 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
May 27, 2024The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
Breaking the Language Barrier: Improving Cross-Lingual Reasoning with Structured Self-Attention
Oct 23, 2023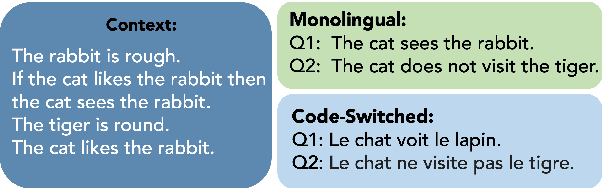
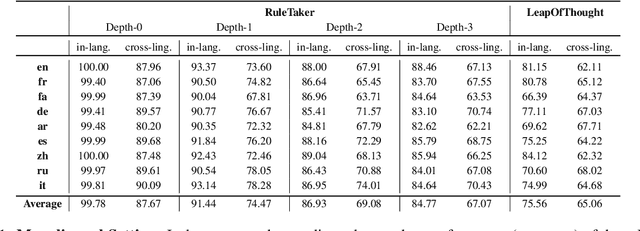
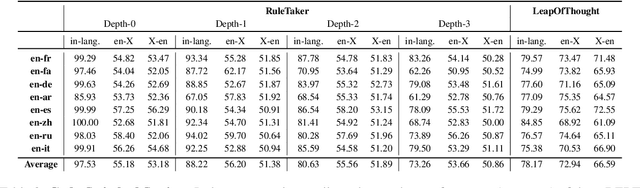

In this work, we study whether multilingual language models (MultiLMs) can transfer logical reasoning abilities to other languages when they are fine-tuned for reasoning in a different language. We evaluate the cross-lingual reasoning abilities of MultiLMs in two schemes: (1) where the language of the context and the question remain the same in the new languages that are tested (i.e., the reasoning is still monolingual, but the model must transfer the learned reasoning ability across languages), and (2) where the language of the context and the question is different (which we term code-switched reasoning). On two logical reasoning datasets, RuleTaker and LeapOfThought, we demonstrate that although MultiLMs can transfer reasoning ability across languages in a monolingual setting, they struggle to transfer reasoning abilities in a code-switched setting. Following this observation, we propose a novel attention mechanism that uses a dedicated set of parameters to encourage cross-lingual attention in code-switched sequences, which improves the reasoning performance by up to 14% and 4% on the RuleTaker and LeapOfThought datasets, respectively.
Revisiting Offline Compression: Going Beyond Factorization-based Methods for Transformer Language Models
Feb 08, 2023Recent transformer language models achieve outstanding results in many natural language processing (NLP) tasks. However, their enormous size often makes them impractical on memory-constrained devices, requiring practitioners to compress them to smaller networks. In this paper, we explore offline compression methods, meaning computationally-cheap approaches that do not require further fine-tuning of the compressed model. We challenge the classical matrix factorization methods by proposing a novel, better-performing autoencoder-based framework. We perform a comprehensive ablation study of our approach, examining its different aspects over a diverse set of evaluation settings. Moreover, we show that enabling collaboration between modules across layers by compressing certain modules together positively impacts the final model performance. Experiments on various NLP tasks demonstrate that our approach significantly outperforms commonly used factorization-based offline compression methods.
Discovering Language-neutral Sub-networks in Multilingual Language Models
May 25, 2022



Multilingual pre-trained language models perform remarkably well on cross-lingual transfer for downstream tasks. Despite their impressive performance, our understanding of their language neutrality (i.e., the extent to which they use shared representations to encode similar phenomena across languages) and its role in achieving such performance remain open questions. In this work, we conceptualize language neutrality of multilingual models as a function of the overlap between language-encoding sub-networks of these models. Using mBERT as a foundation, we employ the lottery ticket hypothesis to discover sub-networks that are individually optimized for various languages and tasks. Using three distinct tasks and eleven typologically-diverse languages in our evaluation, we show that the sub-networks found for different languages are in fact quite similar, supporting the idea that mBERT jointly encodes multiple languages in shared parameters. We conclude that mBERT is comprised of a language-neutral sub-network shared among many languages, along with multiple ancillary language-specific sub-networks, with the former playing a more prominent role in mBERT's impressive cross-lingual performance.
AdaGrid: Adaptive Grid Search for Link Prediction Training Objective
Mar 30, 2022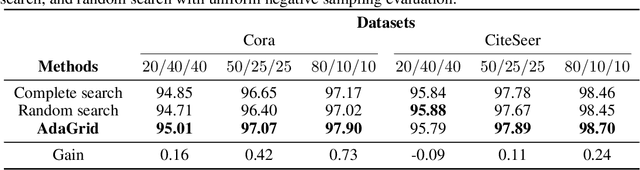
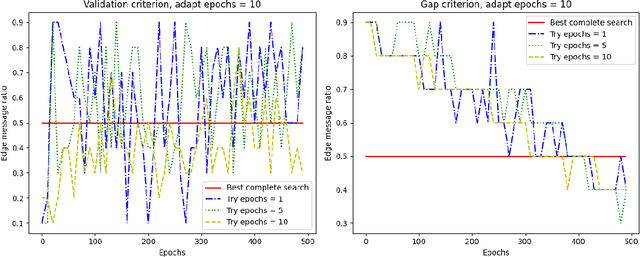

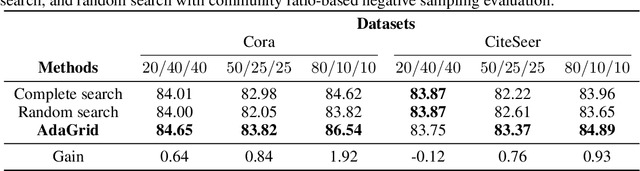
One of the most important factors that contribute to the success of a machine learning model is a good training objective. Training objective crucially influences the model's performance and generalization capabilities. This paper specifically focuses on graph neural network training objective for link prediction, which has not been explored in the existing literature. Here, the training objective includes, among others, a negative sampling strategy, and various hyperparameters, such as edge message ratio which controls how training edges are used. Commonly, these hyperparameters are fine-tuned by complete grid search, which is very time-consuming and model-dependent. To mitigate these limitations, we propose Adaptive Grid Search (AdaGrid), which dynamically adjusts the edge message ratio during training. It is model agnostic and highly scalable with a fully customizable computational budget. Through extensive experiments, we show that AdaGrid can boost the performance of the models up to $1.9\%$ while being nine times more time-efficient than a complete search. Overall, AdaGrid represents an effective automated algorithm for designing machine learning training objectives.
Direction is what you need: Improving Word Embedding Compression in Large Language Models
Jun 15, 2021


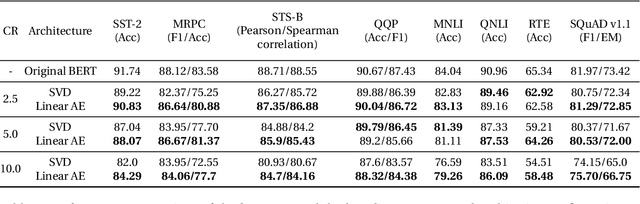
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
Spoken dialect identification in Twitter using a multi-filter architecture
Jun 05, 2020

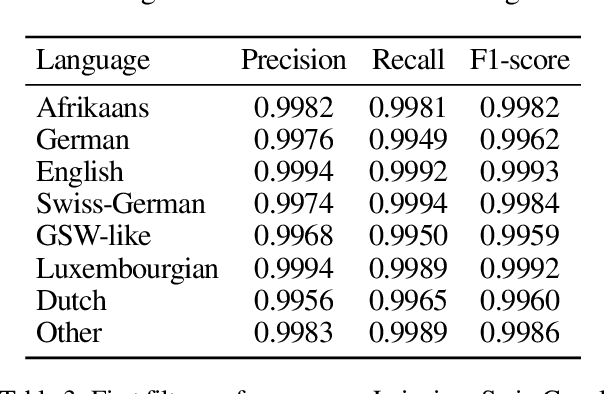
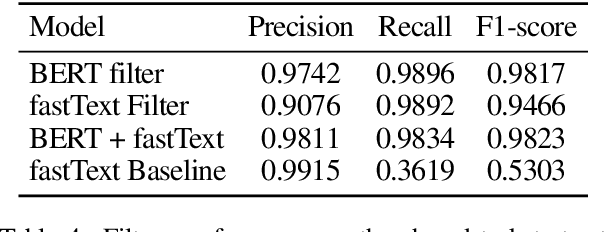
This paper presents our approach for SwissText & KONVENS 2020 shared task 2, which is a multi-stage neural model for Swiss German (GSW) identification on Twitter. Our model outputs either GSW or non-GSW and is not meant to be used as a generic language identifier. Our architecture consists of two independent filters where the first one favors recall, and the second one filter favors precision (both towards GSW). Moreover, we do not use binary models (GSW vs. not-GSW) in our filters but rather a multi-class classifier with GSW being one of the possible labels. Our model reaches F1-score of 0.982 on the test set of the shared task.