 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVARSHAP: Addressing Global Dependency Problems in Explainable AI with Variance-Based Local Feature Attribution
Jun 08, 2025



Existing feature attribution methods like SHAP often suffer from global dependence, failing to capture true local model behavior. This paper introduces VARSHAP, a novel model-agnostic local feature attribution method which uses the reduction of prediction variance as the key importance metric of features. Building upon Shapley value framework, VARSHAP satisfies the key Shapley axioms, but, unlike SHAP, is resilient to global data distribution shifts. Experiments on synthetic and real-world datasets demonstrate that VARSHAP outperforms popular methods such as KernelSHAP or LIME, both quantitatively and qualitatively.
Since Faithfulness Fails: The Performance Limits of Neural Causal Discovery
Feb 22, 2025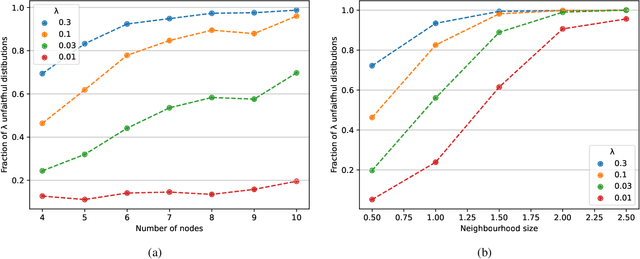



Neural causal discovery methods have recently improved in terms of scalability and computational efficiency. However, our systematic evaluation highlights significant room for improvement in their accuracy when uncovering causal structures. We identify a fundamental limitation: neural networks cannot reliably distinguish between existing and non-existing causal relationships in the finite sample regime. Our experiments reveal that neural networks, as used in contemporary causal discovery approaches, lack the precision needed to recover ground-truth graphs, even for small graphs and relatively large sample sizes. Furthermore, we identify the faithfulness property as a critical bottleneck: (i) it is likely to be violated across any reasonable dataset size range, and (ii) its violation directly undermines the performance of neural discovery methods. These findings lead us to conclude that progress within the current paradigm is fundamentally constrained, necessitating a paradigm shift in this domain.
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
PUB: Plot Understanding Benchmark and Dataset for Evaluating Large Language Models on Synthetic Visual Data Interpretation
Sep 04, 2024The ability of large language models (LLMs) to interpret visual representations of data is crucial for advancing their application in data analysis and decision-making processes. This paper presents a novel synthetic dataset designed to evaluate the proficiency of LLMs in interpreting various forms of data visualizations, including plots like time series, histograms, violins, boxplots, and clusters. Our dataset is generated using controlled parameters to ensure comprehensive coverage of potential real-world scenarios. We employ multimodal text prompts with questions related to visual data in images to benchmark several state-of-the-art models like ChatGPT or Gemini, assessing their understanding and interpretative accuracy. To ensure data integrity, our benchmark dataset is generated automatically, making it entirely new and free from prior exposure to the models being tested. This strategy allows us to evaluate the models' ability to truly interpret and understand the data, eliminating possibility of pre-learned responses, and allowing for an unbiased evaluation of the models' capabilities. We also introduce quantitative metrics to assess the performance of the models, providing a robust and comprehensive evaluation tool. Benchmarking several state-of-the-art LLMs with this dataset reveals varying degrees of success, highlighting specific strengths and weaknesses in interpreting diverse types of visual data. The results provide valuable insights into the current capabilities of LLMs and identify key areas for improvement. This work establishes a foundational benchmark for future research and development aimed at enhancing the visual interpretative abilities of language models. In the future, improved LLMs with robust visual interpretation skills can significantly aid in automated data analysis, scientific research, educational tools, and business intelligence applications.
In-Context Learning of Physical Properties: Few-Shot Adaptation to Out-of-Distribution Molecular Graphs
Jun 03, 2024Large language models manifest the ability of few-shot adaptation to a sequence of provided examples. This behavior, known as in-context learning, allows for performing nontrivial machine learning tasks during inference only. In this work, we address the question: can we leverage in-context learning to predict out-of-distribution materials properties? However, this would not be possible for structure property prediction tasks unless an effective method is found to pass atomic-level geometric features to the transformer model. To address this problem, we employ a compound model in which GPT-2 acts on the output of geometry-aware graph neural networks to adapt in-context information. To demonstrate our model's capabilities, we partition the QM9 dataset into sequences of molecules that share a common substructure and use them for in-context learning. This approach significantly improves the performance of the model on out-of-distribution examples, surpassing the one of general graph neural network models.
Accurate estimation of feature importance faithfulness for tree models
Apr 04, 2024



In this paper, we consider a perturbation-based metric of predictive faithfulness of feature rankings (or attributions) that we call PGI squared. When applied to decision tree-based regression models, the metric can be computed accurately and efficiently for arbitrary independent feature perturbation distributions. In particular, the computation does not involve Monte Carlo sampling that has been typically used for computing similar metrics and which is inherently prone to inaccuracies. Moreover, we propose a method of ranking features by their importance for the tree model's predictions based on PGI squared. Our experiments indicate that in some respects, the method may identify the globally important features better than the state-of-the-art SHAP explainer
Scaling Laws for Fine-Grained Mixture of Experts
Feb 12, 2024



Mixture of Experts (MoE) models have emerged as a primary solution for reducing the computational cost of Large Language Models. In this work, we analyze their scaling properties, incorporating an expanded range of variables. Specifically, we introduce a new hyperparameter, granularity, whose adjustment enables precise control over the size of the experts. Building on this, we establish scaling laws for fine-grained MoE, taking into account the number of training tokens, model size, and granularity. Leveraging these laws, we derive the optimal training configuration for a given computational budget. Our findings not only show that MoE models consistently outperform dense Transformers but also highlight that the efficiency gap between dense and MoE models widens as we scale up the model size and training budget. Furthermore, we demonstrate that the common practice of setting the size of experts in MoE to mirror the feed-forward layer is not optimal at almost any computational budget.
Contrastive News and Social Media Linking using BERT for Articles and Tweets across Dual Platforms
Dec 11, 2023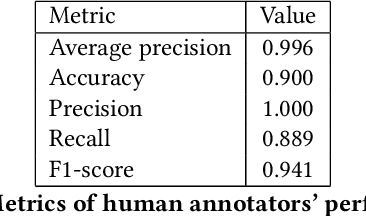
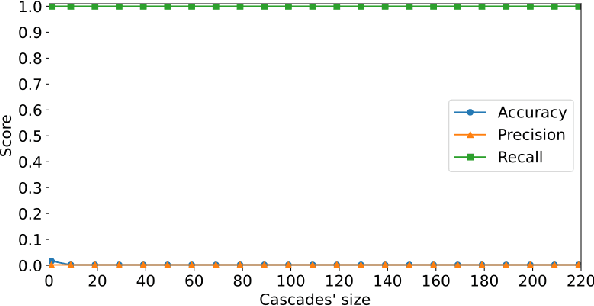
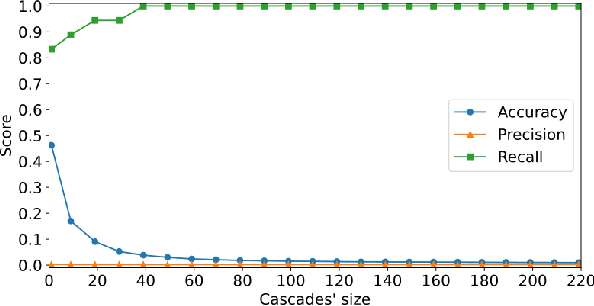

X (formerly Twitter) has evolved into a contemporary agora, offering a platform for individuals to express opinions and viewpoints on current events. The majority of the topics discussed on Twitter are directly related to ongoing events, making it an important source for monitoring public discourse. However, linking tweets to specific news presents a significant challenge due to their concise and informal nature. Previous approaches, including topic models, graph-based models, and supervised classifiers, have fallen short in effectively capturing the unique characteristics of tweets and articles. Inspired by the success of the CLIP model in computer vision, which employs contrastive learning to model similarities between images and captions, this paper introduces a contrastive learning approach for training a representation space where linked articles and tweets exhibit proximity. We present our contrastive learning approach, CATBERT (Contrastive Articles Tweets BERT), leveraging pre-trained BERT models. The model is trained and tested on a dataset containing manually labeled English and Polish tweets and articles related to the Russian-Ukrainian war. We evaluate CATBERT's performance against traditional approaches like LDA, and the novel method based on OpenAI embeddings, which has not been previously applied to this task. Our findings indicate that CATBERT demonstrates superior performance in associating tweets with relevant news articles. Furthermore, we demonstrate the performance of the models when applied to finding the main topic -- represented by an article -- of the whole cascade of tweets. In this new task, we report the performance of the different models in dependence on the cascade size.
Improving Ads-Profitability Using Traffic-Fingerprints
May 31, 2022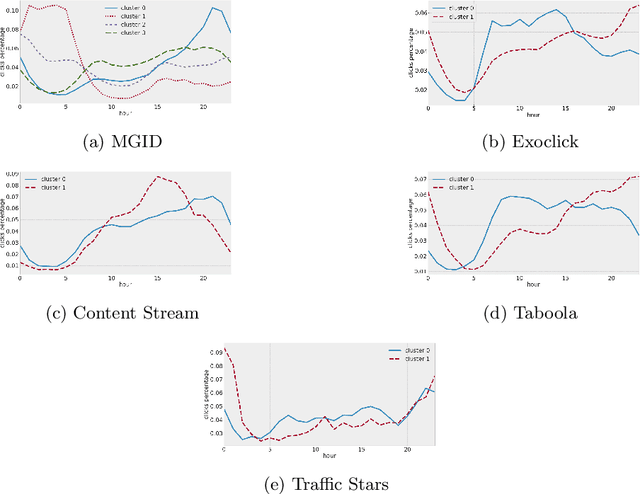
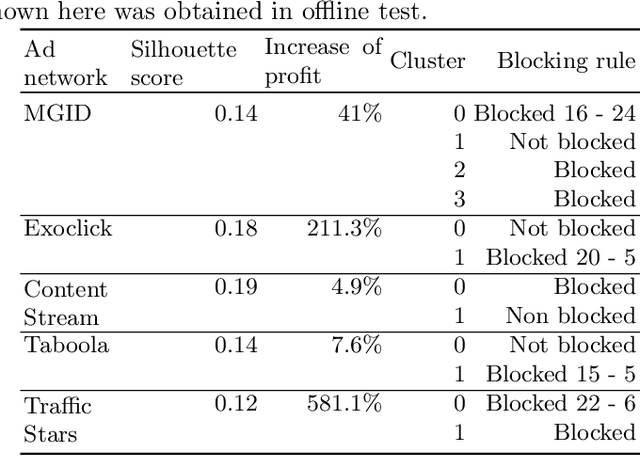
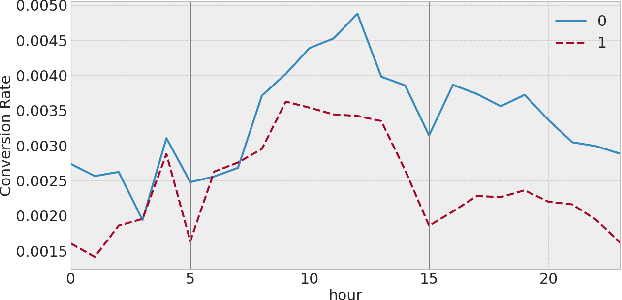
This paper introduces the concept of traffic-fingerprints, i.e., normalized 24-dimensional vectors representing a distribution of daily traffic on a web page. Using k-means clustering we show that similarity of traffic-fingerprints is related to the similarity of profitability time patterns for ads shown on these pages. In other words, these fingerprints are correlated with the conversions rates, thus allowing us to argue about conversion rates on pages with negligible traffic. By blocking or unblocking whole clusters of pages we were able to increase the revenue of online campaigns by more than 50%.
Improved Feature Importance Computations for Tree Models: Shapley vs. Banzhaf
Aug 09, 2021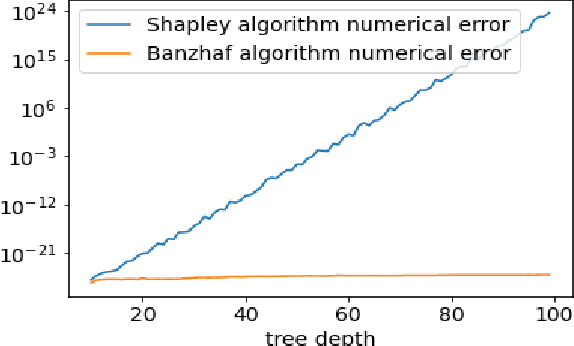
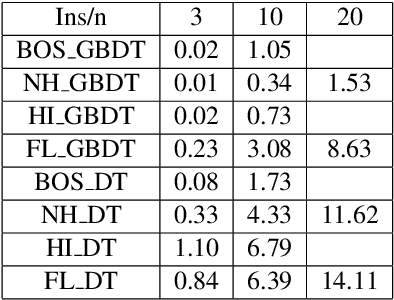
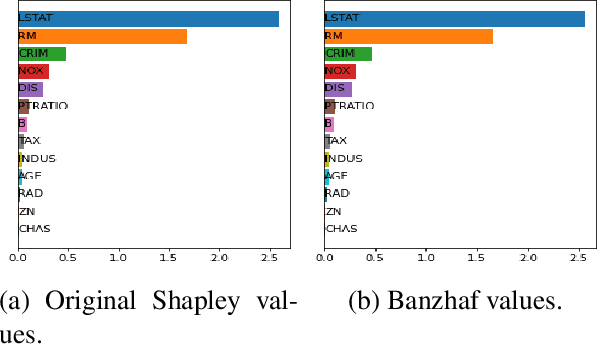
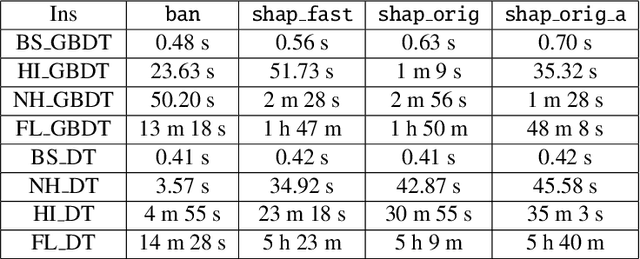
Shapley values are one of the main tools used to explain predictions of tree ensemble models. The main alternative to Shapley values are Banzhaf values that have not been understood equally well. In this paper we make a step towards filling this gap, providing both experimental and theoretical comparison of these model explanation methods. Surprisingly, we show that Banzhaf values offer several advantages over Shapley values while providing essentially the same explanations. We verify that Banzhaf values: (1) have a more intuitive interpretation, (2) allow for more efficient algorithms, and (3) are much more numerically robust. We provide an experimental evaluation of these theses. In particular, we show that on real world instances. Additionally, from a theoretical perspective we provide new and improved algorithm computing the same Shapley value based explanations as the algorithm of Lundberg et al. [Nat. Mach. Intell. 2020]. Our algorithm runs in $O(TLD+n)$ time, whereas the previous algorithm had $O(TLD^2+n)$ running time bound. Here, $T$ is the number of trees, $L$ is the maximum number of leaves in a tree, and $D$ denotes the maximum depth of a tree in the ensemble. Using the computational techniques developed for Shapley values we deliver an optimal $O(TL+n)$ time algorithm for computing Banzhaf values based explanations. In our experiments these algorithms give running times smaller even by an order of magnitude.