 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Permanence from Video
Paper and Code
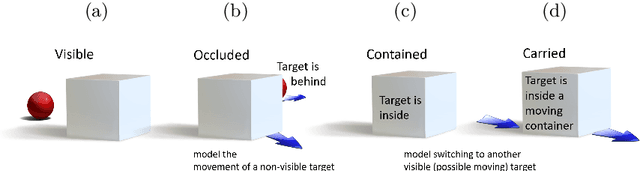
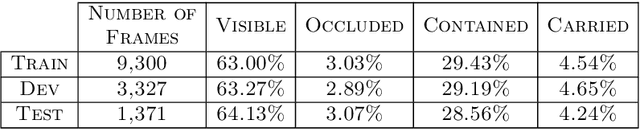
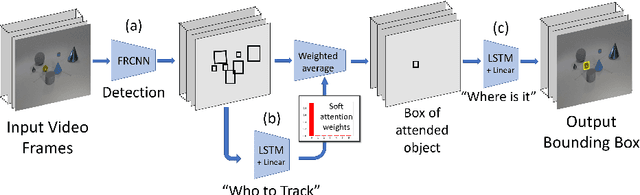
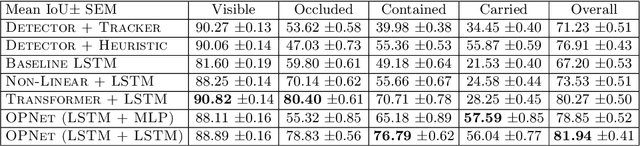
Object Permanence allows people to reason about the location of non-visible objects, by understanding that they continue to exist even when not perceived directly. Object Permanence is critical for building a model of the world, since objects in natural visual scenes dynamically occlude and contain each-other. Intensive studies in developmental psychology suggest that object permanence is a challenging task that is learned through extensive experience. Here we introduce the setup of learning Object Permanence from data. We explain why this learning problem should be dissected into four components, where objects are (1) visible, (2) occluded, (3) contained by another object and (4) carried by a containing object. The fourth subtask, where a target object is carried by a containing object, is particularly challenging because it requires a system to reason about a moving location of an invisible object. We then present a unified deep architecture that learns to predict object location under these four scenarios. We evaluate the architecture and system on a new dataset based on CATER, and find that it outperforms previous localization methods and various baselines.