 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Multi-Camera Soccer Player Tracker
Nov 03, 2022



The paper presents a multi-camera tracking method intended for tracking soccer players in long shot video recordings from multiple calibrated cameras installed around the playing field. The large distance to the camera makes it difficult to visually distinguish individual players, which adversely affects the performance of traditional solutions relying on the appearance of tracked objects. Our method focuses on individual player dynamics and interactions between neighborhood players to improve tracking performance. To overcome the difficulty of reliably merging detections from multiple cameras in the presence of calibration errors, we propose the novel tracking approach, where the tracker operates directly on raw detection heat maps from multiple cameras. Our model is trained on a large synthetic dataset generated using Google Research Football Environment and fine-tuned using real-world data to reduce costs involved with ground truth preparation.
Sports Camera Pose Refinement Using an Evolution Strategy
Nov 03, 2022This paper presents a robust end-to-end method for sports cameras extrinsic parameters optimization using a novel evolution strategy. First, we developed a neural network architecture for an edge or area-based segmentation of a sports field. Secondly, we implemented the evolution strategy, which purpose is to refine extrinsic camera parameters given a single, segmented sports field image. Experimental comparison with state-of-the-art camera pose refinement methods on real-world data demonstrates the superiority of the proposed algorithm. We also perform an ablation study and propose a way to generalize the method to additionally refine the intrinsic camera matrix.
Improving Point Cloud Based Place Recognition with Ranking-based Loss and Large Batch Training
Apr 07, 2022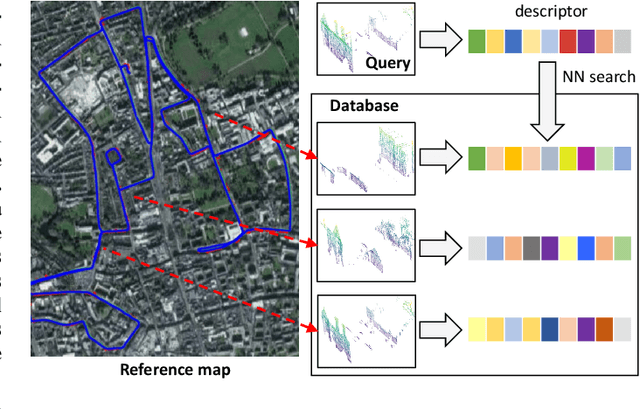

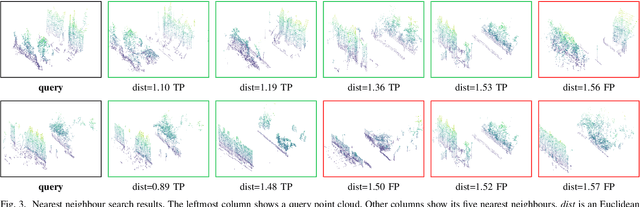

The paper presents a simple and effective learning-based method for computing a discriminative 3D point cloud descriptor for place recognition purposes. Recent state-of-the-art methods have relatively complex architectures such as multi-scale oyramid of point Transformers combined with a pyramid of feature aggregation modules. Our method uses a simple and efficient 3D convolutional feature extraction, based on a sparse voxelized representation, enhanced with channel attention blocks. We employ recent advances in image retrieval and propose a modified version of a loss function based on a differentiable average precision approximation. Such loss function requires training with very large batches for the best results. This is enabled by using multistaged backpropagation. Experimental evaluation on the popular benchmarks proves the effectiveness of our approach, with a consistent improvement over the state of the art
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions, spherical coordinates, and intensity
Dec 27, 2021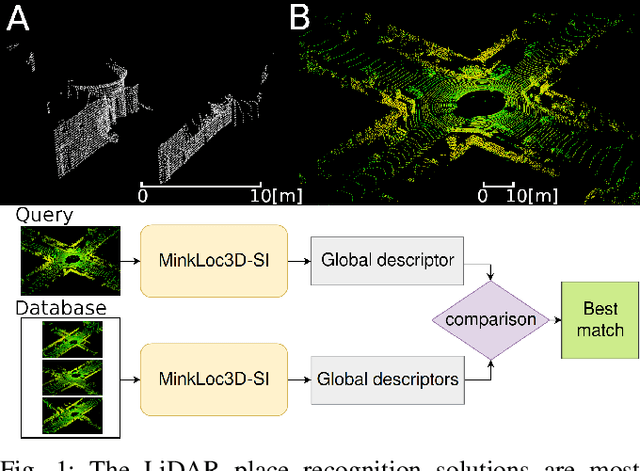


The 3D LiDAR place recognition aims to estimate a coarse localization in a previously seen environment based on a single scan from a rotating 3D LiDAR sensor. The existing solutions to this problem include hand-crafted point cloud descriptors (e.g., ScanContext, M2DP, LiDAR IRIS) and deep learning-based solutions (e.g., PointNetVLAD, PCAN, LPDNet, DAGC, MinkLoc3D), which are often only evaluated on accumulated 2D scans from the Oxford RobotCar dataset. We introduce MinkLoc3D-SI, a sparse convolution-based solution that utilizes spherical coordinates of 3D points and processes the intensity of 3D LiDAR measurements, improving the performance when a single 3D LiDAR scan is used. Our method integrates the improvements typical for hand-crafted descriptors (like ScanContext) with the most efficient 3D sparse convolutions (MinkLoc3D). Our experiments show improved results on single scans from 3D LiDARs (USyd Campus dataset) and great generalization ability (KITTI dataset). Using intensity information on accumulated 2D scans (RobotCar Intensity dataset) improves the performance, even though spherical representation doesn't produce a noticeable improvement. As a result, MinkLoc3D-SI is suited for single scans obtained from a 3D LiDAR, making it applicable in autonomous vehicles.
EgoNN: Egocentric Neural Network for Point Cloud Based 6DoF Relocalization at the City Scale
Oct 24, 2021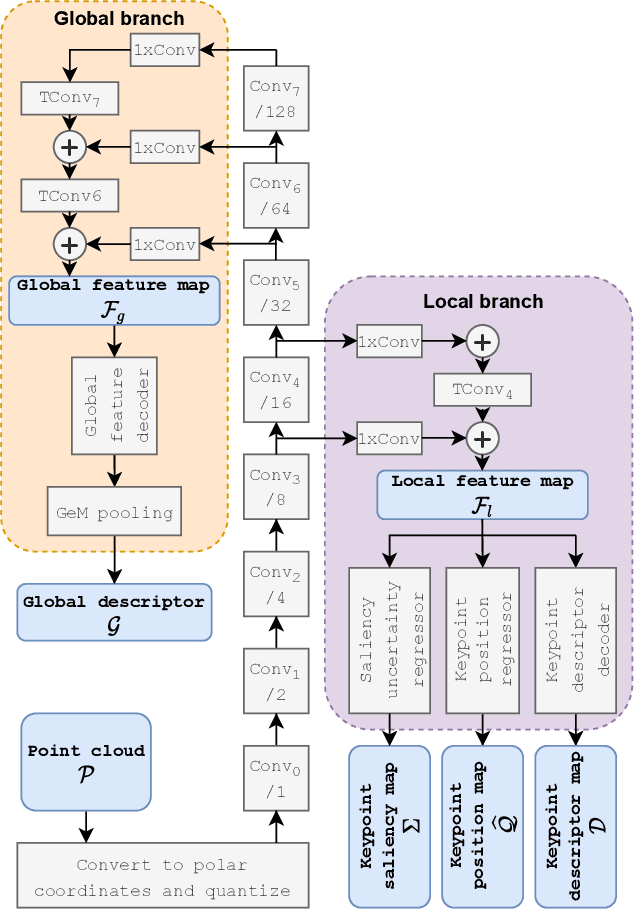
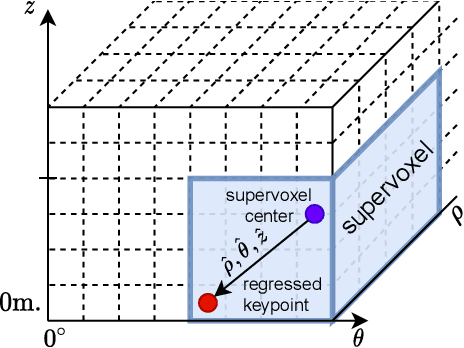
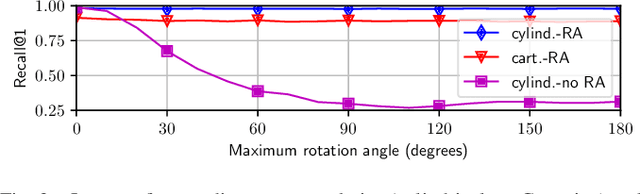

The paper presents a deep neural network-based method for global and local descriptors extraction from a point cloud acquired by a rotating 3D LiDAR. The descriptors can be used for two-stage 6DoF relocalization. First, a course position is retrieved by finding candidates with the closest global descriptor in the database of geo-tagged point clouds. Then, the 6DoF pose between a query point cloud and a database point cloud is estimated by matching local descriptors and using a robust estimator such as RANSAC. Our method has a simple, fully convolutional architecture based on a sparse voxelized representation. It can efficiently extract a global descriptor and a set of keypoints with local descriptors from large point clouds with tens of thousand points. Our code and pretrained models are publicly available on the project website.
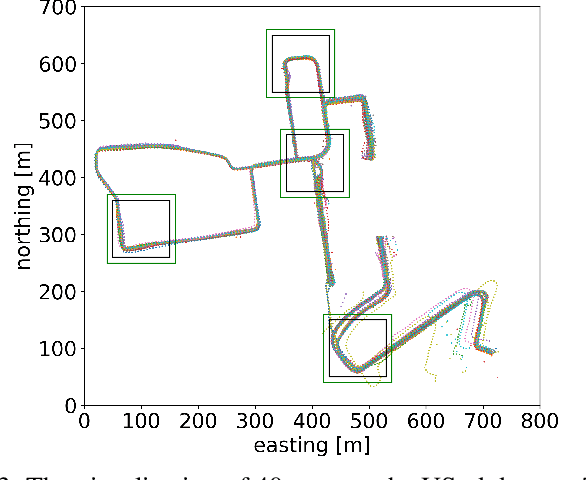
Large-Scale Topological Radar Localization Using Learned Descriptors
Oct 06, 2021



In this work, we propose a method for large-scale topological localization based on radar scan images using learned descriptors. We present a simple yet efficient deep network architecture to compute a rotationally invariant discriminative global descriptor from a radar scan image. The performance and generalization ability of the proposed method is experimentally evaluated on two large scale driving datasets: MulRan and Oxford Radar RobotCar. Additionally, we present a comparative evaluation of radar-based and LiDAR-based localization using learned global descriptors. Our code and trained models are publicly available on the project website.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 14, 2021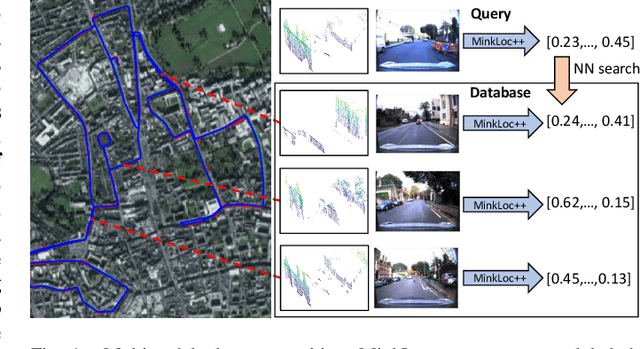
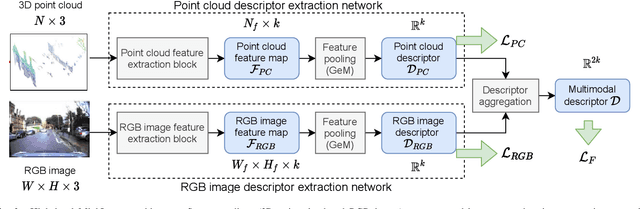
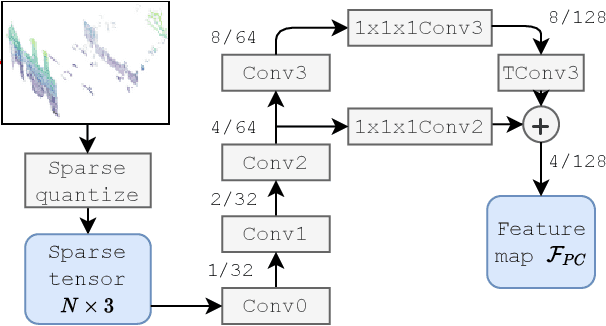

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLocMultimodal.
MinkLoc3D: Point Cloud Based Large-Scale Place Recognition
Nov 09, 2020


The paper presents a learning-based method for computing a discriminative 3D point cloud descriptor for place recognition purposes. Existing methods, such as PointNetVLAD, are based on unordered point cloud representation. They use PointNet as the first processing step to extract local features, which are later aggregated into a global descriptor. The PointNet architecture is not well suited to capture local geometric structures. Thus, state-of-the-art methods enhance vanilla PointNet architecture by adding different mechanism to capture local contextual information, such as graph convolutional networks or using hand-crafted features. We present an alternative approach, dubbed MinkLoc3D, to compute a discriminative 3D point cloud descriptor, based on a sparse voxelized point cloud representation and sparse 3D convolutions. The proposed method has a simple and efficient architecture. Evaluation on standard benchmarks proves that MinkLoc3D outperforms current state-of-the-art. Our code is publicly available on the project website: https://github.com/jac99/MinkLoc3D
SuperNCN: Neighbourhood consensus network for robust outdoor scenes matching
Dec 10, 2019


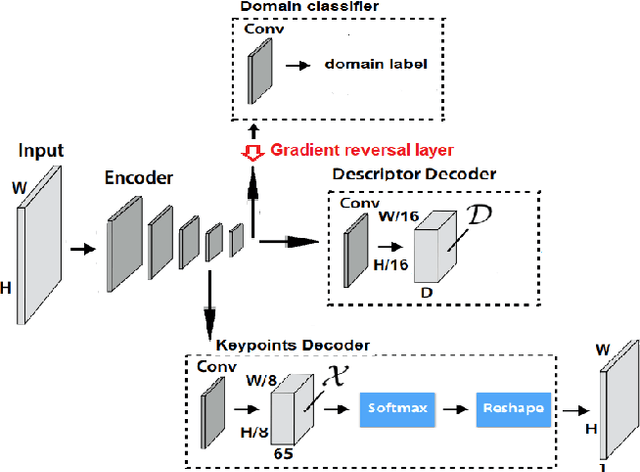
In this paper, we present a framework for computing dense keypoint correspondences between images under strong scene appearance changes. Traditional methods, based on nearest neighbour search in the feature descriptor space, perform poorly when environmental conditions vary, e.g. when images are taken at different times of the day or seasons. Our method improves finding keypoint correspondences in such difficult conditions. First, we use Neighbourhood Consensus Networks to build spatially consistent matching grid between two images at a coarse scale. Then, we apply Superpoint-like corner detector to achieve pixel-level accuracy. Both parts use features learned with domain adaptation to increase robustness against strong scene appearance variations. The framework has been tested on a RobotCar Seasons dataset, proving large improvement on pose estimation task under challenging environmental conditions.
FootAndBall: Integrated player and ball detector
Dec 10, 2019
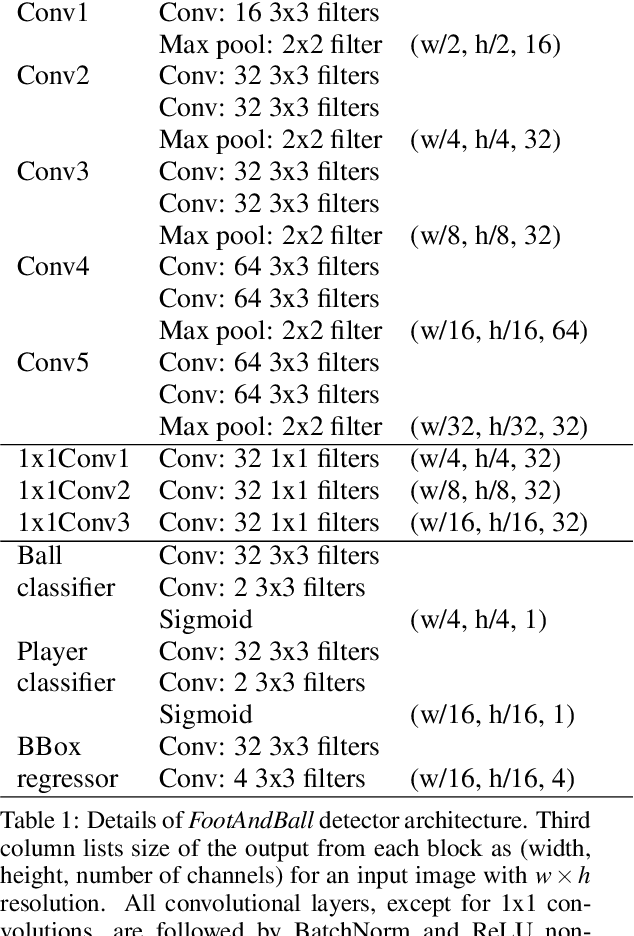

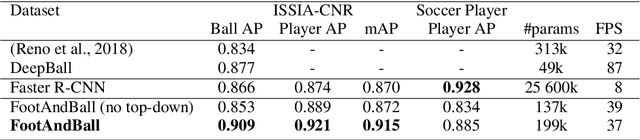
The paper describes a deep neural network-based detector dedicated for ball and players detection in high resolution, long shot, video recordings of soccer matches. The detector, dubbed FootAndBall, has an efficient fully convolutional architecture and can operate on input video stream with an arbitrary resolution. It produces ball confidence map encoding the position of the detected ball, player confidence map and player bounding boxes tensor encoding players' positions and bounding boxes. The network uses Feature Pyramid Network desing pattern, where lower level features with higher spatial resolution are combined with higher level features with bigger receptive field. This improves discriminability of small objects (the ball) as larger visual context around the object of interest is taken into account for the classification. Due to its specialized design, the network has two orders of magnitude less parameters than a generic deep neural network-based object detector, such as SSD or YOLO. This allows real-time processing of high resolution input video stream.