 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
Shapley Pruning for Neural Network Compression
Jul 19, 2024Neural network pruning is a rich field with a variety of approaches. In this work, we propose to connect the existing pruning concepts such as leave-one-out pruning and oracle pruning and develop them into a more general Shapley value-based framework that targets the compression of convolutional neural networks. To allow for practical applications in utilizing the Shapley value, this work presents the Shapley value approximations, and performs the comparative analysis in terms of cost-benefit utility for the neural network compression. The proposed ranks are evaluated against a new benchmark, Oracle rank, constructed based on oracle sets. The broad experiments show that the proposed normative ranking and its approximations show practical results, obtaining state-of-the-art network compression.
Joint or Disjoint: Mixing Training Regimes for Early-Exit Models
Jul 19, 2024Early exits are an important efficiency mechanism integrated into deep neural networks that allows for the termination of the network's forward pass before processing through all its layers. By allowing early halting of the inference process for less complex inputs that reached high confidence, early exits significantly reduce the amount of computation required. Early exit methods add trainable internal classifiers which leads to more intricacy in the training process. However, there is no consistent verification of the approaches of training of early exit methods, and no unified scheme of training such models. Most early exit methods employ a training strategy that either simultaneously trains the backbone network and the exit heads or trains the exit heads separately. We propose a training approach where the backbone is initially trained on its own, followed by a phase where both the backbone and the exit heads are trained together. Thus, we advocate for organizing early-exit training strategies into three distinct categories, and then validate them for their performance and efficiency. In this benchmark, we perform both theoretical and empirical analysis of early-exit training regimes. We study the methods in terms of information flow, loss landscape and numerical rank of activations and gauge the suitability of regimes for various architectures and datasets.
AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale
Apr 04, 2024Active Visual Exploration (AVE) is a task that involves dynamically selecting observations (glimpses), which is critical to facilitate comprehension and navigation within an environment. While modern AVE methods have demonstrated impressive performance, they are constrained to fixed-scale glimpses from rigid grids. In contrast, existing mobile platforms equipped with optical zoom capabilities can capture glimpses of arbitrary positions and scales. To address this gap between software and hardware capabilities, we introduce AdaGlimpse. It uses Soft Actor-Critic, a reinforcement learning algorithm tailored for exploration tasks, to select glimpses of arbitrary position and scale. This approach enables our model to rapidly establish a general awareness of the environment before zooming in for detailed analysis. Experimental results demonstrate that AdaGlimpse surpasses previous methods across various visual tasks while maintaining greater applicability in realistic AVE scenarios.
Scaling Laws for Fine-Grained Mixture of Experts
Feb 12, 2024



Mixture of Experts (MoE) models have emerged as a primary solution for reducing the computational cost of Large Language Models. In this work, we analyze their scaling properties, incorporating an expanded range of variables. Specifically, we introduce a new hyperparameter, granularity, whose adjustment enables precise control over the size of the experts. Building on this, we establish scaling laws for fine-grained MoE, taking into account the number of training tokens, model size, and granularity. Leveraging these laws, we derive the optimal training configuration for a given computational budget. Our findings not only show that MoE models consistently outperform dense Transformers but also highlight that the efficiency gap between dense and MoE models widens as we scale up the model size and training budget. Furthermore, we demonstrate that the common practice of setting the size of experts in MoE to mirror the feed-forward layer is not optimal at almost any computational budget.
Pre-Pruning and Gradient-Dropping Improve Differentially Private Image Classification
Jun 19, 2023Scalability is a significant challenge when it comes to applying differential privacy to training deep neural networks. The commonly used DP-SGD algorithm struggles to maintain a high level of privacy protection while achieving high accuracy on even moderately sized models. To tackle this challenge, we take advantage of the fact that neural networks are overparameterized, which allows us to improve neural network training with differential privacy. Specifically, we introduce a new training paradigm that uses \textit{pre-pruning} and \textit{gradient-dropping} to reduce the parameter space and improve scalability. The process starts with pre-pruning the parameters of the original network to obtain a smaller model that is then trained with DP-SGD. During training, less important gradients are dropped, and only selected gradients are updated. Our training paradigm introduces a tension between the rates of pre-pruning and gradient-dropping, privacy loss, and classification accuracy. Too much pre-pruning and gradient-dropping reduces the model's capacity and worsens accuracy, while training a smaller model requires less privacy budget for achieving good accuracy. We evaluate the interplay between these factors and demonstrate the effectiveness of our training paradigm for both training from scratch and fine-tuning pre-trained networks on several benchmark image classification datasets. The tools can also be readily incorporated into existing training paradigms.
Lidar Line Selection with Spatially-Aware Shapley Value for Cost-Efficient Depth Completion
Mar 21, 2023Lidar is a vital sensor for estimating the depth of a scene. Typical spinning lidars emit pulses arranged in several horizontal lines and the monetary cost of the sensor increases with the number of these lines. In this work, we present the new problem of optimizing the positioning of lidar lines to find the most effective configuration for the depth completion task. We propose a solution to reduce the number of lines while retaining the up-to-the-mark quality of depth completion. Our method consists of two components, (1) line selection based on the marginal contribution of a line computed via the Shapley value and (2) incorporating line position spread to take into account its need to arrive at image-wide depth completion. Spatially-aware Shapley values (SaS) succeed in selecting line subsets that yield a depth accuracy comparable to the full lidar input while using just half of the lines.
Differential Privacy Meets Neural Network Pruning
Mar 08, 2023A major challenge in applying differential privacy to training deep neural network models is scalability.The widely-used training algorithm, differentially private stochastic gradient descent (DP-SGD), struggles with training moderately-sized neural network models for a value of epsilon corresponding to a high level of privacy protection. In this paper, we explore the idea of dimensionality reduction inspired by neural network pruning to improve the scalability of DP-SGD. We study the interplay between neural network pruning and differential privacy, through the two modes of parameter updates. We call the first mode, parameter freezing, where we pre-prune the network and only update the remaining parameters using DP-SGD. We call the second mode, parameter selection, where we select which parameters to update at each step of training and update only those selected using DP-SGD. In these modes, we use public data for freezing or selecting parameters to avoid privacy loss incurring in these steps. Naturally, the closeness between the private and public data plays an important role in the success of this paradigm. Our experimental results demonstrate how decreasing the parameter space improves differentially private training. Moreover, by studying two popular forms of pruning which do not rely on gradients and do not incur an additional privacy loss, we show that random selection performs on par with magnitude-based selection when it comes to DP-SGD training.
Differentially Private Neural Tangent Kernels for Privacy-Preserving Data Generation
Mar 03, 2023Maximum mean discrepancy (MMD) is a particularly useful distance metric for differentially private data generation: when used with finite-dimensional features it allows us to summarize and privatize the data distribution once, which we can repeatedly use during generator training without further privacy loss. An important question in this framework is, then, what features are useful to distinguish between real and synthetic data distributions, and whether those enable us to generate quality synthetic data. This work considers the using the features of $\textit{neural tangent kernels (NTKs)}$, more precisely $\textit{empirical}$ NTKs (e-NTKs). We find that, perhaps surprisingly, the expressiveness of the untrained e-NTK features is comparable to that of the features taken from pre-trained perceptual features using public data. As a result, our method improves the privacy-accuracy trade-off compared to other state-of-the-art methods, without relying on any public data, as demonstrated on several tabular and image benchmark datasets.
Revisiting Random Channel Pruning for Neural Network Compression
May 11, 2022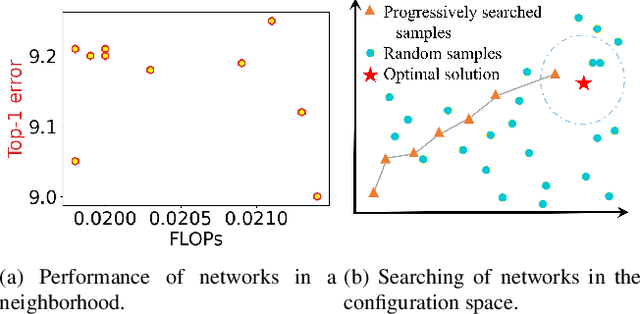
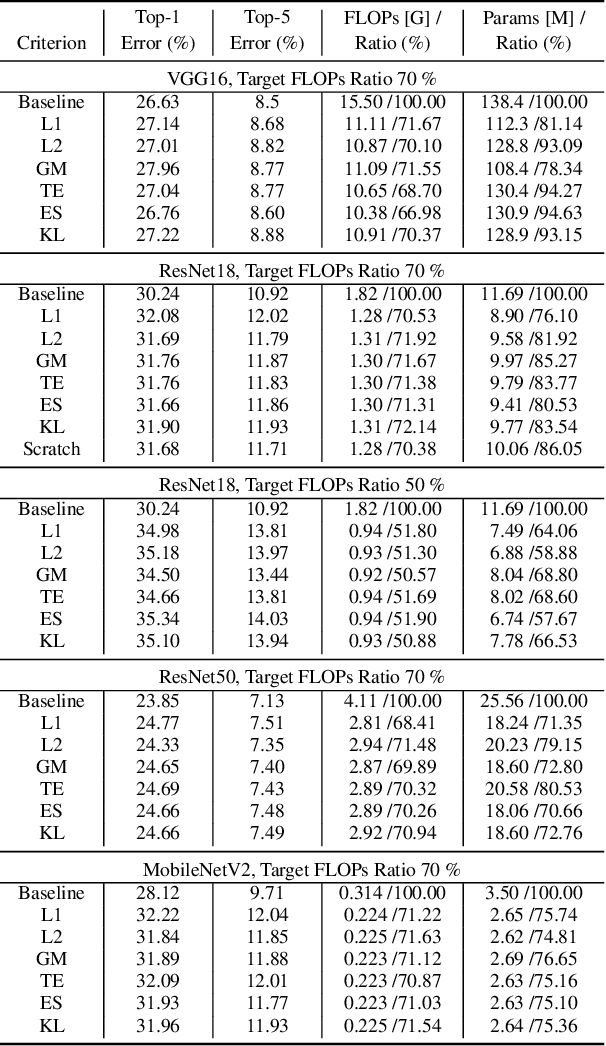
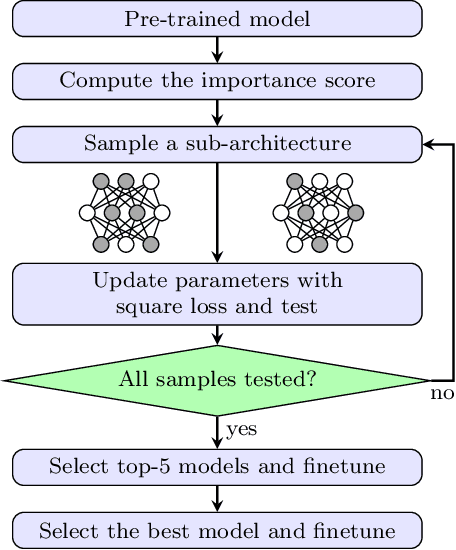
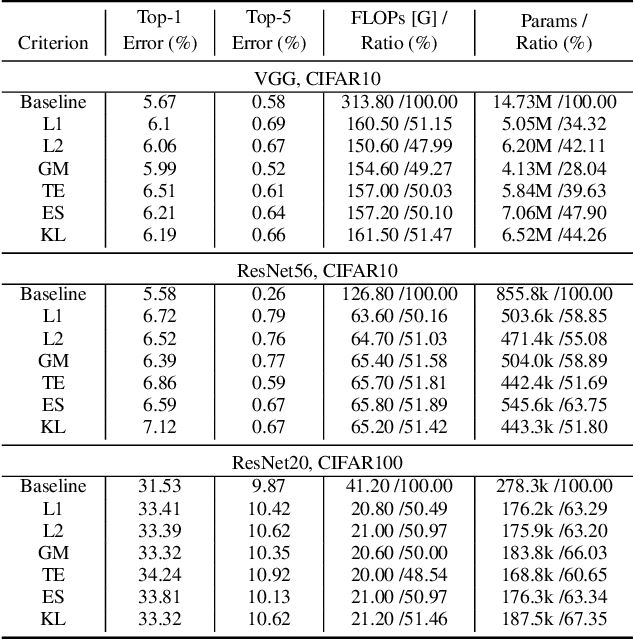
Channel (or 3D filter) pruning serves as an effective way to accelerate the inference of neural networks. There has been a flurry of algorithms that try to solve this practical problem, each being claimed effective in some ways. Yet, a benchmark to compare those algorithms directly is lacking, mainly due to the complexity of the algorithms and some custom settings such as the particular network configuration or training procedure. A fair benchmark is important for the further development of channel pruning. Meanwhile, recent investigations reveal that the channel configurations discovered by pruning algorithms are at least as important as the pre-trained weights. This gives channel pruning a new role, namely searching the optimal channel configuration. In this paper, we try to determine the channel configuration of the pruned models by random search. The proposed approach provides a new way to compare different methods, namely how well they behave compared with random pruning. We show that this simple strategy works quite well compared with other channel pruning methods. We also show that under this setting, there are surprisingly no clear winners among different channel importance evaluation methods, which then may tilt the research efforts into advanced channel configuration searching methods.