 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumiGauss: High-Fidelity Outdoor Relighting with 2D Gaussian Splatting
Aug 06, 2024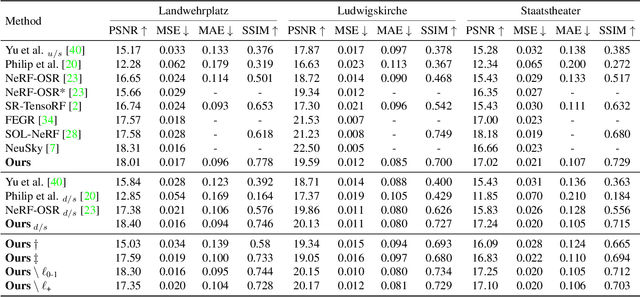
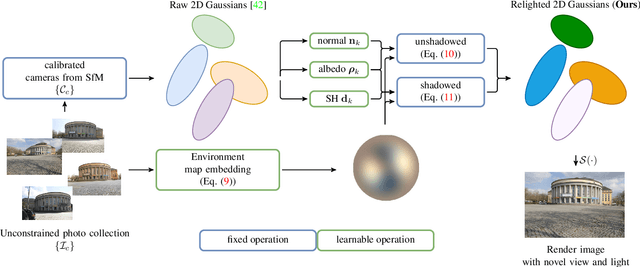

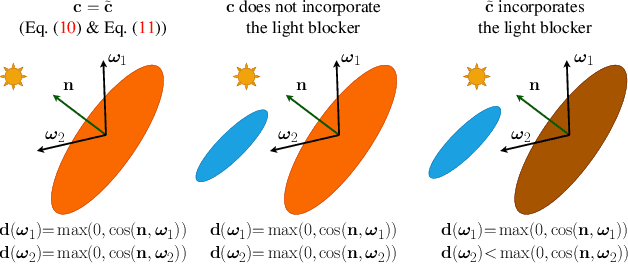
Decoupling lighting from geometry using unconstrained photo collections is notoriously challenging. Solving it would benefit many users, as creating complex 3D assets takes days of manual labor. Many previous works have attempted to address this issue, often at the expense of output fidelity, which questions the practicality of such methods. We introduce LumiGauss, a technique that tackles 3D reconstruction of scenes and environmental lighting through 2D Gaussian Splatting. Our approach yields high-quality scene reconstructions and enables realistic lighting synthesis under novel environment maps. We also propose a method for enhancing the quality of shadows, common in outdoor scenes, by exploiting spherical harmonics properties. Our approach facilitates seamless integration with game engines and enables the use of fast precomputed radiance transfer. We validate our method on the NeRF-OSR dataset, demonstrating superior performance over baseline methods. Moreover, LumiGauss can synthesize realistic images when applying novel environment maps.
Noninvasive Estimation of Mean Pulmonary Artery Pressure Using MRI, Computer Models, and Machine Learning
Dec 21, 2023Pulmonary Hypertension (PH) is a severe disease characterized by an elevated pulmonary artery pressure. The gold standard for PH diagnosis is measurement of mean Pulmonary Artery Pressure (mPAP) during an invasive Right Heart Catheterization. In this paper, we investigate noninvasive approach to PH detection utilizing Magnetic Resonance Imaging, Computer Models and Machine Learning. We show using the ablation study, that physics-informed feature engineering based on models of blood circulation increases the performance of Gradient Boosting Decision Trees-based algorithms for classification of PH and regression of values of mPAP. We compare results of regression (with thresholding of estimated mPAP) and classification and demonstrate that metrics achieved in both experiments are comparable. The predicted mPAP values are more informative to the physicians than the probability of PH returned by classification models. They provide the intuitive explanation of the outcome of the machine learning model (clinicians are accustomed to the mPAP metric, contrary to the PH probability).
Learning Data Representations with Joint Diffusion Models
Jan 31, 2023
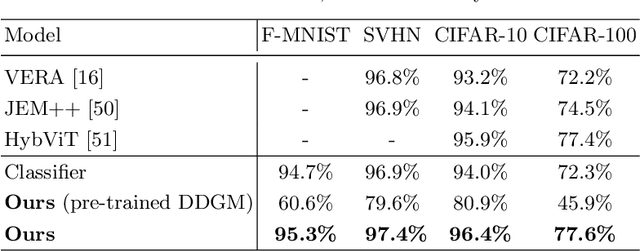


We introduce a joint diffusion model that simultaneously learns meaningful internal representations fit for both generative and predictive tasks. Joint machine learning models that allow synthesizing and classifying data often offer uneven performance between those tasks or are unstable to train. In this work, we depart from a set of empirical observations that indicate the usefulness of internal representations built by contemporary deep diffusion-based generative models in both generative and predictive settings. We then introduce an extension of the vanilla diffusion model with a classifier that allows for stable joint training with shared parametrization between those objectives. The resulting joint diffusion model offers superior performance across various tasks, including generative modeling, semi-supervised classification, and domain adaptation.
A Deep Learning Approach for Automatic Detection of Qualitative Features of Lecturing
May 30, 2022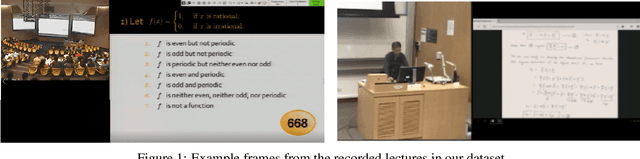
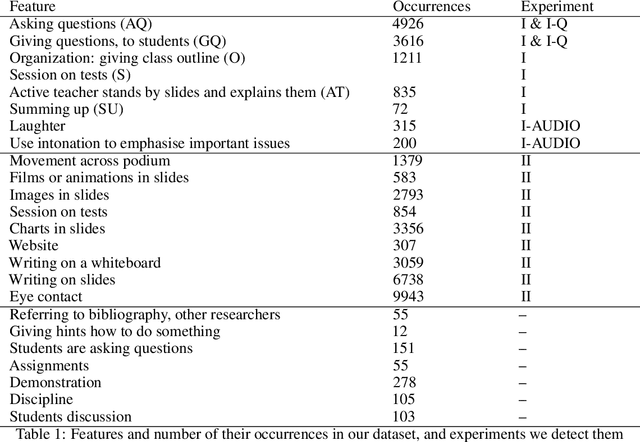
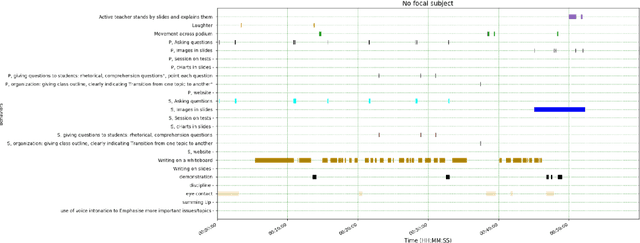
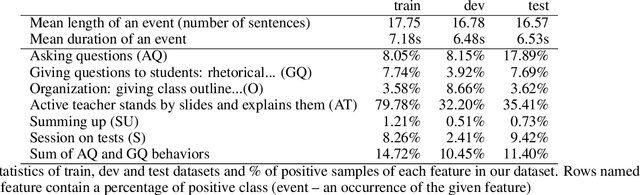
Artificial Intelligence in higher education opens new possibilities for improving the lecturing process, such as enriching didactic materials, helping in assessing students' works or even providing directions to the teachers on how to enhance the lectures. We follow this research path, and in this work, we explore how an academic lecture can be assessed automatically by quantitative features. First, we prepare a set of qualitative features based on teaching practices and then annotate the dataset of academic lecture videos collected for this purpose. We then show how these features could be detected automatically using machine learning and computer vision techniques. Our results show the potential usefulness of our work.
EgoNN: Egocentric Neural Network for Point Cloud Based 6DoF Relocalization at the City Scale
Oct 24, 2021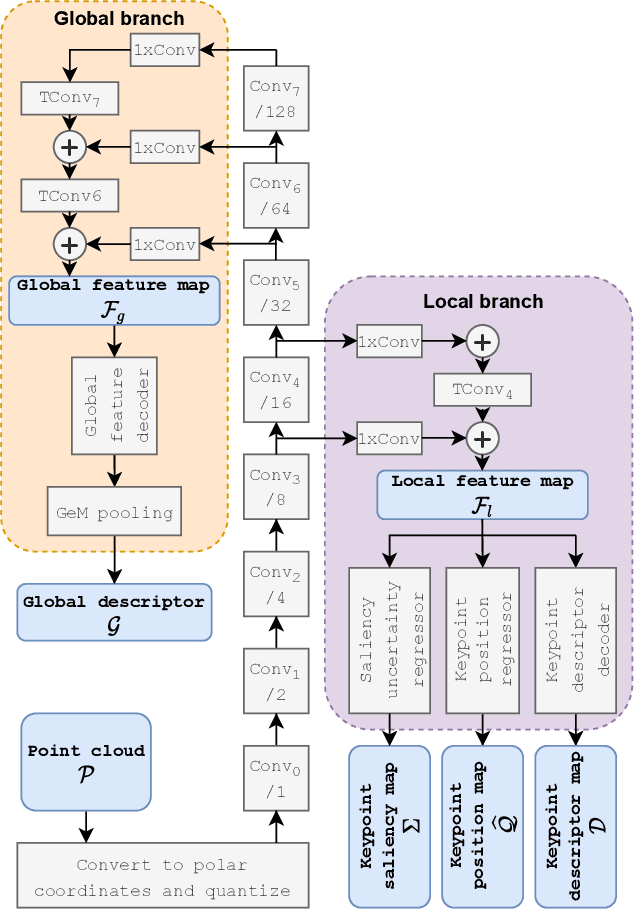
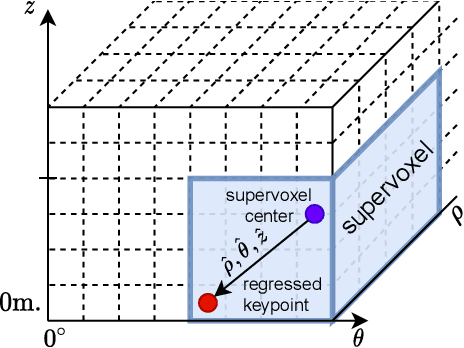
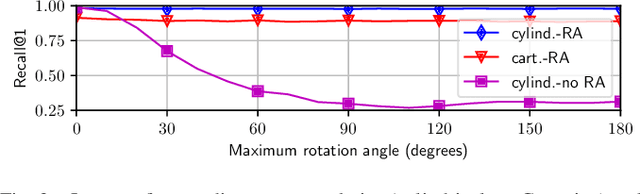

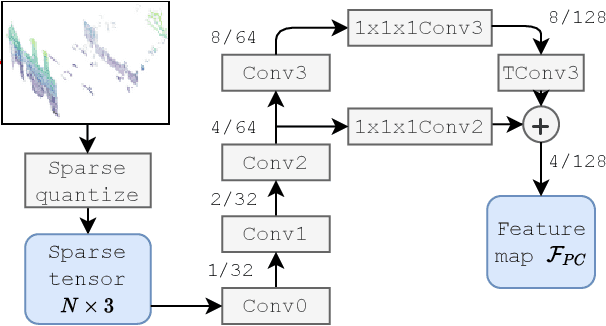
The paper presents a deep neural network-based method for global and local descriptors extraction from a point cloud acquired by a rotating 3D LiDAR. The descriptors can be used for two-stage 6DoF relocalization. First, a course position is retrieved by finding candidates with the closest global descriptor in the database of geo-tagged point clouds. Then, the 6DoF pose between a query point cloud and a database point cloud is estimated by matching local descriptors and using a robust estimator such as RANSAC. Our method has a simple, fully convolutional architecture based on a sparse voxelized representation. It can efficiently extract a global descriptor and a set of keypoints with local descriptors from large point clouds with tens of thousand points. Our code and pretrained models are publicly available on the project website.
Large-Scale Topological Radar Localization Using Learned Descriptors
Oct 06, 2021



In this work, we propose a method for large-scale topological localization based on radar scan images using learned descriptors. We present a simple yet efficient deep network architecture to compute a rotationally invariant discriminative global descriptor from a radar scan image. The performance and generalization ability of the proposed method is experimentally evaluated on two large scale driving datasets: MulRan and Oxford Radar RobotCar. Additionally, we present a comparative evaluation of radar-based and LiDAR-based localization using learned global descriptors. Our code and trained models are publicly available on the project website.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 14, 2021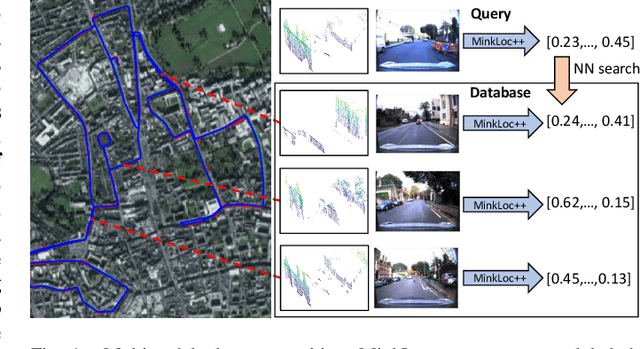
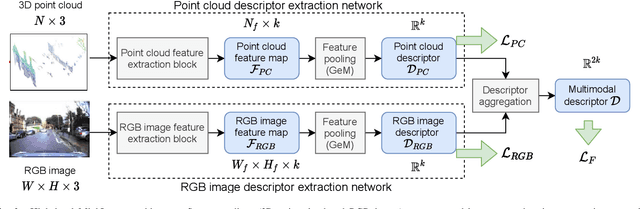

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLocMultimodal.
I Want This Product but Different : Multimodal Retrieval with Synthetic Query Expansion
Feb 17, 2021

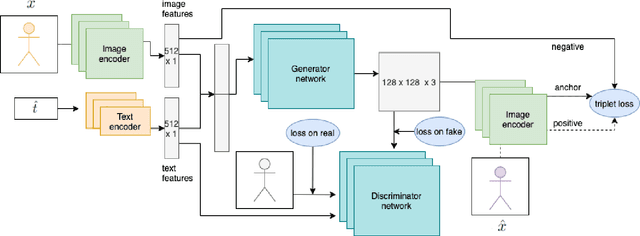
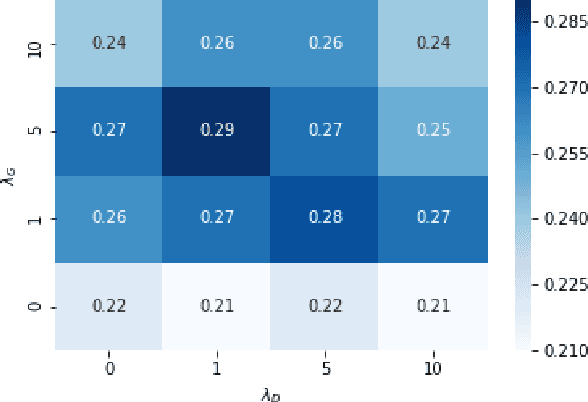
This paper addresses the problem of media retrieval using a multimodal query (a query which combines visual input with additional semantic information in natural language feedback). We propose a SynthTriplet GAN framework which resolves this task by expanding the multimodal query with a synthetically generated image that captures semantic information from both image and text input. We introduce a novel triplet mining method that uses a synthetic image as an anchor to directly optimize for embedding distances of generated and target images. We demonstrate that apart from the added value of retrieval illustration with synthetic image with the focus on customization and user feedback, the proposed method greatly surpasses other multimodal generation methods and achieves state of the art results in the multimodal retrieval task. We also show that in contrast to other retrieval methods, our method provides explainable embeddings.
RegFlow: Probabilistic Flow-based Regression for Future Prediction
Nov 30, 2020
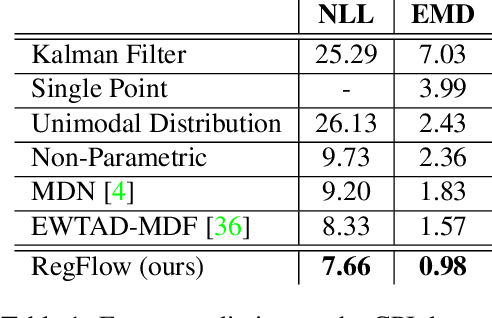
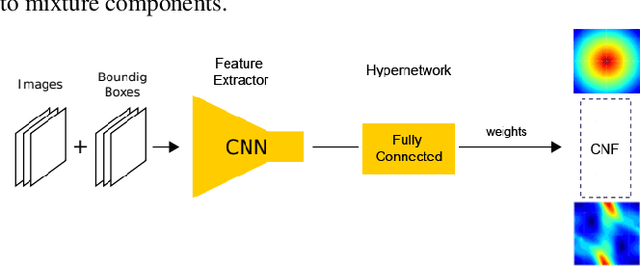
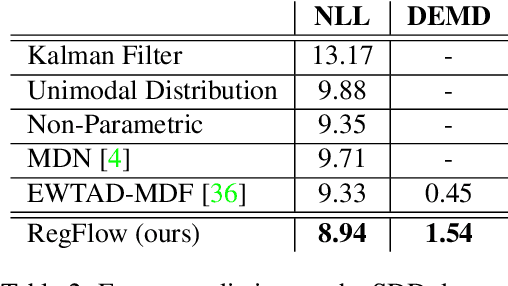
Predicting future states or actions of a given system remains a fundamental, yet unsolved challenge of intelligence, especially in the scope of complex and non-deterministic scenarios, such as modeling behavior of humans. Existing approaches provide results under strong assumptions concerning unimodality of future states, or, at best, assuming specific probability distributions that often poorly fit to real-life conditions. In this work we introduce a robust and flexible probabilistic framework that allows to model future predictions with virtually no constrains regarding the modality or underlying probability distribution. To achieve this goal, we leverage a hypernetwork architecture and train a continuous normalizing flow model. The resulting method dubbed RegFlow achieves state-of-the-art results on several benchmark datasets, outperforming competing approaches by a significant margin.
SuperNCN: Neighbourhood consensus network for robust outdoor scenes matching
Dec 10, 2019


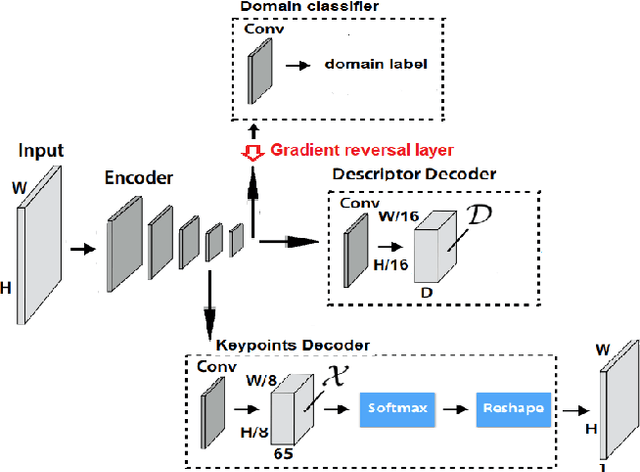
In this paper, we present a framework for computing dense keypoint correspondences between images under strong scene appearance changes. Traditional methods, based on nearest neighbour search in the feature descriptor space, perform poorly when environmental conditions vary, e.g. when images are taken at different times of the day or seasons. Our method improves finding keypoint correspondences in such difficult conditions. First, we use Neighbourhood Consensus Networks to build spatially consistent matching grid between two images at a coarse scale. Then, we apply Superpoint-like corner detector to achieve pixel-level accuracy. Both parts use features learned with domain adaptation to increase robustness against strong scene appearance variations. The framework has been tested on a RobotCar Seasons dataset, proving large improvement on pose estimation task under challenging environmental conditions.