 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaRRTa: A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models
Jan 16, 2026Visual Foundation Models (VFMs), such as DINO and CLIP, excel in semantic understanding of images but exhibit limited spatial reasoning capabilities, which limits their applicability to embodied systems. As a result, recent work incorporates some 3D tasks (such as depth estimation) into VFM training. However, VFM performance remains inconsistent across other spatial tasks, raising the question of whether these models truly have spatial awareness or overfit to specific 3D objectives. To address this question, we introduce the Spatial Relation Recognition Task (SpaRRTa) benchmark, which evaluates the ability of VFMs to identify relative positions of objects in the image. Unlike traditional 3D objectives that focus on precise metric prediction (e.g., surface normal estimation), SpaRRTa probes a fundamental capability underpinning more advanced forms of human-like spatial understanding. SpaRRTa generates an arbitrary number of photorealistic images with diverse scenes and fully controllable object arrangements, along with freely accessible spatial annotations. Evaluating a range of state-of-the-art VFMs, we reveal significant disparities between their spatial reasoning abilities. Through our analysis, we provide insights into the mechanisms that support or hinder spatial awareness in modern VFMs. We hope that SpaRRTa will serve as a useful tool for guiding the development of future spatially aware visual models.
Beyond [cls]: Exploring the true potential of Masked Image Modeling representations
Dec 04, 2024![Figure 1 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F2-Figure2-1.png&w=640&q=75)
![Figure 4 for Beyond [cls]: Exploring the true potential of Masked Image Modeling representations](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fbbd7b95f369373c48661518f9d0e2d97c488caf2%2F13-Table2-1.png&w=640&q=75)
Masked Image Modeling (MIM) has emerged as a popular method for Self-Supervised Learning (SSL) of visual representations. However, for high-level perception tasks, MIM-pretrained models offer lower out-of-the-box representation quality than the Joint-Embedding Architectures (JEA) - another prominent SSL paradigm. To understand this performance gap, we analyze the information flow in Vision Transformers (ViT) learned by both approaches. We reveal that whereas JEAs construct their representation on a selected set of relevant image fragments, MIM models aggregate nearly whole image content. Moreover, we demonstrate that MIM-trained ViTs retain valuable information within their patch tokens, which is not effectively captured by the global [cls] token representations. Therefore, selective aggregation of relevant patch tokens, without any fine-tuning, results in consistently higher-quality of MIM representations. To our knowledge, we are the first to highlight the lack of effective representation aggregation as an emergent issue of MIM and propose directions to address it, contributing to future advances in Self-Supervised Learning.
A deep cut into Split Federated Self-supervised Learning
Jun 12, 2024Collaborative self-supervised learning has recently become feasible in highly distributed environments by dividing the network layers between client devices and a central server. However, state-of-the-art methods, such as MocoSFL, are optimized for network division at the initial layers, which decreases the protection of the client data and increases communication overhead. In this paper, we demonstrate that splitting depth is crucial for maintaining privacy and communication efficiency in distributed training. We also show that MocoSFL suffers from a catastrophic quality deterioration for the minimal communication overhead. As a remedy, we introduce Momentum-Aligned contrastive Split Federated Learning (MonAcoSFL), which aligns online and momentum client models during training procedure. Consequently, we achieve state-of-the-art accuracy while significantly reducing the communication overhead, making MonAcoSFL more practical in real-world scenarios.
HyperPlanes: Hypernetwork Approach to Rapid NeRF Adaptation
Feb 02, 2024Neural radiance fields (NeRFs) are a widely accepted standard for synthesizing new 3D object views from a small number of base images. However, NeRFs have limited generalization properties, which means that we need to use significant computational resources to train individual architectures for each item we want to represent. To address this issue, we propose a few-shot learning approach based on the hypernetwork paradigm that does not require gradient optimization during inference. The hypernetwork gathers information from the training data and generates an update for universal weights. As a result, we have developed an efficient method for generating a high-quality 3D object representation from a small number of images in a single step. This has been confirmed by direct comparison with the state-of-the-art solutions and a comprehensive ablation study.
Adapt Your Teacher: Improving Knowledge Distillation for Exemplar-free Continual Learning
Aug 18, 2023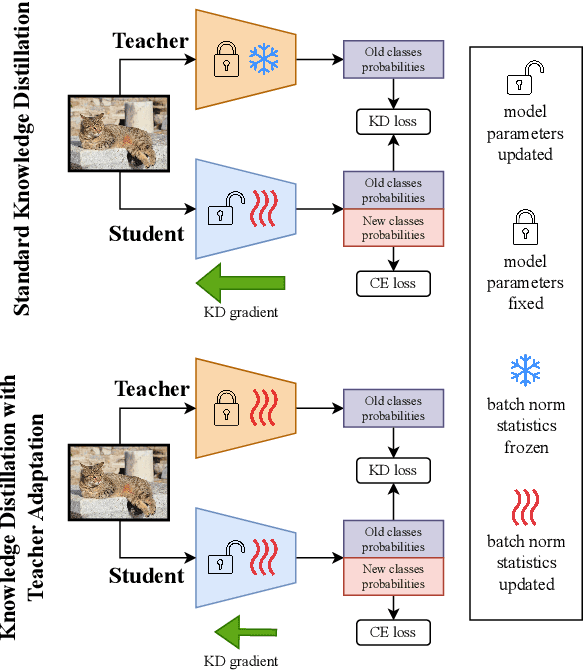
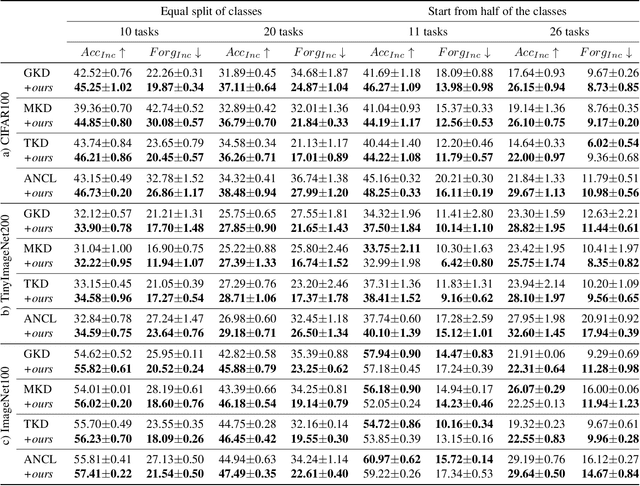
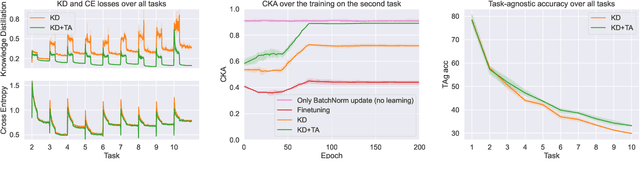
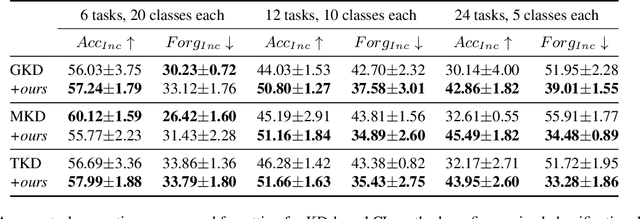
In this work, we investigate exemplar-free class incremental learning (CIL) with knowledge distillation (KD) as a regularization strategy, aiming to prevent forgetting. KD-based methods are successfully used in CIL, but they often struggle to regularize the model without access to exemplars of the training data from previous tasks. Our analysis reveals that this issue originates from substantial representation shifts in the teacher network when dealing with out-of-distribution data. This causes large errors in the KD loss component, leading to performance degradation in CIL. Inspired by recent test-time adaptation methods, we introduce Teacher Adaptation (TA), a method that concurrently updates the teacher and the main model during incremental training. Our method seamlessly integrates with KD-based CIL approaches and allows for consistent enhancement of their performance across multiple exemplar-free CIL benchmarks.
Augmentation-aware Self-supervised Learning with Guided Projector
May 31, 2023



Self-supervised learning (SSL) is a powerful technique for learning robust representations from unlabeled data. By learning to remain invariant to applied data augmentations, methods such as SimCLR and MoCo are able to reach quality on par with supervised approaches. However, this invariance may be harmful to solving some downstream tasks which depend on traits affected by augmentations used during pretraining, such as color. In this paper, we propose to foster sensitivity to such characteristics in the representation space by modifying the projector network, a common component of self-supervised architectures. Specifically, we supplement the projector with information about augmentations applied to images. In order for the projector to take advantage of this auxiliary guidance when solving the SSL task, the feature extractor learns to preserve the augmentation information in its representations. Our approach, coined Conditional Augmentation-aware Selfsupervised Learning (CASSLE), is directly applicable to typical joint-embedding SSL methods regardless of their objective functions. Moreover, it does not require major changes in the network architecture or prior knowledge of downstream tasks. In addition to an analysis of sensitivity towards different data augmentations, we conduct a series of experiments, which show that CASSLE improves over various SSL methods, reaching state-of-the-art performance in multiple downstream tasks.
Hypernetwork approach to Bayesian MAML
Oct 06, 2022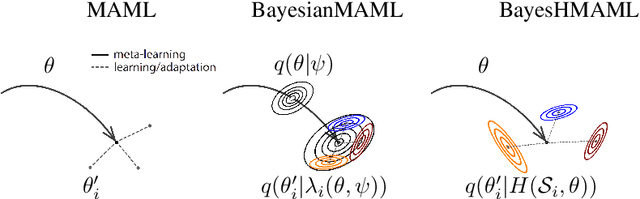
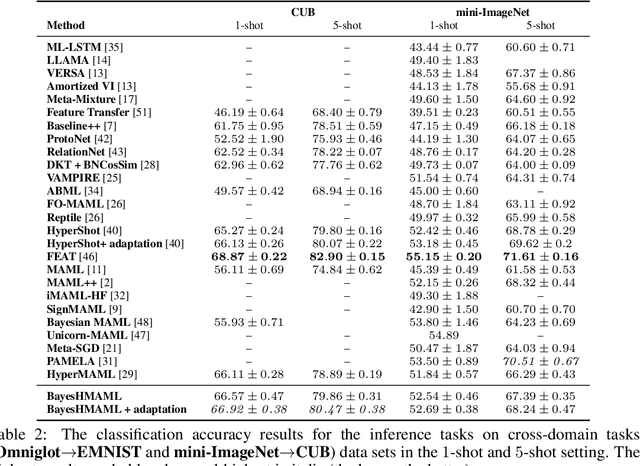
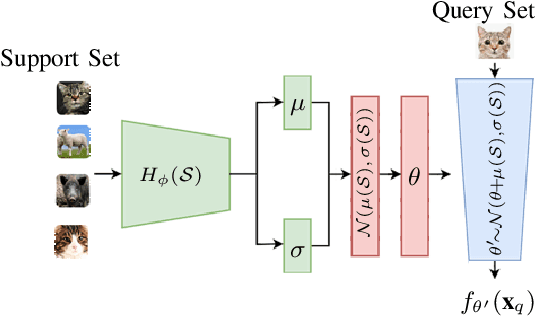
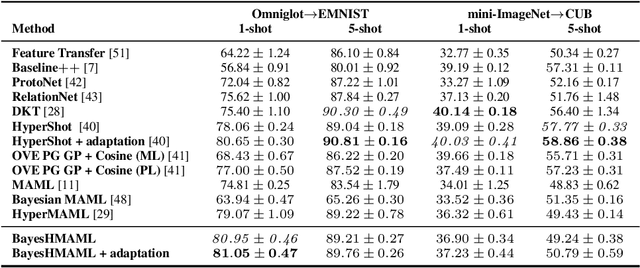
The main goal of Few-Shot learning algorithms is to enable learning from small amounts of data. One of the most popular and elegant Few-Shot learning approaches is Model-Agnostic Meta-Learning (MAML). The main idea behind this method is to learn shared universal weights of a meta-model, which then are adapted for specific tasks. However, due to limited data size, the method suffers from over-fitting and poorly quantifies uncertainty. Bayesian approaches could, in principle, alleviate these shortcomings by learning weight distributions in place of point-wise weights. Unfortunately, previous Bayesian modifications of MAML are limited in a way similar to the classic MAML, e.g., task-specific adaptations must share the same structure and can not diverge much from the universal meta-model. Additionally, task-specific distributions are considered as posteriors to the universal distributions working as priors, and optimizing them jointly with gradients is hard and poses a risk of getting stuck in local optima. In this paper, we propose BayesianHyperShot, a novel generalization of Bayesian MAML, which employs Bayesian principles along with Hypernetworks for MAML. We achieve better convergence than the previous methods by classically learning universal weights. Furthermore, Bayesian treatment of the specific tasks enables uncertainty quantification, and high flexibility of task adaptations is achieved using Hypernetworks instead of gradient-based updates. Consequently, the proposed approach not only improves over the previous methods, both classic and Bayesian MAML in several standard Few-Shot learning benchmarks but also benefits from the properties of the Bayesian framework.
HyperShot: Few-Shot Learning by Kernel HyperNetworks
Mar 21, 2022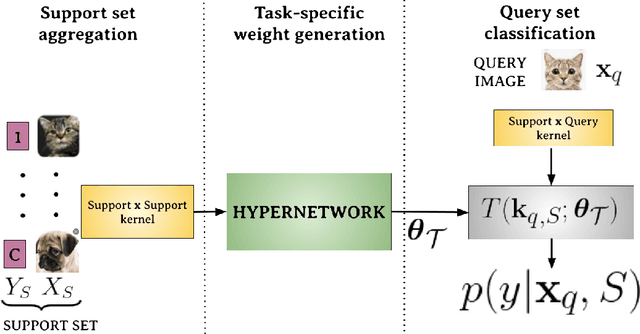
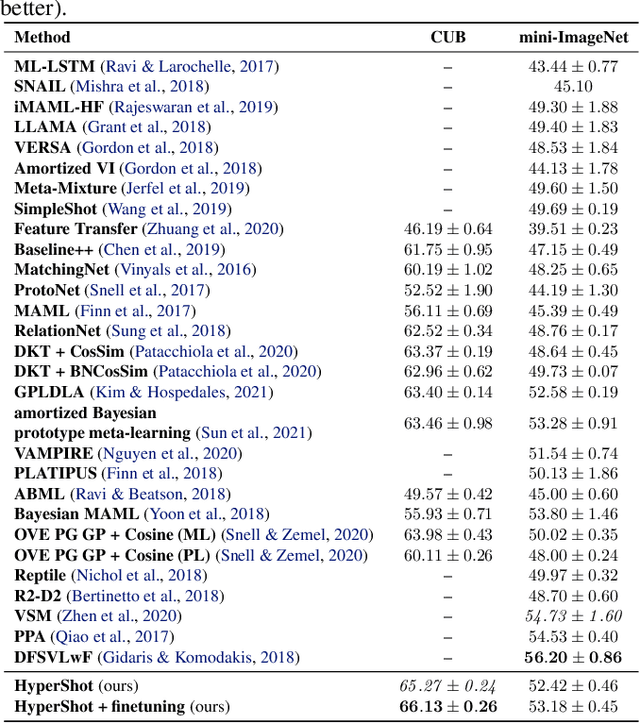
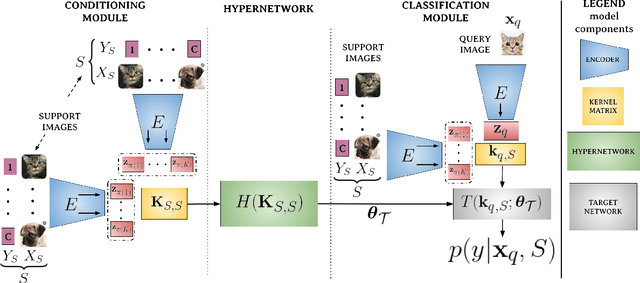
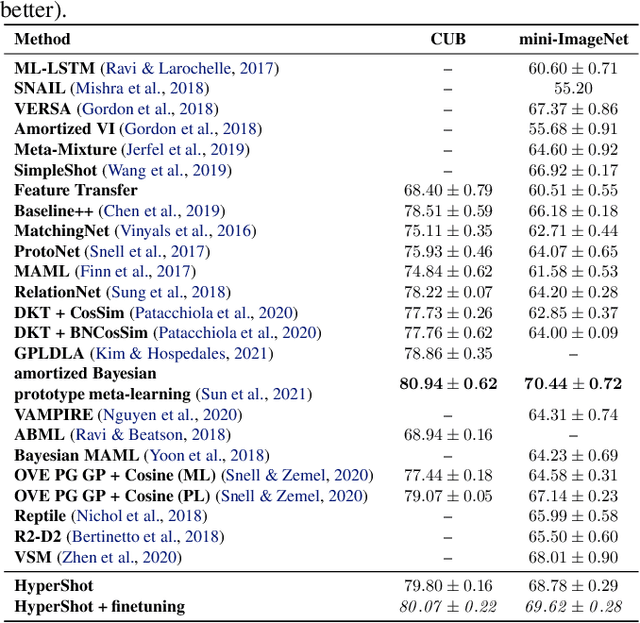
Few-shot models aim at making predictions using a minimal number of labeled examples from a given task. The main challenge in this area is the one-shot setting where only one element represents each class. We propose HyperShot - the fusion of kernels and hypernetwork paradigm. Compared to reference approaches that apply a gradient-based adjustment of the parameters, our model aims to switch the classification module parameters depending on the task's embedding. In practice, we utilize a hypernetwork, which takes the aggregated information from support data and returns the classifier's parameters handcrafted for the considered problem. Moreover, we introduce the kernel-based representation of the support examples delivered to hypernetwork to create the parameters of the classification module. Consequently, we rely on relations between embeddings of the support examples instead of direct feature values provided by the backbone models. Thanks to this approach, our model can adapt to highly different tasks.
MisConv: Convolutional Neural Networks for Missing Data
Oct 29, 2021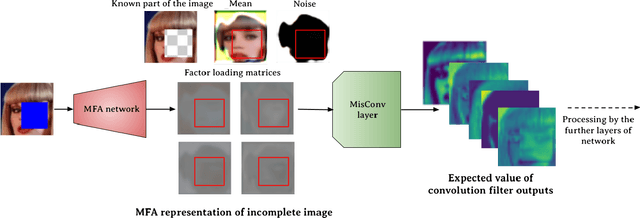
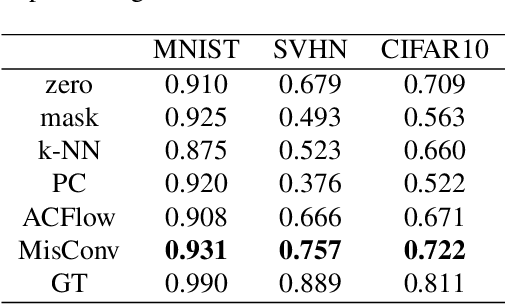


Processing of missing data by modern neural networks, such as CNNs, remains a fundamental, yet unsolved challenge, which naturally arises in many practical applications, like image inpainting or autonomous vehicles and robots. While imputation-based techniques are still one of the most popular solutions, they frequently introduce unreliable information to the data and do not take into account the uncertainty of estimation, which may be destructive for a machine learning model. In this paper, we present MisConv, a general mechanism, for adapting various CNN architectures to process incomplete images. By modeling the distribution of missing values by the Mixture of Factor Analyzers, we cover the spectrum of possible replacements and find an analytical formula for the expected value of convolution operator applied to the incomplete image. The whole framework is realized by matrix operations, which makes MisConv extremely efficient in practice. Experiments performed on various image processing tasks demonstrate that MisConv achieves superior or comparable performance to the state-of-the-art methods.
RegFlow: Probabilistic Flow-based Regression for Future Prediction
Nov 30, 2020
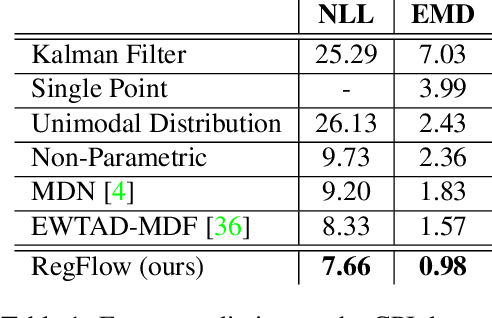
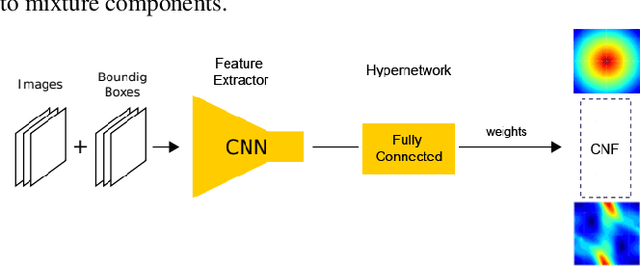
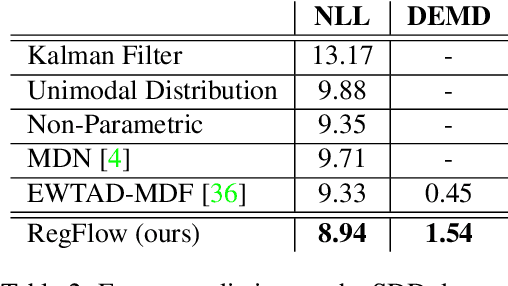
Predicting future states or actions of a given system remains a fundamental, yet unsolved challenge of intelligence, especially in the scope of complex and non-deterministic scenarios, such as modeling behavior of humans. Existing approaches provide results under strong assumptions concerning unimodality of future states, or, at best, assuming specific probability distributions that often poorly fit to real-life conditions. In this work we introduce a robust and flexible probabilistic framework that allows to model future predictions with virtually no constrains regarding the modality or underlying probability distribution. To achieve this goal, we leverage a hypernetwork architecture and train a continuous normalizing flow model. The resulting method dubbed RegFlow achieves state-of-the-art results on several benchmark datasets, outperforming competing approaches by a significant margin.