 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-free Continual Learning
Apr 01, 2025

Continual learning (CL) presents a fundamental challenge in training neural networks on sequential tasks without experiencing catastrophic forgetting. Traditionally, the dominant approach in CL has been gradient-based optimization, where updates to the network parameters are performed using stochastic gradient descent (SGD) or its variants. However, a major limitation arises when previous data is no longer accessible, as is often assumed in CL settings. In such cases, there is no gradient information available for past data, leading to uncontrolled parameter changes and consequently severe forgetting of previously learned tasks. By shifting focus from data availability to gradient availability, this work opens up new avenues for addressing forgetting in CL. We explore the hypothesis that gradient-free optimization methods can provide a robust alternative to conventional gradient-based continual learning approaches. We discuss the theoretical underpinnings of such method, analyze their potential advantages and limitations, and present empirical evidence supporting their effectiveness. By reconsidering the fundamental cause of forgetting, this work aims to contribute a fresh perspective to the field of continual learning and inspire novel research directions.
Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
Sep 26, 2024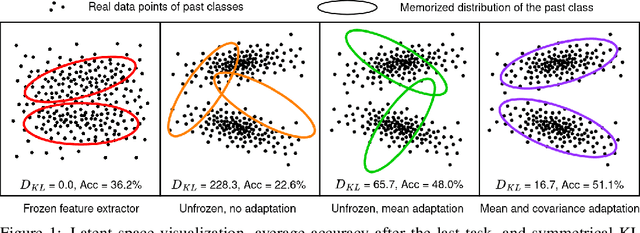
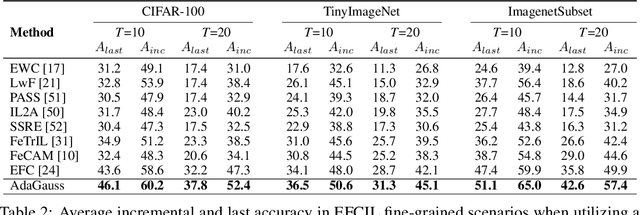
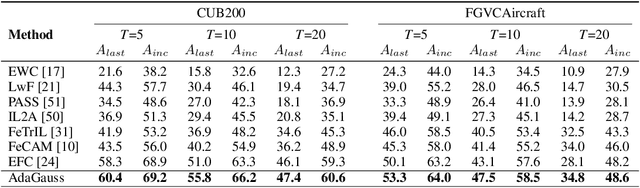

Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss -- a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone. The code is available at: https://github.com/grypesc/AdaGauss.
ESC: Evolutionary Stitched Camera Calibration in the Wild
Apr 19, 2024



This work introduces a novel end-to-end approach for estimating extrinsic parameters of cameras in multi-camera setups on real-life sports fields. We identify the source of significant calibration errors in multi-camera environments and address the limitations of existing calibration methods, particularly the disparity between theoretical models and actual sports field characteristics. We propose the Evolutionary Stitched Camera calibration (ESC) algorithm to bridge this gap. It consists of image segmentation followed by evolutionary optimization of a novel loss function, providing a unified and accurate multi-camera calibration solution with high visual fidelity. The outcome allows the creation of virtual stitched views from multiple video sources, being as important for practical applications as numerical accuracy. We demonstrate the superior performance of our approach compared to state-of-the-art methods across diverse real-life football fields with varying physical characteristics.
Divide and not forget: Ensemble of selectively trained experts in Continual Learning
Jan 19, 2024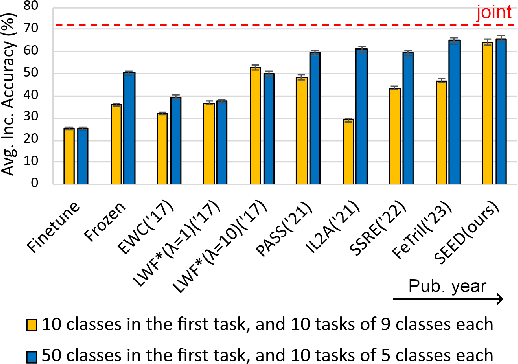
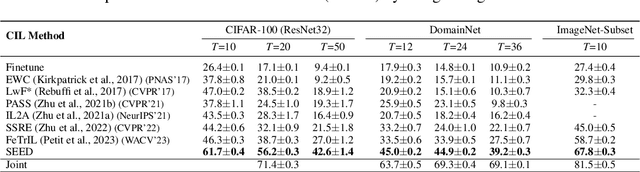
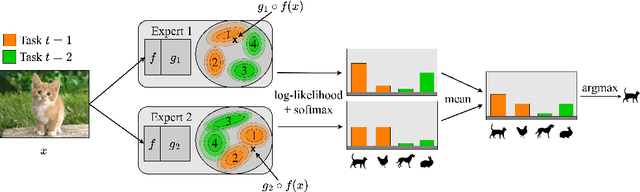
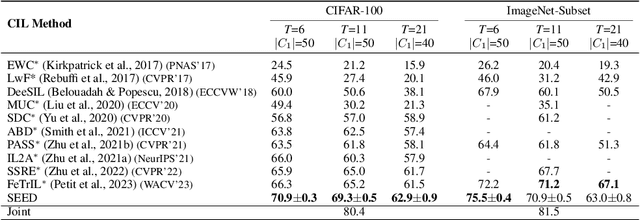
Class-incremental learning is becoming more popular as it helps models widen their applicability while not forgetting what they already know. A trend in this area is to use a mixture-of-expert technique, where different models work together to solve the task. However, the experts are usually trained all at once using whole task data, which makes them all prone to forgetting and increasing computational burden. To address this limitation, we introduce a novel approach named SEED. SEED selects only one, the most optimal expert for a considered task, and uses data from this task to fine-tune only this expert. For this purpose, each expert represents each class with a Gaussian distribution, and the optimal expert is selected based on the similarity of those distributions. Consequently, SEED increases diversity and heterogeneity within the experts while maintaining the high stability of this ensemble method. The extensive experiments demonstrate that SEED achieves state-of-the-art performance in exemplar-free settings across various scenarios, showing the potential of expert diversification through data in continual learning.
Generalized Continual Category Discovery
Aug 23, 2023Most of Continual Learning (CL) methods push the limit of supervised learning settings, where an agent is expected to learn new labeled tasks and not forget previous knowledge. However, these settings are not well aligned with real-life scenarios, where a learning agent has access to a vast amount of unlabeled data encompassing both novel (entirely unlabeled) classes and examples from known classes. Drawing inspiration from Generalized Category Discovery (GCD), we introduce a novel framework that relaxes this assumption. Precisely, in any task, we allow for the existence of novel and known classes, and one must use continual version of unsupervised learning methods to discover them. We call this setting Generalized Continual Category Discovery (GCCD). It unifies CL and GCD, bridging the gap between synthetic benchmarks and real-life scenarios. With a series of experiments, we present that existing methods fail to accumulate knowledge from subsequent tasks in which unlabeled samples of novel classes are present. In light of these limitations, we propose a method that incorporates both supervised and unsupervised signals and mitigates the forgetting through the use of centroid adaptation. Our method surpasses strong CL methods adopted for GCD techniques and presents a superior representation learning performance.
Active Visual Exploration Based on Attention-Map Entropy
Mar 11, 2023



Active visual exploration addresses the issue of limited sensor capabilities in real-world scenarios, where successive observations are actively chosen based on the environment. To tackle this problem, we introduce a new technique called Attention-Map Entropy (AME). It leverages the internal uncertainty of the transformer-based model to determine the most informative observations. In contrast to existing solutions, it does not require additional loss components, which simplifies the training. Through experiments, which also mimic retina-like sensors, we show that such simplified training significantly improves the performance of reconstruction and classification on publicly available datasets.
Sports Camera Pose Refinement Using an Evolution Strategy
Nov 03, 2022This paper presents a robust end-to-end method for sports cameras extrinsic parameters optimization using a novel evolution strategy. First, we developed a neural network architecture for an edge or area-based segmentation of a sports field. Secondly, we implemented the evolution strategy, which purpose is to refine extrinsic camera parameters given a single, segmented sports field image. Experimental comparison with state-of-the-art camera pose refinement methods on real-world data demonstrates the superiority of the proposed algorithm. We also perform an ablation study and propose a way to generalize the method to additionally refine the intrinsic camera matrix.
Reinforcement Learning for on-line Sequence Transformation
May 28, 2021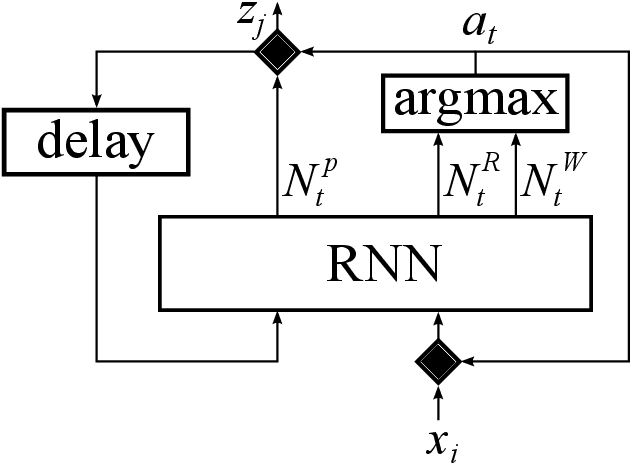
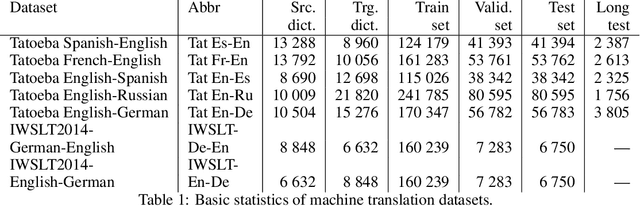
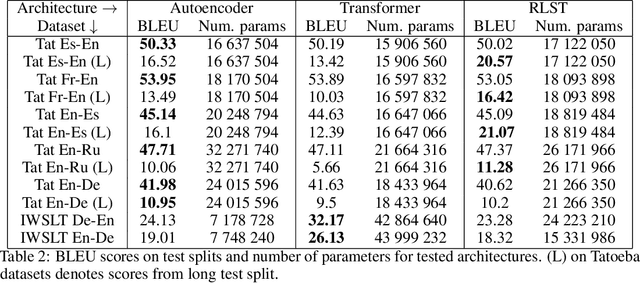
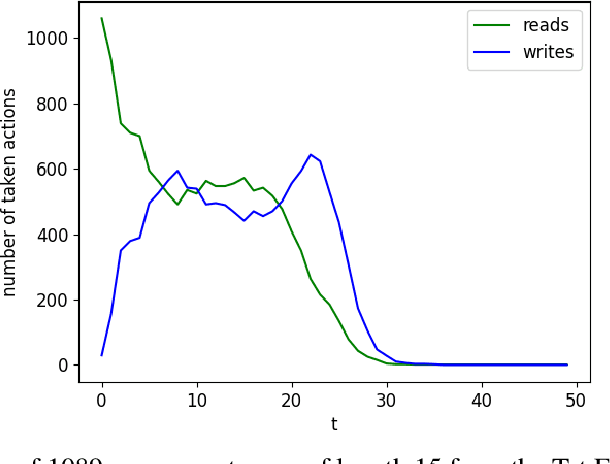
A number of problems in the processing of sound and natural language, as well as in other areas, can be reduced to simultaneously reading an input sequence and writing an output sequence of generally different length. There are well developed methods that produce the output sequence based on the entirely known input. However, efficient methods that enable such transformations on-line do not exist. In this paper we introduce an architecture that learns with reinforcement to make decisions about whether to read a token or write another token. This architecture is able to transform potentially infinite sequences on-line. In an experimental study we compare it with state-of-the-art methods for neural machine translation. While it produces slightly worse translations than Transformer, it outperforms the autoencoder with attention, even though our architecture translates texts on-line thereby solving a more difficult problem than both reference methods.