 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Edge Signals: Orientation Equivariance and Invariance
Oct 22, 2024



Many applications in traffic, civil engineering, or electrical engineering revolve around edge-level signals. Such signals can be categorized as inherently directed, for example, the water flow in a pipe network, and undirected, like the diameter of a pipe. Topological methods model edge signals with inherent direction by representing them relative to a so-called orientation assigned to each edge. These approaches can neither model undirected edge signals nor distinguish if an edge itself is directed or undirected. We address these shortcomings by (i) revising the notion of orientation equivariance to enable edge direction-aware topological models, (ii) proposing orientation invariance as an additional requirement to describe signals without inherent direction, and (iii) developing EIGN, an architecture composed of novel direction-aware edge-level graph shift operators, that provably fulfills the aforementioned desiderata. It is the first general-purpose topological GNN for edge-level signals that can model directed and undirected signals while distinguishing between directed and undirected edges. A comprehensive evaluation shows that EIGN outperforms prior work in edge-level tasks, for example, improving in RMSE on flow simulation tasks by up to 43.5%.
Learning-Based Link Anomaly Detection in Continuous-Time Dynamic Graphs
May 28, 2024



Anomaly detection in continuous-time dynamic graphs is an emerging field yet under-explored in the context of learning-based approaches. In this paper, we pioneer structured analyses of link-level anomalies and graph representation learning for identifying anomalous links in these graphs. First, we introduce a fine-grain taxonomy for edge-level anomalies leveraging structural, temporal, and contextual graph properties. We present a method for generating and injecting such typed anomalies into graphs. Next, we introduce a novel method to generate continuous-time dynamic graphs with consistent patterns across time, structure, and context. To allow temporal graph methods to learn the link anomaly detection task, we extend the generic link prediction setting by: (1) conditioning link existence on contextual edge attributes; and (2) refining the training regime to accommodate diverse perturbations in the negative edge sampler. Building on this, we benchmark methods for anomaly detection. Comprehensive experiments on synthetic and real-world datasets -- featuring synthetic and labeled organic anomalies and employing six state-of-the-art learning methods -- validate our taxonomy and generation processes for anomalies and benign graphs, as well as our approach to adapting link prediction methods for anomaly detection. Our results further reveal that different learning methods excel in capturing different aspects of graph normality and detecting different types of anomalies. We conclude with a comprehensive list of findings highlighting opportunities for future research.
Using Focal Loss to Fight Shallow Heuristics: An Empirical Analysis of Modulated Cross-Entropy in Natural Language Inference
Nov 23, 2022



There is no such thing as a perfect dataset. In some datasets, deep neural networks discover underlying heuristics that allow them to take shortcuts in the learning process, resulting in poor generalization capability. Instead of using standard cross-entropy, we explore whether a modulated version of cross-entropy called focal loss can constrain the model so as not to use heuristics and improve generalization performance. Our experiments in natural language inference show that focal loss has a regularizing impact on the learning process, increasing accuracy on out-of-distribution data, but slightly decreasing performance on in-distribution data. Despite the improved out-of-distribution performance, we demonstrate the shortcomings of focal loss and its inferiority in comparison to the performance of methods such as unbiased focal loss and self-debiasing ensembles.
AdaGrid: Adaptive Grid Search for Link Prediction Training Objective
Mar 30, 2022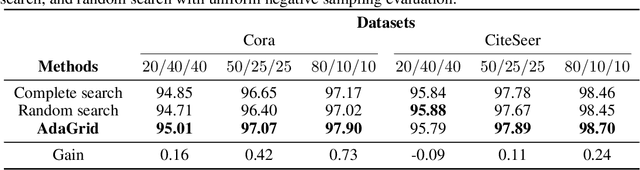
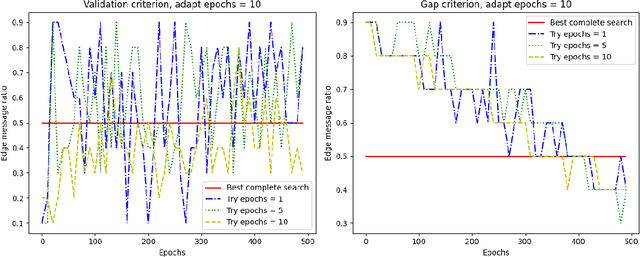

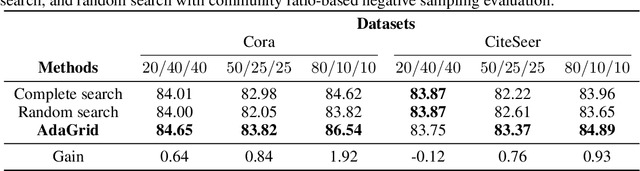
One of the most important factors that contribute to the success of a machine learning model is a good training objective. Training objective crucially influences the model's performance and generalization capabilities. This paper specifically focuses on graph neural network training objective for link prediction, which has not been explored in the existing literature. Here, the training objective includes, among others, a negative sampling strategy, and various hyperparameters, such as edge message ratio which controls how training edges are used. Commonly, these hyperparameters are fine-tuned by complete grid search, which is very time-consuming and model-dependent. To mitigate these limitations, we propose Adaptive Grid Search (AdaGrid), which dynamically adjusts the edge message ratio during training. It is model agnostic and highly scalable with a fully customizable computational budget. Through extensive experiments, we show that AdaGrid can boost the performance of the models up to $1.9\%$ while being nine times more time-efficient than a complete search. Overall, AdaGrid represents an effective automated algorithm for designing machine learning training objectives.
Learning-based link prediction analysis for Facebook100 network
Aug 01, 2020



In social network science, Facebook is one of the most interesting and widely used social networks and media platforms. In the previous decade Facebook data contributed to significant evolution of social network research. Paired with this topic we have experienced growing popularity in the link prediction techniques, which are important tools in link mining and analysis. This paper gives a comprehensive overview of link prediction analysis on the Facebook100 network, which was derived in 2005. We study performance and evaluate multiple machine learning algorithms on this network. We use networks embeddings and topology-based techniques such as node2vec and vectors of similarity metrics. Using these techniques similarity features for our classification models are derived. Further we discuss our approach and present results. Lastly, we compare and review our models, where overall performance and classification rates are presented.