 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREdiSplats: Ray Tracing for Editable Gaussian Splatting
Mar 15, 2025Gaussian Splatting (GS) has become one of the most important neural rendering algorithms. GS represents 3D scenes using Gaussian components with trainable color and opacity. This representation achieves high-quality renderings with fast inference. Regrettably, it is challenging to integrate such a solution with varying light conditions, including shadows and light reflections, manual adjustments, and a physical engine. Recently, a few approaches have appeared that incorporate ray-tracing or mesh primitives into GS to address some of these caveats. However, no such solution can simultaneously solve all the existing limitations of the classical GS. Consequently, we introduce REdiSplats, which employs ray tracing and a mesh-based representation of flat 3D Gaussians. In practice, we model the scene using flat Gaussian distributions parameterized by the mesh. We can leverage fast ray tracing and control Gaussian modification by adjusting the mesh vertices. Moreover, REdiSplats allows modeling of light conditions, manual adjustments, and physical simulation. Furthermore, we can render our models using 3D tools such as Blender or Nvdiffrast, which opens the possibility of integrating them with all existing 3D graphics techniques dedicated to mesh representations.
MeshSplats: Mesh-Based Rendering with Gaussian Splatting Initialization
Feb 11, 2025Gaussian Splatting (GS) is a recent and pivotal technique in 3D computer graphics. GS-based algorithms almost always bypass classical methods such as ray tracing, which offers numerous inherent advantages for rendering. For example, ray tracing is able to handle incoherent rays for advanced lighting effects, including shadows and reflections. To address this limitation, we introduce MeshSplats, a method which converts GS to a mesh-like format. Following the completion of training, MeshSplats transforms Gaussian elements into mesh faces, enabling rendering using ray tracing methods with all their associated benefits. Our model can be utilized immediately following transformation, yielding a mesh of slightly reduced quality without additional training. Furthermore, we can enhance the reconstruction quality through the application of a dedicated optimization algorithm that operates on mesh faces rather than Gaussian components. The efficacy of our method is substantiated by experimental results, underscoring its extensive applications in computer graphics and image processing.
MiraGe: Editable 2D Images using Gaussian Splatting
Oct 02, 2024Implicit Neural Representations (INRs) approximate discrete data through continuous functions and are commonly used for encoding 2D images. Traditional image-based INRs employ neural networks to map pixel coordinates to RGB values, capturing shapes, colors, and textures within the network's weights. Recently, GaussianImage has been proposed as an alternative, using Gaussian functions instead of neural networks to achieve comparable quality and compression. Such a solution obtains a quality and compression ratio similar to classical INR models but does not allow image modification. In contrast, our work introduces a novel method, MiraGe, which uses mirror reflections to perceive 2D images in 3D space and employs flat-controlled Gaussians for precise 2D image editing. Our approach improves the rendering quality and allows realistic image modifications, including human-inspired perception of photos in the 3D world. Thanks to modeling images in 3D space, we obtain the illusion of 3D-based modification in 2D images. We also show that our Gaussian representation can be easily combined with a physics engine to produce physics-based modification of 2D images. Consequently, MiraGe allows for better quality than the standard approach and natural modification of 2D images.
GASP: Gaussian Splatting for Physic-Based Simulations
Sep 09, 2024Physics simulation is paramount for modeling and utilization of 3D scenes in various real-world applications. However, its integration with state-of-the-art 3D scene rendering techniques such as Gaussian Splatting (GS) remains challenging. Existing models use additional meshing mechanisms, including triangle or tetrahedron meshing, marching cubes, or cage meshes. As an alternative, we can modify the physics grounded Newtonian dynamics to align with 3D Gaussian components. Current models take the first-order approximation of a deformation map, which locally approximates the dynamics by linear transformations. In contrast, our Gaussian Splatting for Physics-Based Simulations (GASP) model uses such a map (without any modifications) and flat Gaussian distributions, which are parameterized by three points (mesh faces). Subsequently, each 3D point (mesh face node) is treated as a discrete entity within a 3D space. Consequently, the problem of modeling Gaussian components is reduced to working with 3D points. Additionally, the information on mesh faces can be used to incorporate further properties into the physics model, facilitating the use of triangles. Resulting solution can be integrated into any physics engine that can be treated as a black box. As demonstrated in our studies, the proposed model exhibits superior performance on a diverse range of benchmark datasets designed for 3D object rendering.
D-MiSo: Editing Dynamic 3D Scenes using Multi-Gaussians Soup
May 23, 2024Over the past years, we have observed an abundance of approaches for modeling dynamic 3D scenes using Gaussian Splatting (GS). Such solutions use GS to represent the scene's structure and the neural network to model dynamics. Such approaches allow fast rendering and extracting each element of such a dynamic scene. However, modifying such objects over time is challenging. SC-GS (Sparse Controlled Gaussian Splatting) enhanced with Deformed Control Points partially solves this issue. However, this approach necessitates selecting elements that need to be kept fixed, as well as centroids that should be adjusted throughout editing. Moreover, this task poses additional difficulties regarding the re-productivity of such editing. To address this, we propose Dynamic Multi-Gaussian Soup (D-MiSo), which allows us to model the mesh-inspired representation of dynamic GS. Additionally, we propose a strategy of linking parameterized Gaussian splats, forming a Triangle Soup with the estimated mesh. Consequently, we can separately construct new trajectories for the 3D objects composing the scene. Thus, we can make the scene's dynamic editable over time or while maintaining partial dynamics.
GaMeS: Mesh-Based Adapting and Modification of Gaussian Splatting
Feb 15, 2024



Recently, a range of neural network-based methods for image rendering have been introduced. One such widely-researched neural radiance field (NeRF) relies on a neural network to represent 3D scenes, allowing for realistic view synthesis from a small number of 2D images. However, most NeRF models are constrained by long training and inference times. In comparison, Gaussian Splatting (GS) is a novel, state-of-the-art technique for rendering points in a 3D scene by approximating their contribution to image pixels through Gaussian distributions, warranting fast training and swift, real-time rendering. A drawback of GS is the absence of a well-defined approach for its conditioning due to the necessity to condition several hundred thousand Gaussian components. To solve this, we introduce the Gaussian Mesh Splatting (GaMeS) model, which allows modification of Gaussian components in a similar way as meshes. We parameterize each Gaussian component by the vertices of the mesh face. Furthermore, our model needs mesh initialization on input or estimated mesh during training. We also define Gaussian splats solely based on their location on the mesh, allowing for automatic adjustments in position, scale, and rotation during animation. As a result, we obtain a real-time rendering of editable GS.
ImplicitDeepfake: Plausible Face-Swapping through Implicit Deepfake Generation using NeRF and Gaussian Splatting
Feb 09, 2024Numerous emerging deep-learning techniques have had a substantial impact on computer graphics. Among the most promising breakthroughs are the recent rise of Neural Radiance Fields (NeRFs) and Gaussian Splatting (GS). NeRFs encode the object's shape and color in neural network weights using a handful of images with known camera positions to generate novel views. In contrast, GS provides accelerated training and inference without a decrease in rendering quality by encoding the object's characteristics in a collection of Gaussian distributions. These two techniques have found many use cases in spatial computing and other domains. On the other hand, the emergence of deepfake methods has sparked considerable controversy. Such techniques can have a form of artificial intelligence-generated videos that closely mimic authentic footage. Using generative models, they can modify facial features, enabling the creation of altered identities or facial expressions that exhibit a remarkably realistic appearance to a real person. Despite these controversies, deepfake can offer a next-generation solution for avatar creation and gaming when of desirable quality. To that end, we show how to combine all these emerging technologies to obtain a more plausible outcome. Our ImplicitDeepfake1 uses the classical deepfake algorithm to modify all training images separately and then train NeRF and GS on modified faces. Such relatively simple strategies can produce plausible 3D deepfake-based avatars.
HyperPlanes: Hypernetwork Approach to Rapid NeRF Adaptation
Feb 02, 2024Neural radiance fields (NeRFs) are a widely accepted standard for synthesizing new 3D object views from a small number of base images. However, NeRFs have limited generalization properties, which means that we need to use significant computational resources to train individual architectures for each item we want to represent. To address this issue, we propose a few-shot learning approach based on the hypernetwork paradigm that does not require gradient optimization during inference. The hypernetwork gathers information from the training data and generates an update for universal weights. As a result, we have developed an efficient method for generating a high-quality 3D object representation from a small number of images in a single step. This has been confirmed by direct comparison with the state-of-the-art solutions and a comprehensive ablation study.
Gaussian Splatting with NeRF-based Color and Opacity
Dec 22, 2023Neural Radiance Fields (NeRFs) have demonstrated the remarkable potential of neural networks to capture the intricacies of 3D objects. By encoding the shape and color information within neural network weights, NeRFs excel at producing strikingly sharp novel views of 3D objects. Recently, numerous generalizations of NeRFs utilizing generative models have emerged, expanding its versatility. In contrast, Gaussian Splatting (GS) offers a similar renders quality with faster training and inference as it does not need neural networks to work. We encode information about the 3D objects in the set of Gaussian distributions that can be rendered in 3D similarly to classical meshes. Unfortunately, GS are difficult to condition since they usually require circa hundred thousand Gaussian components. To mitigate the caveats of both models, we propose a hybrid model that uses GS representation of the 3D object's shape and NeRF-based encoding of color and opacity. Our model uses Gaussian distributions with trainable positions (i.e. means of Gaussian), shape (i.e. covariance of Gaussian), color and opacity, and neural network, which takes parameters of Gaussian and viewing direction to produce changes in color and opacity. Consequently, our model better describes shadows, light reflections, and transparency of 3D objects.
HyperPocket: Generative Point Cloud Completion
Feb 11, 2021
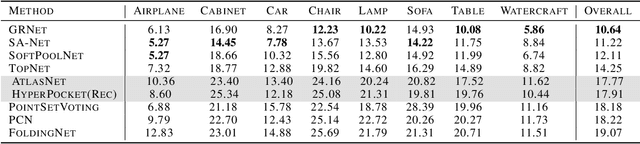
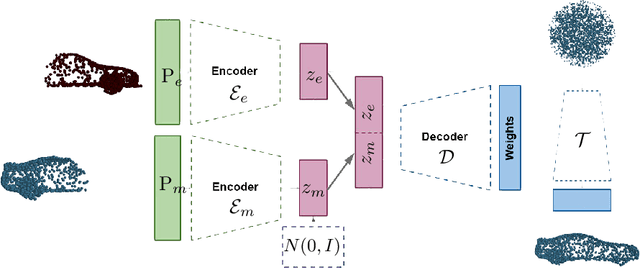
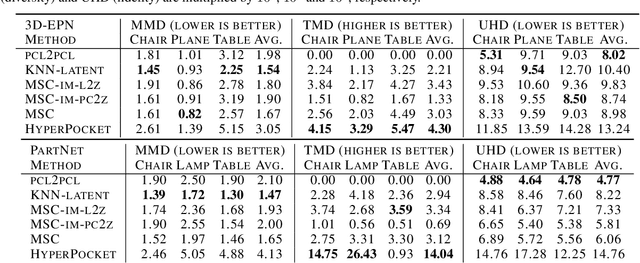
Scanning real-life scenes with modern registration devices typically give incomplete point cloud representations, mostly due to the limitations of the scanning process and 3D occlusions. Therefore, completing such partial representations remains a fundamental challenge of many computer vision applications. Most of the existing approaches aim to solve this problem by learning to reconstruct individual 3D objects in a synthetic setup of an uncluttered environment, which is far from a real-life scenario. In this work, we reformulate the problem of point cloud completion into an object hallucination task. Thus, we introduce a novel autoencoder-based architecture called HyperPocket that disentangles latent representations and, as a result, enables the generation of multiple variants of the completed 3D point clouds. We split point cloud processing into two disjoint data streams and leverage a hypernetwork paradigm to fill the spaces, dubbed pockets, that are left by the missing object parts. As a result, the generated point clouds are not only smooth but also plausible and geometrically consistent with the scene. Our method offers competitive performances to the other state-of-the-art models, and it enables a~plethora of novel applications.