 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for on-line Sequence Transformation
Paper and Code
May 28, 2021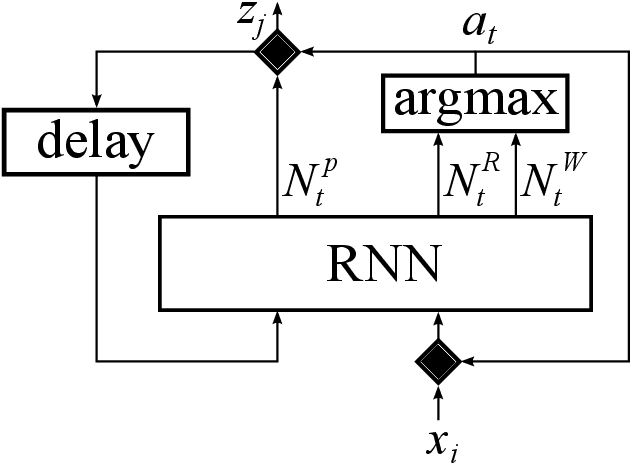
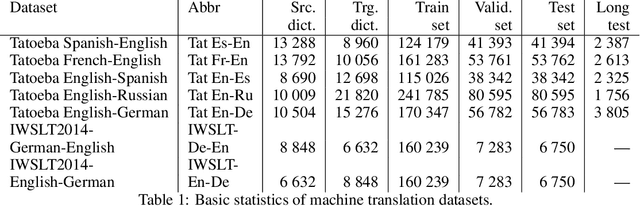
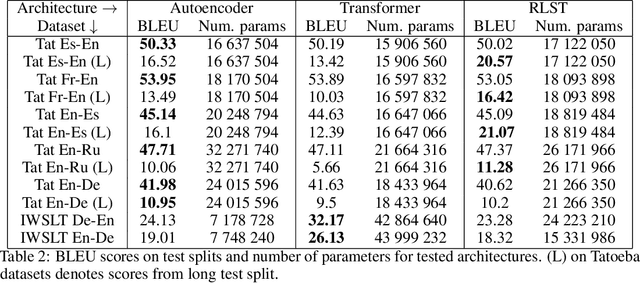
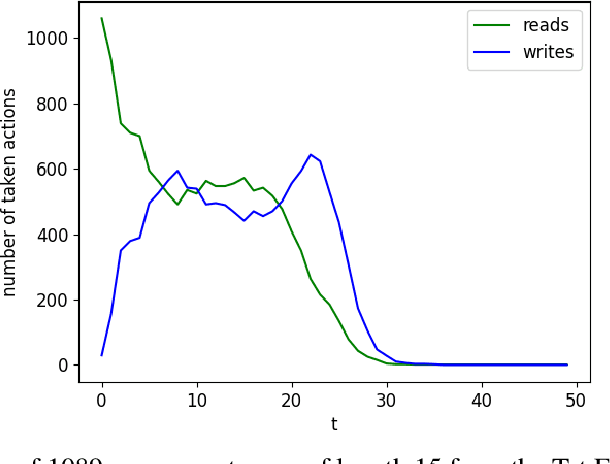
A number of problems in the processing of sound and natural language, as well as in other areas, can be reduced to simultaneously reading an input sequence and writing an output sequence of generally different length. There are well developed methods that produce the output sequence based on the entirely known input. However, efficient methods that enable such transformations on-line do not exist. In this paper we introduce an architecture that learns with reinforcement to make decisions about whether to read a token or write another token. This architecture is able to transform potentially infinite sequences on-line. In an experimental study we compare it with state-of-the-art methods for neural machine translation. While it produces slightly worse translations than Transformer, it outperforms the autoencoder with attention, even though our architecture translates texts on-line thereby solving a more difficult problem than both reference methods.