 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaRRTa: A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models
Jan 16, 2026Visual Foundation Models (VFMs), such as DINO and CLIP, excel in semantic understanding of images but exhibit limited spatial reasoning capabilities, which limits their applicability to embodied systems. As a result, recent work incorporates some 3D tasks (such as depth estimation) into VFM training. However, VFM performance remains inconsistent across other spatial tasks, raising the question of whether these models truly have spatial awareness or overfit to specific 3D objectives. To address this question, we introduce the Spatial Relation Recognition Task (SpaRRTa) benchmark, which evaluates the ability of VFMs to identify relative positions of objects in the image. Unlike traditional 3D objectives that focus on precise metric prediction (e.g., surface normal estimation), SpaRRTa probes a fundamental capability underpinning more advanced forms of human-like spatial understanding. SpaRRTa generates an arbitrary number of photorealistic images with diverse scenes and fully controllable object arrangements, along with freely accessible spatial annotations. Evaluating a range of state-of-the-art VFMs, we reveal significant disparities between their spatial reasoning abilities. Through our analysis, we provide insights into the mechanisms that support or hinder spatial awareness in modern VFMs. We hope that SpaRRTa will serve as a useful tool for guiding the development of future spatially aware visual models.
AI-Driven Rapid Identification of Bacterial and Fungal Pathogens in Blood Smears of Septic Patients
Mar 17, 2025Sepsis is a life-threatening condition which requires rapid diagnosis and treatment. Traditional microbiological methods are time-consuming and expensive. In response to these challenges, deep learning algorithms were developed to identify 14 bacteria species and 3 yeast-like fungi from microscopic images of Gram-stained smears of positive blood samples from sepsis patients. A total of 16,637 Gram-stained microscopic images were used in the study. The analysis used the Cellpose 3 model for segmentation and Attention-based Deep Multiple Instance Learning for classification. Our model achieved an accuracy of 77.15% for bacteria and 71.39% for fungi, with ROC AUC of 0.97 and 0.88, respectively. The highest values, reaching up to 96.2%, were obtained for Cutibacterium acnes, Enterococcus faecium, Stenotrophomonas maltophilia and Nakaseomyces glabratus. Classification difficulties were observed in closely related species, such as Staphylococcus hominis and Staphylococcus haemolyticus, due to morphological similarity, and within Candida albicans due to high morphotic diversity. The study confirms the potential of our model for microbial classification, but it also indicates the need for further optimisation and expansion of the training data set. In the future, this technology could support microbial diagnosis, reducing diagnostic time and improving the effectiveness of sepsis treatment due to its simplicity and accessibility. Part of the results presented in this publication was covered by a patent application at the European Patent Office EP24461637.1 "A computer implemented method for identifying a microorganism in a blood and a data processing system therefor".
AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale
Apr 04, 2024Active Visual Exploration (AVE) is a task that involves dynamically selecting observations (glimpses), which is critical to facilitate comprehension and navigation within an environment. While modern AVE methods have demonstrated impressive performance, they are constrained to fixed-scale glimpses from rigid grids. In contrast, existing mobile platforms equipped with optical zoom capabilities can capture glimpses of arbitrary positions and scales. To address this gap between software and hardware capabilities, we introduce AdaGlimpse. It uses Soft Actor-Critic, a reinforcement learning algorithm tailored for exploration tasks, to select glimpses of arbitrary position and scale. This approach enables our model to rapidly establish a general awareness of the environment before zooming in for detailed analysis. Experimental results demonstrate that AdaGlimpse surpasses previous methods across various visual tasks while maintaining greater applicability in realistic AVE scenarios.
ProPML: Probability Partial Multi-label Learning
Mar 12, 2024Partial Multi-label Learning (PML) is a type of weakly supervised learning where each training instance corresponds to a set of candidate labels, among which only some are true. In this paper, we introduce \our{}, a novel probabilistic approach to this problem that extends the binary cross entropy to the PML setup. In contrast to existing methods, it does not require suboptimal disambiguation and, as such, can be applied to any deep architecture. Furthermore, experiments conducted on artificial and real-world datasets indicate that \our{} outperforms existing approaches, especially for high noise in a candidate set.
Beyond Grids: Exploring Elastic Input Sampling for Vision Transformers
Sep 23, 2023Vision transformers have excelled in various computer vision tasks but mostly rely on rigid input sampling using a fixed-size grid of patches. This limits their applicability in real-world problems, such as in the field of robotics and UAVs, where one can utilize higher input elasticity to boost model performance and efficiency. Our paper addresses this limitation by formalizing the concept of input elasticity for vision transformers and introducing an evaluation protocol, including dedicated metrics for measuring input elasticity. Moreover, we propose modifications to the transformer architecture and training regime, which increase its elasticity. Through extensive experimentation, we spotlight opportunities and challenges associated with input sampling strategies.
Active Visual Exploration Based on Attention-Map Entropy
Mar 11, 2023



Active visual exploration addresses the issue of limited sensor capabilities in real-world scenarios, where successive observations are actively chosen based on the environment. To tackle this problem, we introduce a new technique called Attention-Map Entropy (AME). It leverages the internal uncertainty of the transformer-based model to determine the most informative observations. In contrast to existing solutions, it does not require additional loss components, which simplifies the training. Through experiments, which also mimic retina-like sensors, we show that such simplified training significantly improves the performance of reconstruction and classification on publicly available datasets.
ProtoMIL: Multiple Instance Learning with Prototypical Parts for Fine-Grained Interpretability
Aug 24, 2021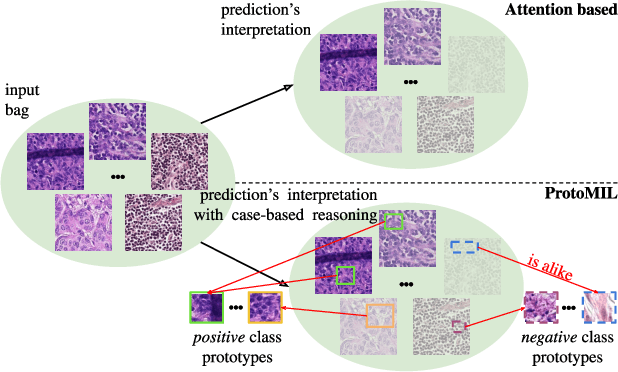
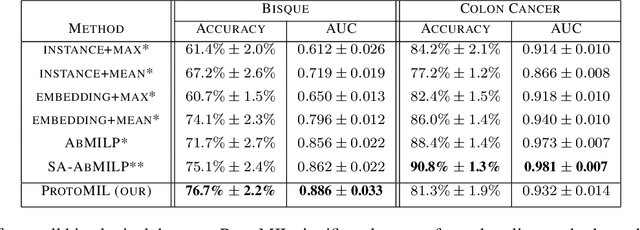
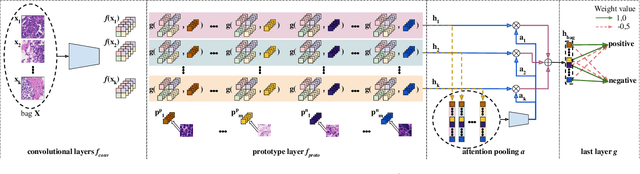
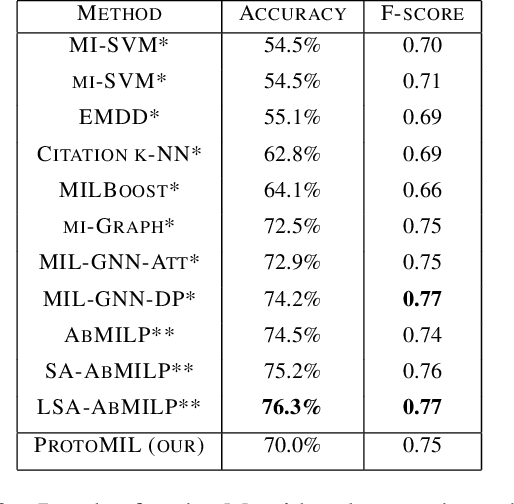
Multiple Instance Learning (MIL) gains popularity in many real-life machine learning applications due to its weakly supervised nature. However, the corresponding effort on explaining MIL lags behind, and it is usually limited to presenting instances of a bag that are crucial for a particular prediction. In this paper, we fill this gap by introducing ProtoMIL, a novel self-explainable MIL method inspired by the case-based reasoning process that operates on visual prototypes. Thanks to incorporating prototypical features into objects description, ProtoMIL unprecedentedly joins the model accuracy and fine-grained interpretability, which we present with the experiments on five recognized MIL datasets.