 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What Is Good About This Property: Leveraging Reviews For Segment-Personalized Image Collection Summarization
Oct 30, 2023Image collection summarization techniques aim to present a compact representation of an image gallery through a carefully selected subset of images that captures its semantic content. When it comes to web content, however, the ideal selection can vary based on the user's specific intentions and preferences. This is particularly relevant at Booking.com, where presenting properties and their visual summaries that align with users' expectations is crucial. To address this challenge, we consider user intentions in the summarization of property visuals by analyzing property reviews and extracting the most significant aspects mentioned by users. By incorporating the insights from reviews in our visual summaries, we enhance the summaries by presenting the relevant content to a user. Moreover, we achieve it without the need for costly annotations. Our experiments, including human perceptual studies, demonstrate the superiority of our cross-modal approach, which we coin as CrossSummarizer over the no-personalization and image-based clustering baselines.
MuMIC -- Multimodal Embedding for Multi-label Image Classification with Tempered Sigmoid
Nov 02, 2022Multi-label image classification is a foundational topic in various domains. Multimodal learning approaches have recently achieved outstanding results in image representation and single-label image classification. For instance, Contrastive Language-Image Pretraining (CLIP) demonstrates impressive image-text representation learning abilities and is robust to natural distribution shifts. This success inspires us to leverage multimodal learning for multi-label classification tasks, and benefit from contrastively learnt pretrained models. We propose the Multimodal Multi-label Image Classification (MuMIC) framework, which utilizes a hardness-aware tempered sigmoid based Binary Cross Entropy loss function, thus enables the optimization on multi-label objectives and transfer learning on CLIP. MuMIC is capable of providing high classification performance, handling real-world noisy data, supporting zero-shot predictions, and producing domain-specific image embeddings. In this study, a total of 120 image classes are defined, and more than 140K positive annotations are collected on approximately 60K Booking.com images. The final MuMIC model is deployed on Booking.com Content Intelligence Platform, and it outperforms other state-of-the-art models with 85.6% GAP@10 and 83.8% GAP on all 120 classes, as well as a 90.1% macro mAP score across 32 majority classes. We summarize the modeling choices which are extensively tested through ablation studies. To the best of our knowledge, we are the first to adapt contrastively learnt multimodal pretraining for real-world multi-label image classification problems, and the innovation can be transferred to other domains.
With One Voice: Composing a Travel Voice Assistant from Re-purposed Models
Aug 04, 2021
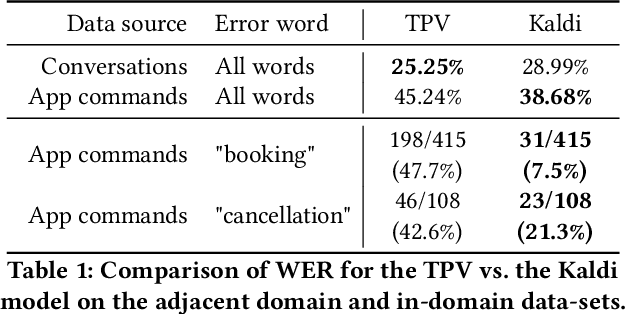
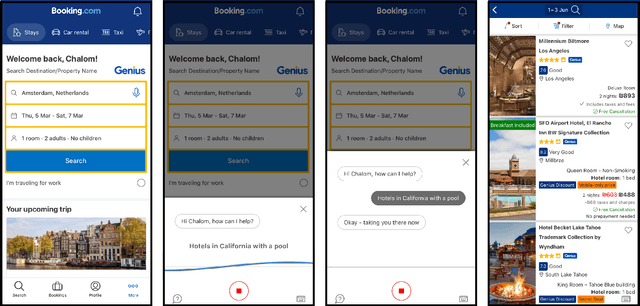

Voice assistants provide users a new way of interacting with digital products, allowing them to retrieve information and complete tasks with an increased sense of control and flexibility. Such products are comprised of several machine learning models, like Speech-to-Text transcription, Named Entity Recognition and Resolution, and Text Classification. Building a voice assistant from scratch takes the prolonged efforts of several teams constructing numerous models and orchestrating between components. Alternatives such as using third-party vendors or re-purposing existing models may be considered to shorten time-to-market and development costs. However, each option has its benefits and drawbacks. We present key insights from building a voice search assistant for Booking.com search and recommendation system. Our paper compares the achieved performance and development efforts in dedicated tailor-made solutions against existing re-purposed models. We share and discuss our data-driven decisions about implementation trade-offs and their estimated outcomes in hindsight, showing that a fully functional machine learning product can be built from existing models.
* 2nd International Workshop on Industrial Recommendation Systems @ KDD 2021