 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What Is Good About This Property: Leveraging Reviews For Segment-Personalized Image Collection Summarization
Oct 30, 2023Image collection summarization techniques aim to present a compact representation of an image gallery through a carefully selected subset of images that captures its semantic content. When it comes to web content, however, the ideal selection can vary based on the user's specific intentions and preferences. This is particularly relevant at Booking.com, where presenting properties and their visual summaries that align with users' expectations is crucial. To address this challenge, we consider user intentions in the summarization of property visuals by analyzing property reviews and extracting the most significant aspects mentioned by users. By incorporating the insights from reviews in our visual summaries, we enhance the summaries by presenting the relevant content to a user. Moreover, we achieve it without the need for costly annotations. Our experiments, including human perceptual studies, demonstrate the superiority of our cross-modal approach, which we coin as CrossSummarizer over the no-personalization and image-based clustering baselines.
Text2Topic: Multi-Label Text Classification System for Efficient Topic Detection in User Generated Content with Zero-Shot Capabilities
Oct 23, 2023Multi-label text classification is a critical task in the industry. It helps to extract structured information from large amount of textual data. We propose Text to Topic (Text2Topic), which achieves high multi-label classification performance by employing a Bi-Encoder Transformer architecture that utilizes concatenation, subtraction, and multiplication of embeddings on both text and topic. Text2Topic also supports zero-shot predictions, produces domain-specific text embeddings, and enables production-scale batch-inference with high throughput. The final model achieves accurate and comprehensive results compared to state-of-the-art baselines, including large language models (LLMs). In this study, a total of 239 topics are defined, and around 1.6 million text-topic pairs annotations (in which 200K are positive) are collected on approximately 120K texts from 3 main data sources on Booking.com. The data is collected with optimized smart sampling and partial labeling. The final Text2Topic model is deployed on a real-world stream processing platform, and it outperforms other models with 92.9% micro mAP, as well as a 75.8% macro mAP score. We summarize the modeling choices which are extensively tested through ablation studies, and share detailed in-production decision-making steps.
Learning Object Permanence from Video
Mar 26, 2020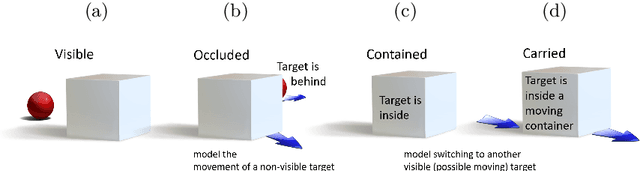
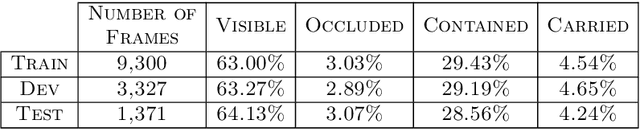
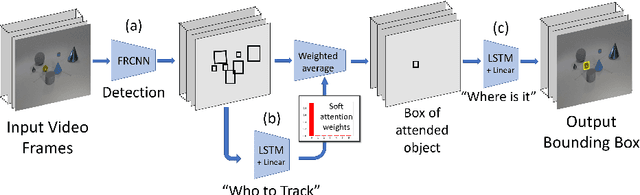
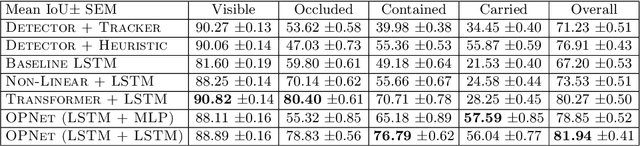
Object Permanence allows people to reason about the location of non-visible objects, by understanding that they continue to exist even when not perceived directly. Object Permanence is critical for building a model of the world, since objects in natural visual scenes dynamically occlude and contain each-other. Intensive studies in developmental psychology suggest that object permanence is a challenging task that is learned through extensive experience. Here we introduce the setup of learning Object Permanence from data. We explain why this learning problem should be dissected into four components, where objects are (1) visible, (2) occluded, (3) contained by another object and (4) carried by a containing object. The fourth subtask, where a target object is carried by a containing object, is particularly challenging because it requires a system to reason about a moving location of an invisible object. We then present a unified deep architecture that learns to predict object location under these four scenarios. We evaluate the architecture and system on a new dataset based on CATER, and find that it outperforms previous localization methods and various baselines.