 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What Is Good About This Property: Leveraging Reviews For Segment-Personalized Image Collection Summarization
Oct 30, 2023Image collection summarization techniques aim to present a compact representation of an image gallery through a carefully selected subset of images that captures its semantic content. When it comes to web content, however, the ideal selection can vary based on the user's specific intentions and preferences. This is particularly relevant at Booking.com, where presenting properties and their visual summaries that align with users' expectations is crucial. To address this challenge, we consider user intentions in the summarization of property visuals by analyzing property reviews and extracting the most significant aspects mentioned by users. By incorporating the insights from reviews in our visual summaries, we enhance the summaries by presenting the relevant content to a user. Moreover, we achieve it without the need for costly annotations. Our experiments, including human perceptual studies, demonstrate the superiority of our cross-modal approach, which we coin as CrossSummarizer over the no-personalization and image-based clustering baselines.
EgoNN: Egocentric Neural Network for Point Cloud Based 6DoF Relocalization at the City Scale
Oct 24, 2021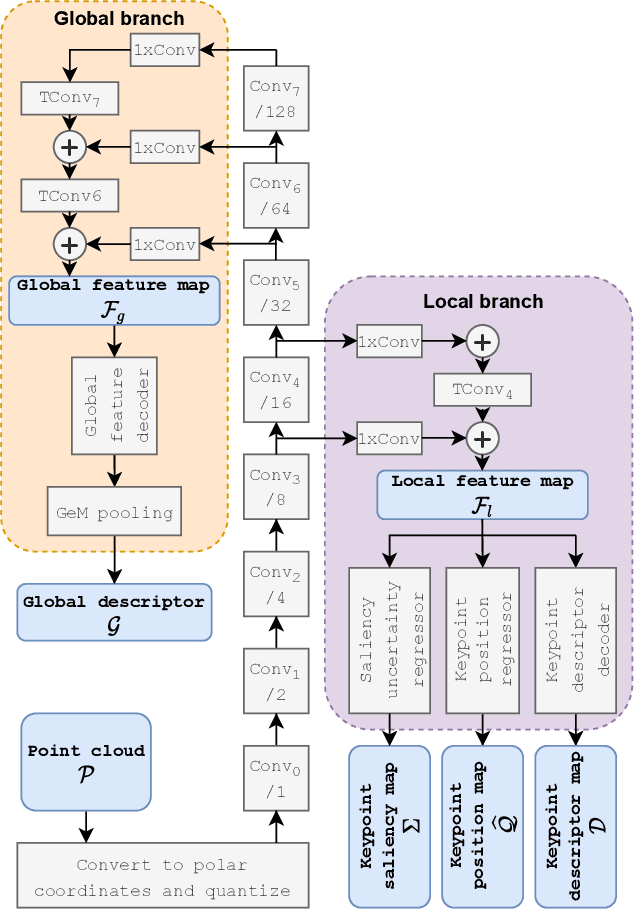
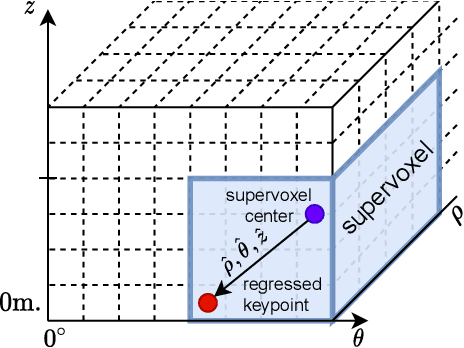
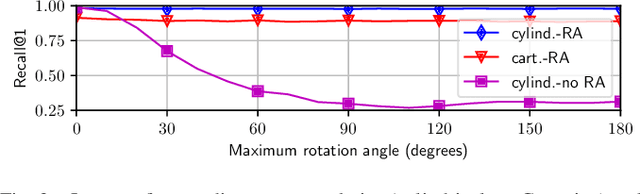

The paper presents a deep neural network-based method for global and local descriptors extraction from a point cloud acquired by a rotating 3D LiDAR. The descriptors can be used for two-stage 6DoF relocalization. First, a course position is retrieved by finding candidates with the closest global descriptor in the database of geo-tagged point clouds. Then, the 6DoF pose between a query point cloud and a database point cloud is estimated by matching local descriptors and using a robust estimator such as RANSAC. Our method has a simple, fully convolutional architecture based on a sparse voxelized representation. It can efficiently extract a global descriptor and a set of keypoints with local descriptors from large point clouds with tens of thousand points. Our code and pretrained models are publicly available on the project website.
Large-Scale Topological Radar Localization Using Learned Descriptors
Oct 06, 2021



In this work, we propose a method for large-scale topological localization based on radar scan images using learned descriptors. We present a simple yet efficient deep network architecture to compute a rotationally invariant discriminative global descriptor from a radar scan image. The performance and generalization ability of the proposed method is experimentally evaluated on two large scale driving datasets: MulRan and Oxford Radar RobotCar. Additionally, we present a comparative evaluation of radar-based and LiDAR-based localization using learned global descriptors. Our code and trained models are publicly available on the project website.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 14, 2021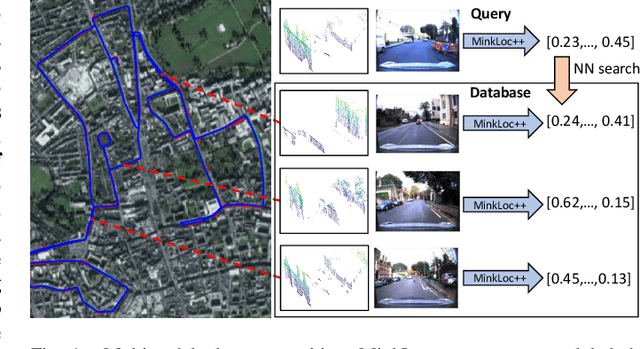
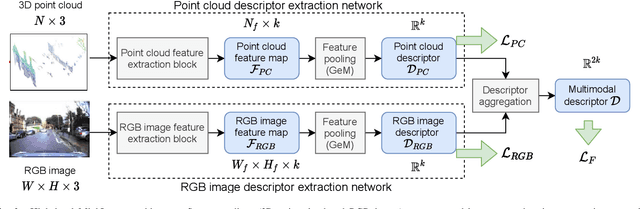
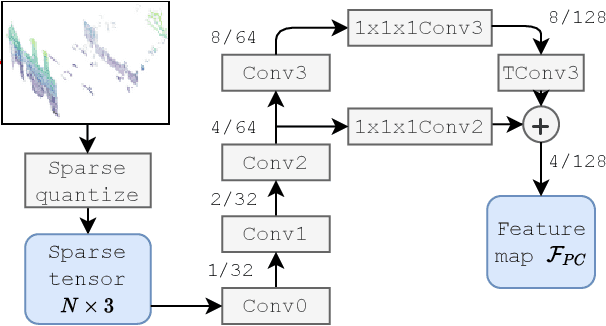

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLocMultimodal.