 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and not forget: Ensemble of selectively trained experts in Continual Learning
Jan 19, 2024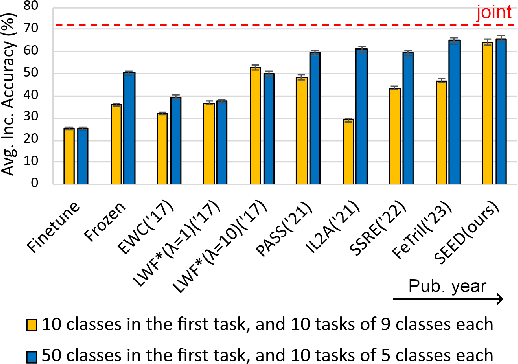
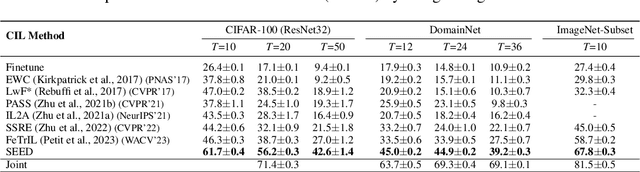
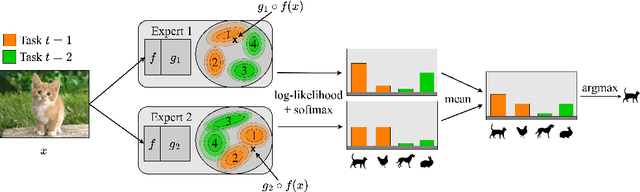
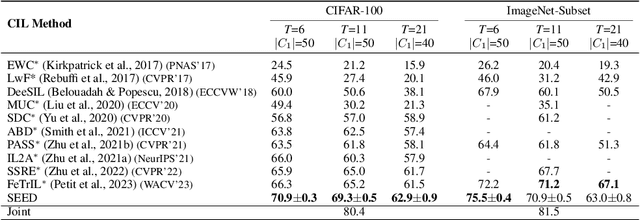
Class-incremental learning is becoming more popular as it helps models widen their applicability while not forgetting what they already know. A trend in this area is to use a mixture-of-expert technique, where different models work together to solve the task. However, the experts are usually trained all at once using whole task data, which makes them all prone to forgetting and increasing computational burden. To address this limitation, we introduce a novel approach named SEED. SEED selects only one, the most optimal expert for a considered task, and uses data from this task to fine-tune only this expert. For this purpose, each expert represents each class with a Gaussian distribution, and the optimal expert is selected based on the similarity of those distributions. Consequently, SEED increases diversity and heterogeneity within the experts while maintaining the high stability of this ensemble method. The extensive experiments demonstrate that SEED achieves state-of-the-art performance in exemplar-free settings across various scenarios, showing the potential of expert diversification through data in continual learning.
Looking through the past: better knowledge retention for generative replay in continual learning
Sep 18, 2023In this work, we improve the generative replay in a continual learning setting to perform well on challenging scenarios. Current generative rehearsal methods are usually benchmarked on small and simple datasets as they are not powerful enough to generate more complex data with a greater number of classes. We notice that in VAE-based generative replay, this could be attributed to the fact that the generated features are far from the original ones when mapped to the latent space. Therefore, we propose three modifications that allow the model to learn and generate complex data. More specifically, we incorporate the distillation in latent space between the current and previous models to reduce feature drift. Additionally, a latent matching for the reconstruction and original data is proposed to improve generated features alignment. Further, based on the observation that the reconstructions are better for preserving knowledge, we add the cycling of generations through the previously trained model to make them closer to the original data. Our method outperforms other generative replay methods in various scenarios. Code available at https://github.com/valeriya-khan/looking-through-the-past.