 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive News and Social Media Linking using BERT for Articles and Tweets across Dual Platforms
Paper and Code
Dec 11, 2023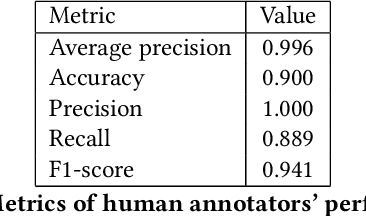
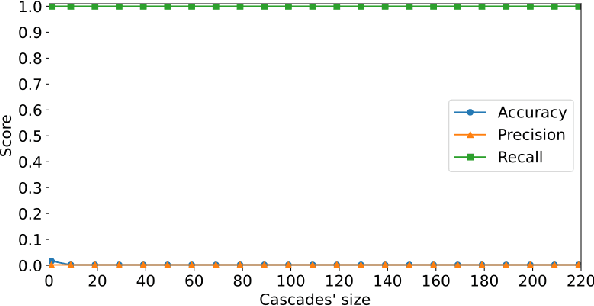
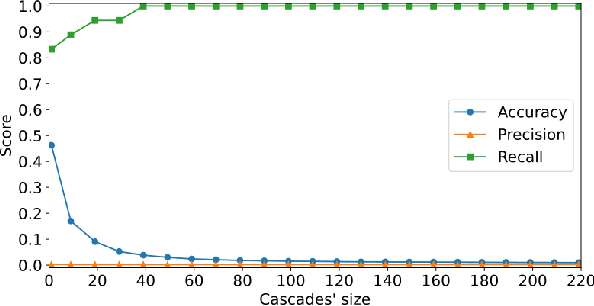

X (formerly Twitter) has evolved into a contemporary agora, offering a platform for individuals to express opinions and viewpoints on current events. The majority of the topics discussed on Twitter are directly related to ongoing events, making it an important source for monitoring public discourse. However, linking tweets to specific news presents a significant challenge due to their concise and informal nature. Previous approaches, including topic models, graph-based models, and supervised classifiers, have fallen short in effectively capturing the unique characteristics of tweets and articles. Inspired by the success of the CLIP model in computer vision, which employs contrastive learning to model similarities between images and captions, this paper introduces a contrastive learning approach for training a representation space where linked articles and tweets exhibit proximity. We present our contrastive learning approach, CATBERT (Contrastive Articles Tweets BERT), leveraging pre-trained BERT models. The model is trained and tested on a dataset containing manually labeled English and Polish tweets and articles related to the Russian-Ukrainian war. We evaluate CATBERT's performance against traditional approaches like LDA, and the novel method based on OpenAI embeddings, which has not been previously applied to this task. Our findings indicate that CATBERT demonstrates superior performance in associating tweets with relevant news articles. Furthermore, we demonstrate the performance of the models when applied to finding the main topic -- represented by an article -- of the whole cascade of tweets. In this new task, we report the performance of the different models in dependence on the cascade size.