 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Preferences for Brands and Cultures in LLMs
Mar 18, 2026Large language models (LLMs) based AI systems increasingly mediate what billions of people see, choose and buy. This creates an urgent need to quantify the systemic risks of LLM-driven market intermediation, including its implications for market fairness, competition, and the diversity of information exposure. This paper introduces ChoiceEval, a reproducible framework for auditing preferences for brands and cultures in large language models (LLMs) under realistic usage conditions. ChoiceEval addresses two core technical challenges: (i) generating realistic, persona-diverse evaluation queries and (ii) converting free-form outputs into comparable choice sets and quantitative preference metrics. For a given topic (e.g. running shoes, hotel chains, travel destinations), the framework segments users into psychographic profiles (e.g., budget-conscious, wellness-focused, convenience), and then derives diverse prompts that reflect real-world advice-seeking and decision-making behaviour. LLM responses are converted into normalised top-k choice sets. Preference and geographic bias are then quantified using comparable metrics across topics and personas. Thus, ChoiceEval provides a scalable audit pipeline for researchers, platforms, and regulators, linking model behaviour to real-world economic outcomes. Applied to Gemini, GPT, and DeepSeek across 10 topics spanning commerce and culture and more than 2,000 questions, ChoiceEval reveals consistent preferences: U.S.-developed models Gemini and GPT show marked favouritism toward American entities, while China-developed DeepSeek exhibits more balanced yet still detectable geographic preferences. These patterns persist across user personas, suggesting systematic rather than incidental effects.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024

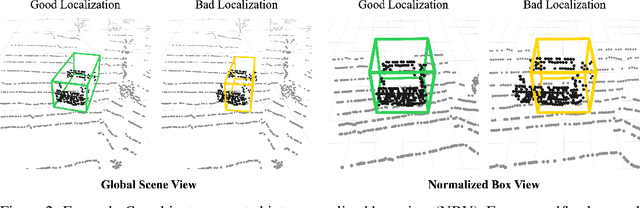

Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Online Feature Updates Improve Online (Generalized) Label Shift Adaptation
Feb 05, 2024This paper addresses the prevalent issue of label shift in an online setting with missing labels, where data distributions change over time and obtaining timely labels is challenging. While existing methods primarily focus on adjusting or updating the final layer of a pre-trained classifier, we explore the untapped potential of enhancing feature representations using unlabeled data at test-time. Our novel method, Online Label Shift adaptation with Online Feature Updates (OLS-OFU), leverages self-supervised learning to refine the feature extraction process, thereby improving the prediction model. Theoretical analyses confirm that OLS-OFU reduces algorithmic regret by capitalizing on self-supervised learning for feature refinement. Empirical studies on various datasets, under both online label shift and generalized label shift conditions, underscore the effectiveness and robustness of OLS-OFU, especially in cases of domain shifts.
Prompt Expansion for Adaptive Text-to-Image Generation
Dec 27, 2023


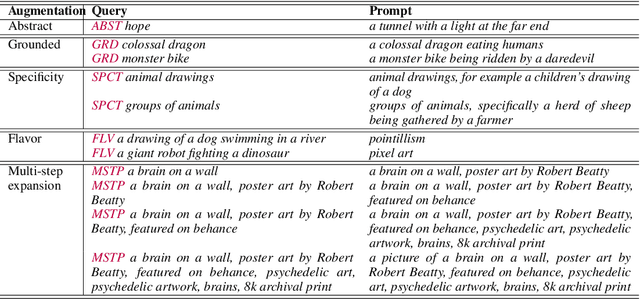
Text-to-image generation models are powerful but difficult to use. Users craft specific prompts to get better images, though the images can be repetitive. This paper proposes a Prompt Expansion framework that helps users generate high-quality, diverse images with less effort. The Prompt Expansion model takes a text query as input and outputs a set of expanded text prompts that are optimized such that when passed to a text-to-image model, generates a wider variety of appealing images. We conduct a human evaluation study that shows that images generated through Prompt Expansion are more aesthetically pleasing and diverse than those generated by baseline methods. Overall, this paper presents a novel and effective approach to improving the text-to-image generation experience.
Projected Subnetworks Scale Adaptation
Jan 27, 2023



Large models support great zero-shot and few-shot capabilities. However, updating these models on new tasks can break performance on previous seen tasks and their zero/few-shot unseen tasks. Our work explores how to update zero/few-shot learners such that they can maintain performance on seen/unseen tasks of previous tasks as well as new tasks. By manipulating the parameter updates of a gradient-based meta learner as the projected task-specific subnetworks, we show improvements for large models to retain seen and zero/few shot task performance in online settings.
Cross-Reality Re-Rendering: Manipulating between Digital and Physical Realities
Nov 24, 2022The advent of personalized reality has arrived. Rapid development in AR/MR/VR enables users to augment or diminish their perception of the physical world. Robust tooling for digital interface modification enables users to change how their software operates. As digital realities become an increasingly-impactful aspect of human lives, we investigate the design of a system that enables users to manipulate the perception of both their physical realities and digital realities. Users can inspect their view history from either reality, and generate interventions that can be interoperably rendered cross-reality in real-time. Personalized interventions can be generated with mask, text, and model hooks. Collaboration between users scales the availability of interventions. We verify our implementation against our design requirements with cognitive walkthroughs, personas, and scalability tests.
Multiple Modes for Continual Learning
Sep 29, 2022


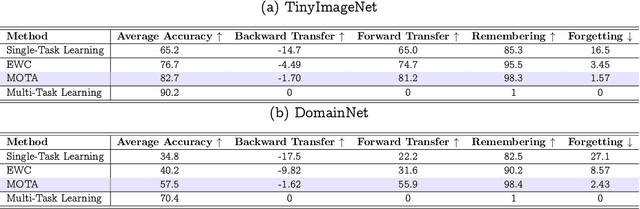
Adapting model parameters to incoming streams of data is a crucial factor to deep learning scalability. Interestingly, prior continual learning strategies in online settings inadvertently anchor their updated parameters to a local parameter subspace to remember old tasks, else drift away from the subspace and forget. From this observation, we formulate a trade-off between constructing multiple parameter modes and allocating tasks per mode. Mode-Optimized Task Allocation (MOTA), our contributed adaptation strategy, trains multiple modes in parallel, then optimizes task allocation per mode. We empirically demonstrate improvements over baseline continual learning strategies and across varying distribution shifts, namely sub-population, domain, and task shift.
Interpolating Compressed Parameter Subspaces
May 19, 2022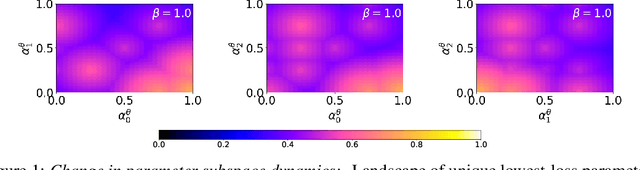
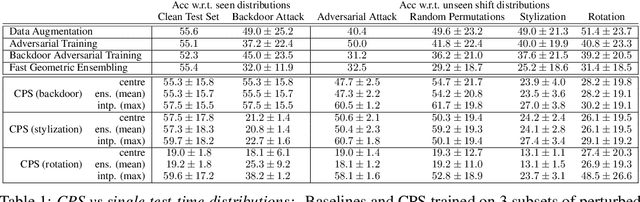
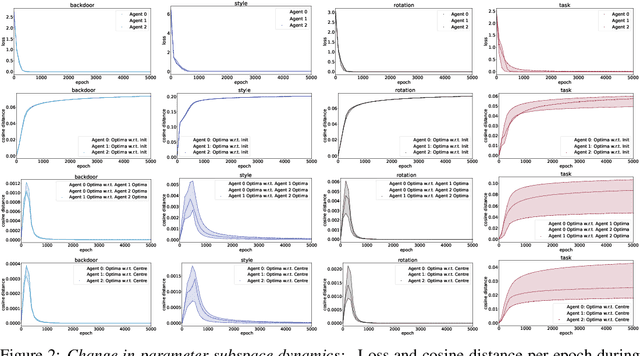
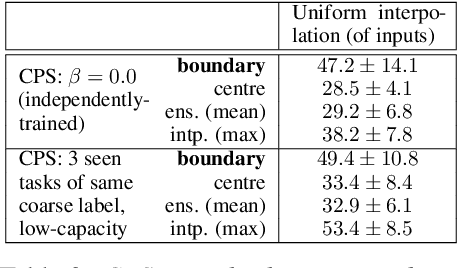
Inspired by recent work on neural subspaces and mode connectivity, we revisit parameter subspace sampling for shifted and/or interpolatable input distributions (instead of a single, unshifted distribution). We enforce a compressed geometric structure upon a set of trained parameters mapped to a set of train-time distributions, denoting the resulting subspaces as Compressed Parameter Subspaces (CPS). We show the success and failure modes of the types of shifted distributions whose optimal parameters reside in the CPS. We find that ensembling point-estimates within a CPS can yield a high average accuracy across a range of test-time distributions, including backdoor, adversarial, permutation, stylization and rotation perturbations. We also find that the CPS can contain low-loss point-estimates for various task shifts (albeit interpolated, perturbed, unseen or non-identical coarse labels). We further demonstrate this property in a continual learning setting with CIFAR100.
Parameter Adaptation for Joint Distribution Shifts
May 15, 2022
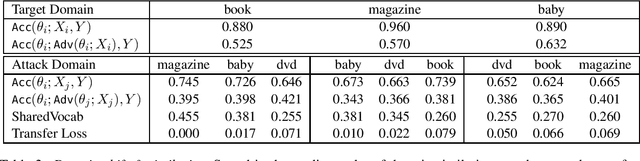

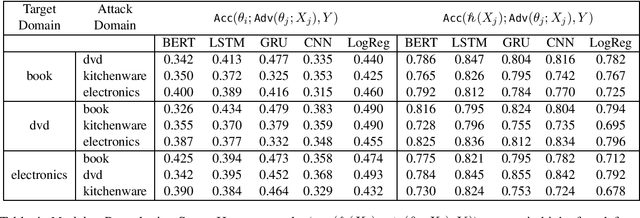
While different methods exist to tackle distinct types of distribution shift, such as label shift (in the form of adversarial attacks) or domain shift, tackling the joint shift setting is still an open problem. Through the study of a joint distribution shift manifesting both adversarial and domain-specific perturbations, we not only show that a joint shift worsens model performance compared to their individual shifts, but that the use of a similar domain worsens performance than a dissimilar domain. To curb the performance drop, we study the use of perturbation sets motivated by input and parameter space bounds, and adopt a meta learning strategy (hypernetworks) to model parameters w.r.t. test-time inputs to recover performance.
GreaseVision: Rewriting the Rules of the Interface
Apr 07, 2022


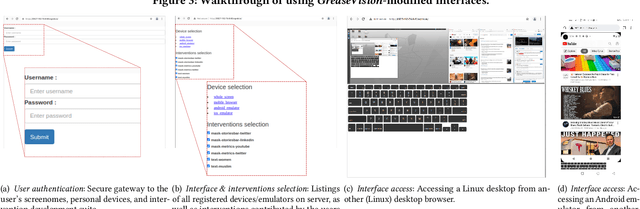
Digital harms can manifest across any interface. Key problems in addressing these harms include the high individuality of harms and the fast-changing nature of digital systems. As a result, we still lack a systematic approach to study harms and produce interventions for end-users. We put forward GreaseVision, a new framework that enables end-users to collaboratively develop interventions against harms in software using a no-code approach and recent advances in few-shot machine learning. The contribution of the framework and tool allow individual end-users to study their usage history and create personalized interventions. Our contribution also enables researchers to study the distribution of harms and interventions at scale.