 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unlearning to UNBRANDING: A Benchmark for Trademark-Safe Text-to-Image Generation
Dec 15, 2025The rapid progress of text-to-image diffusion models raises significant concerns regarding the unauthorized reproduction of trademarked content. While prior work targets general concepts (e.g., styles, celebrities), it fails to address specific brand identifiers. Crucially, we note that brand recognition is multi-dimensional, extending beyond explicit logos to encompass distinctive structural features (e.g., a car's front grille). To tackle this, we introduce unbranding, a novel task for the fine-grained removal of both trademarks and subtle structural brand features, while preserving semantic coherence. To facilitate research, we construct a comprehensive benchmark dataset. Recognizing that existing brand detectors are limited to logos and fail to capture abstract trade dress (e.g., the shape of a Coca-Cola bottle), we introduce a novel evaluation metric based on Vision Language Models (VLMs). This VLM-based metric uses a question-answering framework to probe images for both explicit logos and implicit, holistic brand characteristics. Furthermore, we observe that as model fidelity increases, with newer systems (SDXL, FLUX) synthesizing brand identifiers more readily than older models (Stable Diffusion), the urgency of the unbranding challenge is starkly highlighted. Our results, validated by our VLM metric, confirm unbranding is a distinct, practically relevant problem requiring specialized techniques. Project Page: https://gmum.github.io/UNBRANDING/.
AutoLoRA: AutoGuidance Meets Low-Rank Adaptation for Diffusion Models
Oct 04, 2024



Low-rank adaptation (LoRA) is a fine-tuning technique that can be applied to conditional generative diffusion models. LoRA utilizes a small number of context examples to adapt the model to a specific domain, character, style, or concept. However, due to the limited data utilized during training, the fine-tuned model performance is often characterized by strong context bias and a low degree of variability in the generated images. To solve this issue, we introduce AutoLoRA, a novel guidance technique for diffusion models fine-tuned with the LoRA approach. Inspired by other guidance techniques, AutoLoRA searches for a trade-off between consistency in the domain represented by LoRA weights and sample diversity from the base conditional diffusion model. Moreover, we show that incorporating classifier-free guidance for both LoRA fine-tuned and base models leads to generating samples with higher diversity and better quality. The experimental results for several fine-tuned LoRA domains show superiority over existing guidance techniques on selected metrics.
Revisiting Offline Compression: Going Beyond Factorization-based Methods for Transformer Language Models
Feb 08, 2023



Recent transformer language models achieve outstanding results in many natural language processing (NLP) tasks. However, their enormous size often makes them impractical on memory-constrained devices, requiring practitioners to compress them to smaller networks. In this paper, we explore offline compression methods, meaning computationally-cheap approaches that do not require further fine-tuning of the compressed model. We challenge the classical matrix factorization methods by proposing a novel, better-performing autoencoder-based framework. We perform a comprehensive ablation study of our approach, examining its different aspects over a diverse set of evaluation settings. Moreover, we show that enabling collaboration between modules across layers by compressing certain modules together positively impacts the final model performance. Experiments on various NLP tasks demonstrate that our approach significantly outperforms commonly used factorization-based offline compression methods.
HyperNeRFGAN: Hypernetwork approach to 3D NeRF GAN
Jan 27, 2023



Recently, generative models for 3D objects are gaining much popularity in VR and augmented reality applications. Training such models using standard 3D representations, like voxels or point clouds, is challenging and requires complex tools for proper color rendering. In order to overcome this limitation, Neural Radiance Fields (NeRFs) offer a state-of-the-art quality in synthesizing novel views of complex 3D scenes from a small subset of 2D images. In the paper, we propose a generative model called HyperNeRFGAN, which uses hypernetworks paradigm to produce 3D objects represented by NeRF. Our GAN architecture leverages a hypernetwork paradigm to transfer gaussian noise into weights of NeRF model. The model is further used to render 2D novel views, and a classical 2D discriminator is utilized for training the entire GAN-based structure. Our architecture produces 2D images, but we use 3D-aware NeRF representation, which forces the model to produce correct 3D objects. The advantage of the model over existing approaches is that it produces a dedicated NeRF representation for the object without sharing some global parameters of the rendering component. We show the superiority of our approach compared to reference baselines on three challenging datasets from various domains.
HyperPocket: Generative Point Cloud Completion
Feb 11, 2021
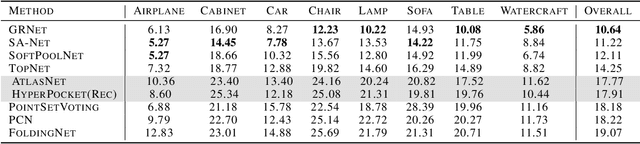
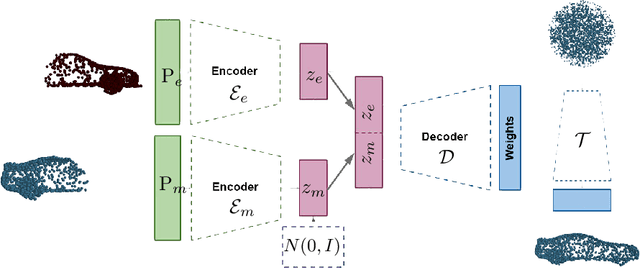
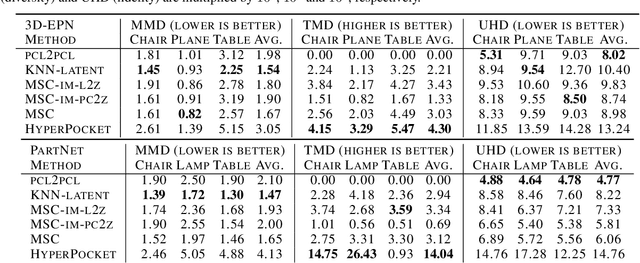
Scanning real-life scenes with modern registration devices typically give incomplete point cloud representations, mostly due to the limitations of the scanning process and 3D occlusions. Therefore, completing such partial representations remains a fundamental challenge of many computer vision applications. Most of the existing approaches aim to solve this problem by learning to reconstruct individual 3D objects in a synthetic setup of an uncluttered environment, which is far from a real-life scenario. In this work, we reformulate the problem of point cloud completion into an object hallucination task. Thus, we introduce a novel autoencoder-based architecture called HyperPocket that disentangles latent representations and, as a result, enables the generation of multiple variants of the completed 3D point clouds. We split point cloud processing into two disjoint data streams and leverage a hypernetwork paradigm to fill the spaces, dubbed pockets, that are left by the missing object parts. As a result, the generated point clouds are not only smooth but also plausible and geometrically consistent with the scene. Our method offers competitive performances to the other state-of-the-art models, and it enables a~plethora of novel applications.