 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinkLoc3D: Point Cloud Based Large-Scale Place Recognition
Paper and Code



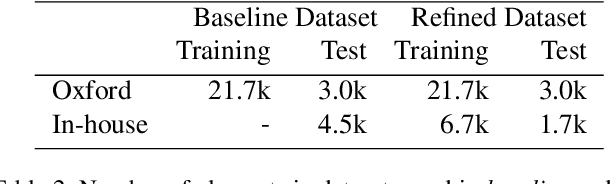
The paper presents a learning-based method for computing a discriminative 3D point cloud descriptor for place recognition purposes. Existing methods, such as PointNetVLAD, are based on unordered point cloud representation. They use PointNet as the first processing step to extract local features, which are later aggregated into a global descriptor. The PointNet architecture is not well suited to capture local geometric structures. Thus, state-of-the-art methods enhance vanilla PointNet architecture by adding different mechanism to capture local contextual information, such as graph convolutional networks or using hand-crafted features. We present an alternative approach, dubbed MinkLoc3D, to compute a discriminative 3D point cloud descriptor, based on a sparse voxelized point cloud representation and sparse 3D convolutions. The proposed method has a simple and efficient architecture. Evaluation on standard benchmarks proves that MinkLoc3D outperforms current state-of-the-art. Our code is publicly available on the project website: https://github.com/jac99/MinkLoc3D