 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Flow Networks in Continual Learning
Oct 18, 2023Bayesian Flow Networks (BFNs) has been recently proposed as one of the most promising direction to universal generative modelling, having ability to learn any of the data type. Their power comes from the expressiveness of neural networks and Bayesian inference which make them suitable in the context of continual learning. We delve into the mechanics behind BFNs and conduct the experiments to empirically verify the generative capabilities on non-stationary data.
Adapt Your Teacher: Improving Knowledge Distillation for Exemplar-free Continual Learning
Aug 18, 2023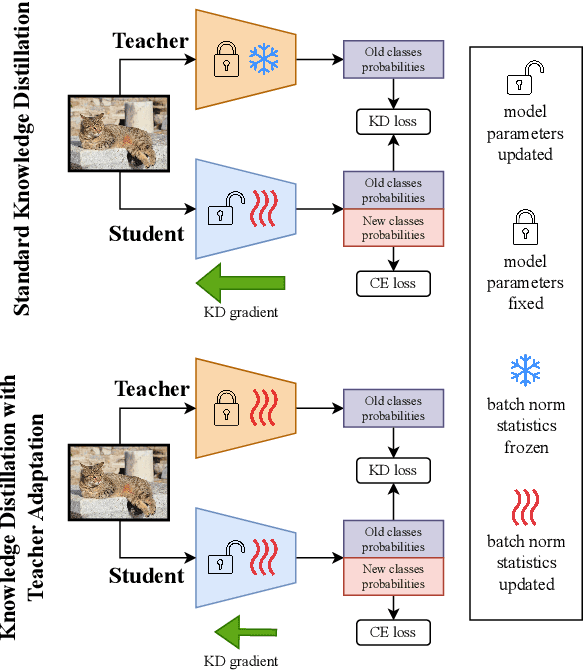
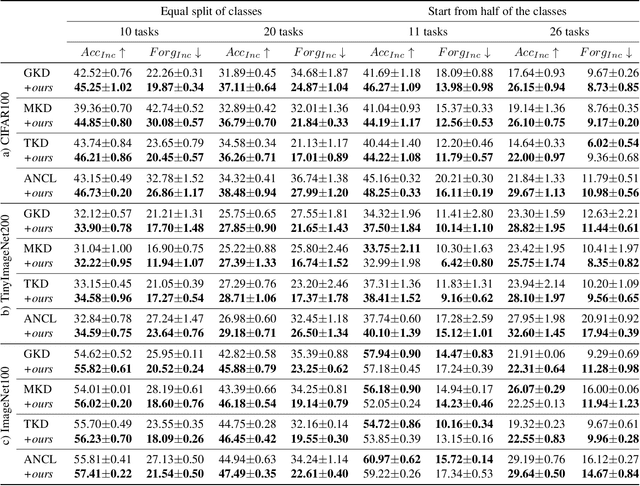
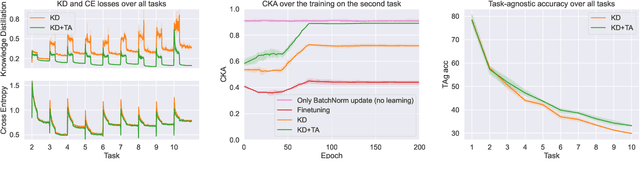
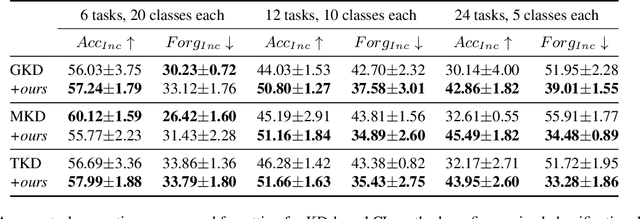
In this work, we investigate exemplar-free class incremental learning (CIL) with knowledge distillation (KD) as a regularization strategy, aiming to prevent forgetting. KD-based methods are successfully used in CIL, but they often struggle to regularize the model without access to exemplars of the training data from previous tasks. Our analysis reveals that this issue originates from substantial representation shifts in the teacher network when dealing with out-of-distribution data. This causes large errors in the KD loss component, leading to performance degradation in CIL. Inspired by recent test-time adaptation methods, we introduce Teacher Adaptation (TA), a method that concurrently updates the teacher and the main model during incremental training. Our method seamlessly integrates with KD-based CIL approaches and allows for consistent enhancement of their performance across multiple exemplar-free CIL benchmarks.
Augmentation-aware Self-supervised Learning with Guided Projector
May 31, 2023



Self-supervised learning (SSL) is a powerful technique for learning robust representations from unlabeled data. By learning to remain invariant to applied data augmentations, methods such as SimCLR and MoCo are able to reach quality on par with supervised approaches. However, this invariance may be harmful to solving some downstream tasks which depend on traits affected by augmentations used during pretraining, such as color. In this paper, we propose to foster sensitivity to such characteristics in the representation space by modifying the projector network, a common component of self-supervised architectures. Specifically, we supplement the projector with information about augmentations applied to images. In order for the projector to take advantage of this auxiliary guidance when solving the SSL task, the feature extractor learns to preserve the augmentation information in its representations. Our approach, coined Conditional Augmentation-aware Selfsupervised Learning (CASSLE), is directly applicable to typical joint-embedding SSL methods regardless of their objective functions. Moreover, it does not require major changes in the network architecture or prior knowledge of downstream tasks. In addition to an analysis of sensitivity towards different data augmentations, we conduct a series of experiments, which show that CASSLE improves over various SSL methods, reaching state-of-the-art performance in multiple downstream tasks.