributable CO2 emissions. Across different facility-load scenarios, these HDCs consumed approximately 68-99 TWh of electricity and were associated with about 37-54 million metric tons of CO2. Under the central scenario, HDC electricity demand corresponded to approximately 1.8% of total US electricity consumption, with roughly 54% of attributed generation supplied by fossil-fuel sources. The HDC electricity-weighted average carbon intensity was approximately 545 gCO2/kWh, about 48% above the contemporaneous US national grid-average carbon intensity of 370 gCO2/kWh. Our approach provides an attributional tool for assessing the environmental footprint of hyperscale data centers using the most recent EPA eGRID plant-level data.
Consistent Geometric Deep Learning via Hilbert Bundles and Cellular Sheaves
May 07, 2026Modern deep learning architectures increasingly contend with sophisticated signals that are natively infinite-dimensional, such as time series, probability distributions, or operators, and are defined over irregular domains. Yet, a unified learning theory for these settings has been lacking. To start addressing this gap, we introduce a novel convolutional learning framework for possibly infinite-dimensional signals supported on a manifold. Namely, we use the connection Laplacian associated with a Hilbert bundle as a convolutional operator, and we derive filters and neural networks, dubbed as \textit{HilbNets}. We make HilbNets and, more generally, the convolution operation, implementable via a two-stage sampling procedure. First, we show that sampling the manifold induces a Hilbert Cellular Sheaf, a generalized graph structure with Hilbert feature spaces and edge-wise coupling rules, and we prove that its sheaf Laplacian converges in probability to the underlying connection Laplacian as the sampling density increases. Notably, this result is a generalization to the infinite-dimensional bundle setting of the Belkin \& Niyogi \cite{BELKIN20081289} convergence result for the graph Laplacian to the manifold Laplacian, a theoretical cornerstone of geometric learning methods. Second, we discretize the signals and prove that the discretized (implementable) HilbNets converge to the underlying continuous architectures and are transferable across different samplings of the same bundle, providing consistency for learning. Finally, we validate our framework on synthetic and real-world tasks. Overall, our results broaden the scope of geometric learning as a whole by lifting classical Laplacian-based frameworks to settings where the signal at each point lives in its own Hilbert space.
Guided Transfer Learning for Discrete Diffusion Models
Dec 11, 2025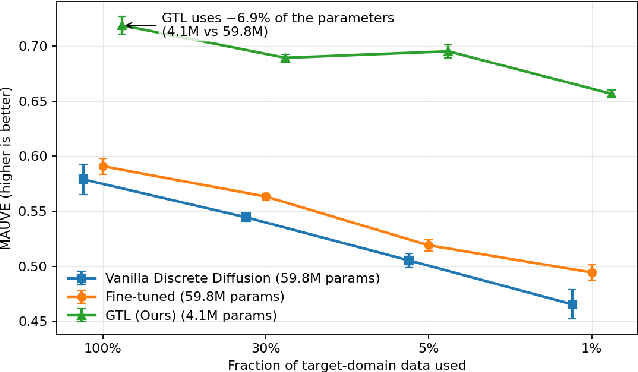

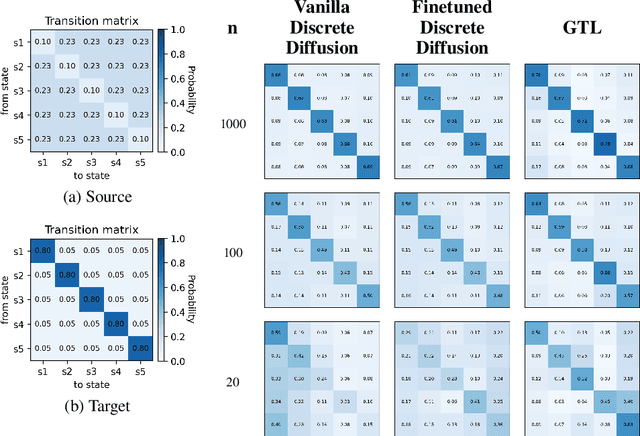
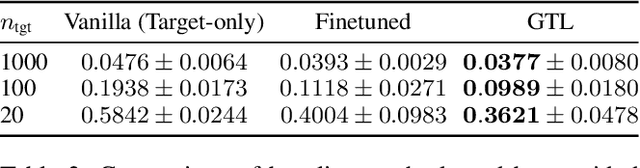
Discrete diffusion models achieve strong performance across language and other discrete domains, providing a powerful alternative to autoregressive models. However, their strong performance relies on large training datasets, which are costly or risky to obtain, especially when adapting to new domains. Transfer learning is the natural way to adapt pretrained discrete diffusion models, but current methods require fine-tuning large diffusion models, which is computationally expensive and often impractical. Building on ratio-based transfer learning for continuous diffusion, we provide Guided Transfer Learning for discrete diffusion models (GTL). This enables sampling from a target distribution without modifying the pretrained denoiser. The same guidance formulation applies to both discrete-time diffusion and continuous-time score-based discrete diffusion, yielding a unified treatment. Guided discrete diffusion often requires many forward passes of the guidance network, which becomes impractical for large vocabularies and long sequences. To address this, we further present an efficient guided sampler that concentrates evaluations on planner-selected positions and top candidate tokens, thus lowering sampling time and computation. This makes guided language modeling practical at scale for large vocabularies and long sequences. We evaluate GTL on sequential data, including synthetic Markov chains and language modeling, and provide empirical analyses of its behavior.
Algorithmic Collective Action with Multiple Collectives
Aug 26, 2025As learning systems increasingly influence everyday decisions, user-side steering via Algorithmic Collective Action (ACA)-coordinated changes to shared data-offers a complement to regulator-side policy and firm-side model design. Although real-world actions have been traditionally decentralized and fragmented into multiple collectives despite sharing overarching objectives-with each collective differing in size, strategy, and actionable goals, most of the ACA literature focused on single collective settings. In this work, we present the first theoretical framework for ACA with multiple collectives acting on the same system. In particular, we focus on collective action in classification, studying how multiple collectives can plant signals, i.e., bias a classifier to learn an association between an altered version of the features and a chosen, possibly overlapping, set of target classes. We provide quantitative results about the role and the interplay of collectives' sizes and their alignment of goals. Our framework, by also complementing previous empirical results, opens a path for a holistic treatment of ACA with multiple collectives.
Directed Semi-Simplicial Learning with Applications to Brain Activity Decoding
May 23, 2025
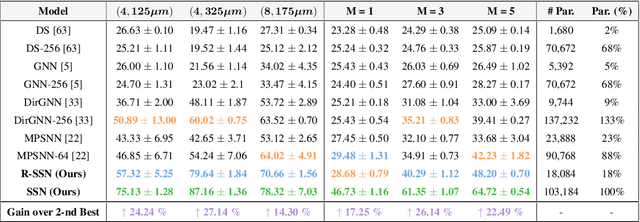
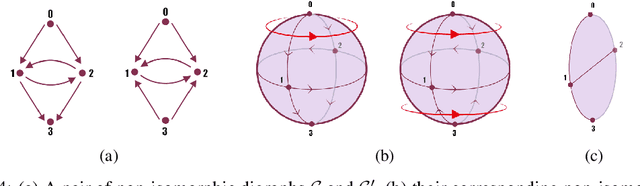
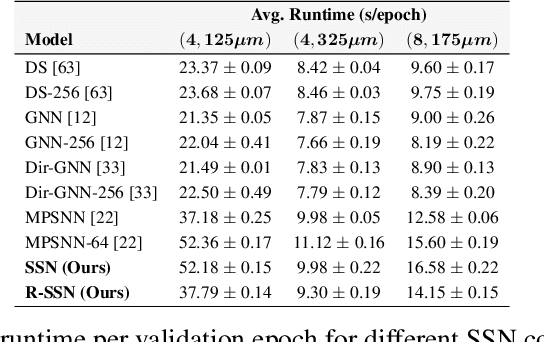
Graph Neural Networks (GNNs) excel at learning from pairwise interactions but often overlook multi-way and hierarchical relationships. Topological Deep Learning (TDL) addresses this limitation by leveraging combinatorial topological spaces. However, existing TDL models are restricted to undirected settings and fail to capture the higher-order directed patterns prevalent in many complex systems, e.g., brain networks, where such interactions are both abundant and functionally significant. To fill this gap, we introduce Semi-Simplicial Neural Networks (SSNs), a principled class of TDL models that operate on semi-simplicial sets -- combinatorial structures that encode directed higher-order motifs and their directional relationships. To enhance scalability, we propose Routing-SSNs, which dynamically select the most informative relations in a learnable manner. We prove that SSNs are strictly more expressive than standard graph and TDL models. We then introduce a new principled framework for brain dynamics representation learning, grounded in the ability of SSNs to provably recover topological descriptors shown to successfully characterize brain activity. Empirically, SSNs achieve state-of-the-art performance on brain dynamics classification tasks, outperforming the second-best model by up to 27%, and message passing GNNs by up to 50% in accuracy. Our results highlight the potential of principled topological models for learning from structured brain data, establishing a unique real-world case study for TDL. We also test SSNs on standard node classification and edge regression tasks, showing competitive performance. We will make the code and data publicly available.
Quantum Simplicial Neural Networks
Jan 09, 2025



Graph Neural Networks (GNNs) excel at learning from graph-structured data but are limited to modeling pairwise interactions, insufficient for capturing higher-order relationships present in many real-world systems. Topological Deep Learning (TDL) has allowed for systematic modeling of hierarchical higher-order interactions by relying on combinatorial topological spaces such as simplicial complexes. In parallel, Quantum Neural Networks (QNNs) have been introduced to leverage quantum mechanics for enhanced computational and learning power. In this work, we present the first Quantum Topological Deep Learning Model: Quantum Simplicial Networks (QSNs), being QNNs operating on simplicial complexes. QSNs are a stack of Quantum Simplicial Layers, which are inspired by the Ising model to encode higher-order structures into quantum states. Experiments on synthetic classification tasks show that QSNs can outperform classical simplicial TDL models in accuracy and efficiency, demonstrating the potential of combining quantum computing with TDL for processing data on combinatorial topological spaces.
Towards a Health-Based Power Grid Optimization in the Artificial Intelligence Era
Oct 11, 2024
The electric power sector is one of the largest contributors to greenhouse gas emissions in the world. In recent years, there has been an unprecedented increase in electricity demand driven by the so-called Artificial Intelligence (AI) revolution. Although AI has and will continue to have a transformative impact, its environmental and health impacts are often overlooked. The standard approach to power grid optimization aims to minimize CO$_2$ emissions. In this paper, we propose a new holistic paradigm. Our proposed optimization directly targets the minimization of adverse health outcomes under energy efficiency and emission constraints. We show the first example of an optimal fuel mix allocation problem aiming to minimize the average number of adverse health effects resulting from exposure to hazardous air pollutants with constraints on the average and marginal emissions. We argue that this new health-based power grid optimization is essential to promote truly sustainable technological advances that align both with global climate goals and public health priorities.
Higher-Order Topological Directionality and Directed Simplicial Neural Networks
Sep 12, 2024
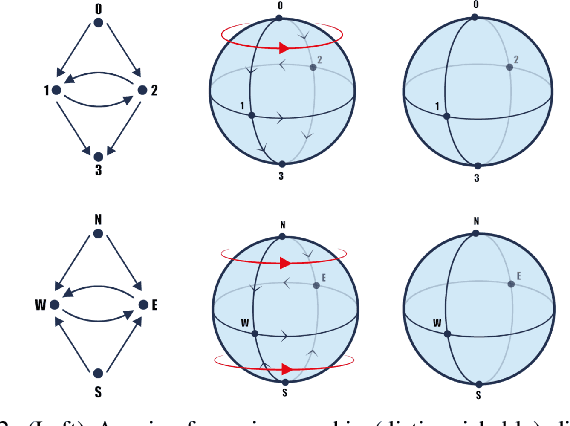


Topological Deep Learning (TDL) has emerged as a paradigm to process and learn from signals defined on higher-order combinatorial topological spaces, such as simplicial or cell complexes. Although many complex systems have an asymmetric relational structure, most TDL models forcibly symmetrize these relationships. In this paper, we first introduce a novel notion of higher-order directionality and we then design Directed Simplicial Neural Networks (Dir-SNNs) based on it. Dir-SNNs are message-passing networks operating on directed simplicial complexes able to leverage directed and possibly asymmetric interactions among the simplices. To our knowledge, this is the first TDL model using a notion of higher-order directionality. We theoretically and empirically prove that Dir-SNNs are more expressive than their directed graph counterpart in distinguishing isomorphic directed graphs. Experiments on a synthetic source localization task demonstrate that Dir-SNNs outperform undirected SNNs when the underlying complex is directed, and perform comparably when the underlying complex is undirected.
E(n) Equivariant Topological Neural Networks
May 24, 2024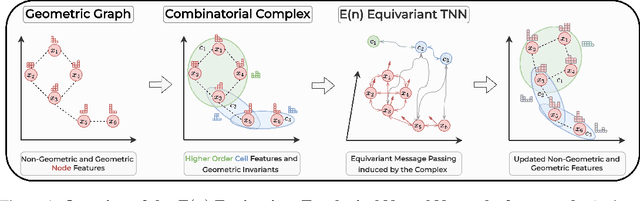
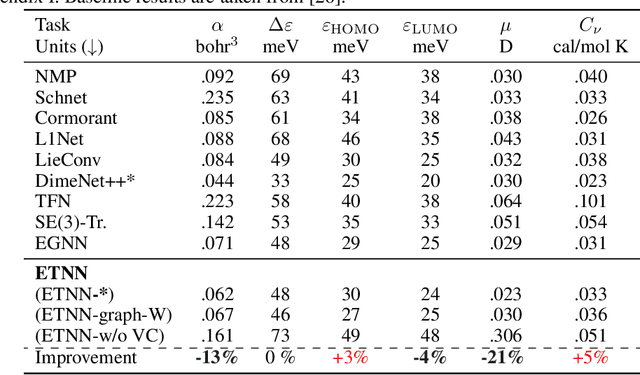
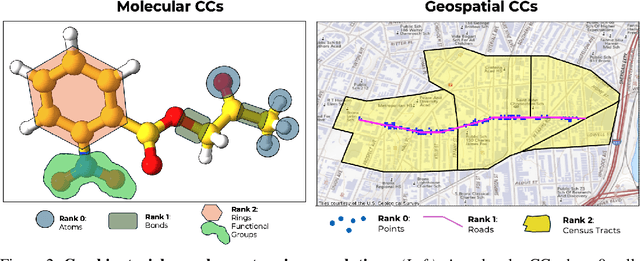
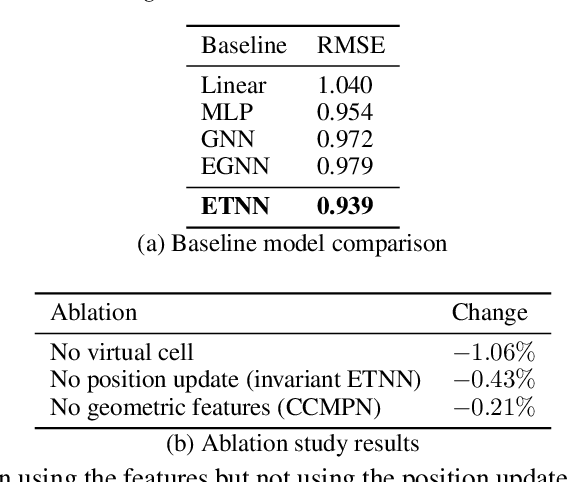
Graph neural networks excel at modeling pairwise interactions, but they cannot flexibly accommodate higher-order interactions and features. Topological deep learning (TDL) has emerged recently as a promising tool for addressing this issue. TDL enables the principled modeling of arbitrary multi-way, hierarchical higher-order interactions by operating on combinatorial topological spaces, such as simplicial or cell complexes, instead of graphs. However, little is known about how to leverage geometric features such as positions and velocities for TDL. This paper introduces E(n)-Equivariant Topological Neural Networks (ETNNs), which are E(n)-equivariant message-passing networks operating on combinatorial complexes, formal objects unifying graphs, hypergraphs, simplicial, path, and cell complexes. ETNNs incorporate geometric node features while respecting rotation and translation equivariance. Moreover, ETNNs are natively ready for settings with heterogeneous interactions. We provide a theoretical analysis to show the improved expressiveness of ETNNs over architectures for geometric graphs. We also show how several E(n) equivariant variants of TDL models can be directly derived from our framework. The broad applicability of ETNNs is demonstrated through two tasks of vastly different nature: i) molecular property prediction on the QM9 benchmark and ii) land-use regression for hyper-local estimation of air pollution with multi-resolution irregular geospatial data. The experiment results indicate that ETNNs are an effective tool for learning from diverse types of richly structured data, highlighting the benefits of principled geometric inductive bias.
Optimizing Heat Alert Issuance for Public Health in the United States with Reinforcement Learning
Dec 21, 2023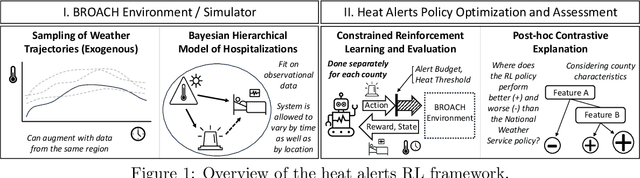
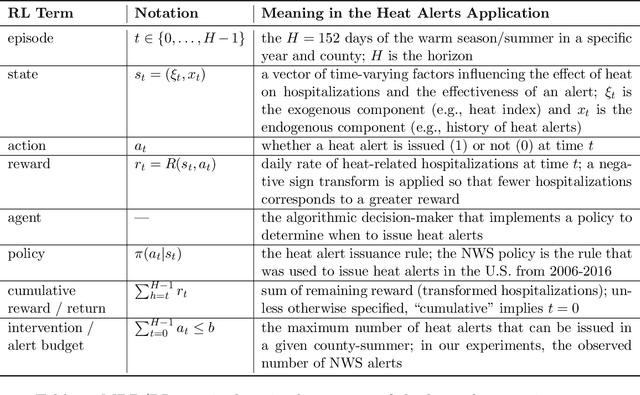
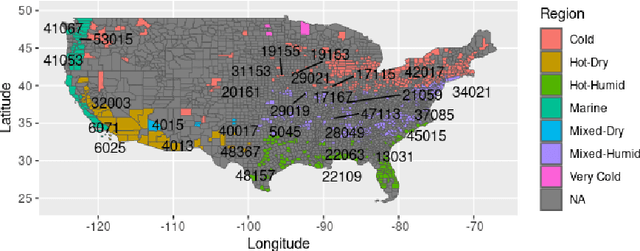

Alerting the public when heat may harm their health is a crucial service, especially considering that extreme heat events will be more frequent under climate change. Current practice for issuing heat alerts in the US does not take advantage of modern data science methods for optimizing local alert criteria. Specifically, application of reinforcement learning (RL) has the potential to inform more health-protective policies, accounting for regional and sociodemographic heterogeneity as well as sequential dependence of alerts. In this work, we formulate the issuance of heat alerts as a sequential decision making problem and develop modifications to the RL workflow to address challenges commonly encountered in environmental health settings. Key modifications include creating a simulator that pairs hierarchical Bayesian modeling of low-signal health effects with sampling of real weather trajectories (exogenous features), constraining the total number of alerts issued as well as preventing alerts on less-hot days, and optimizing location-specific policies. Post-hoc contrastive analysis offers insights into scenarios when using RL for heat alert issuance may protect public health better than the current or alternative policies. This work contributes to a broader movement of advancing data-driven policy optimization for public health and climate change adaptation.