 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
State Soup: In-Context Skill Learning, Retrieval and Mixing
Jun 12, 2024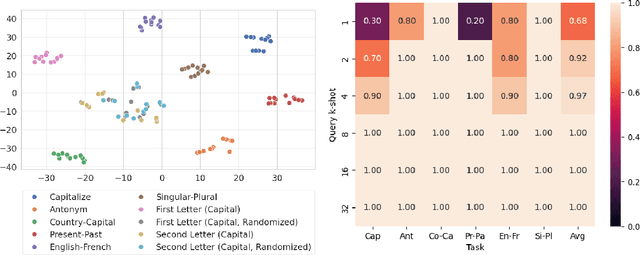
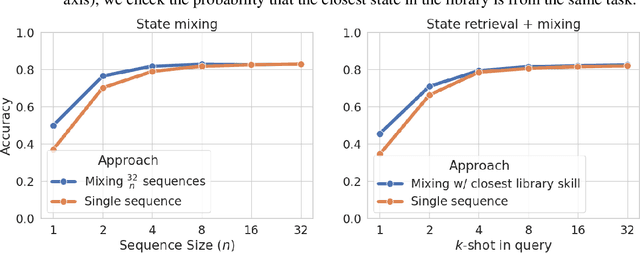
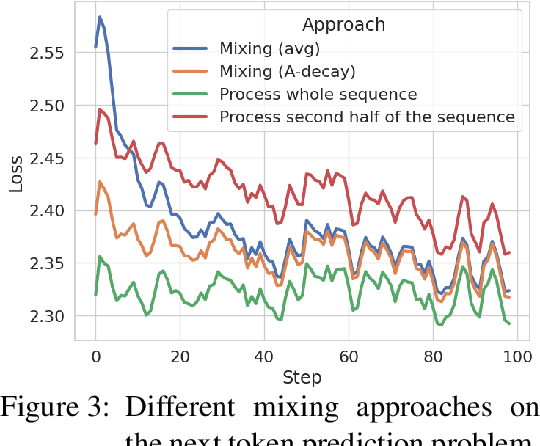
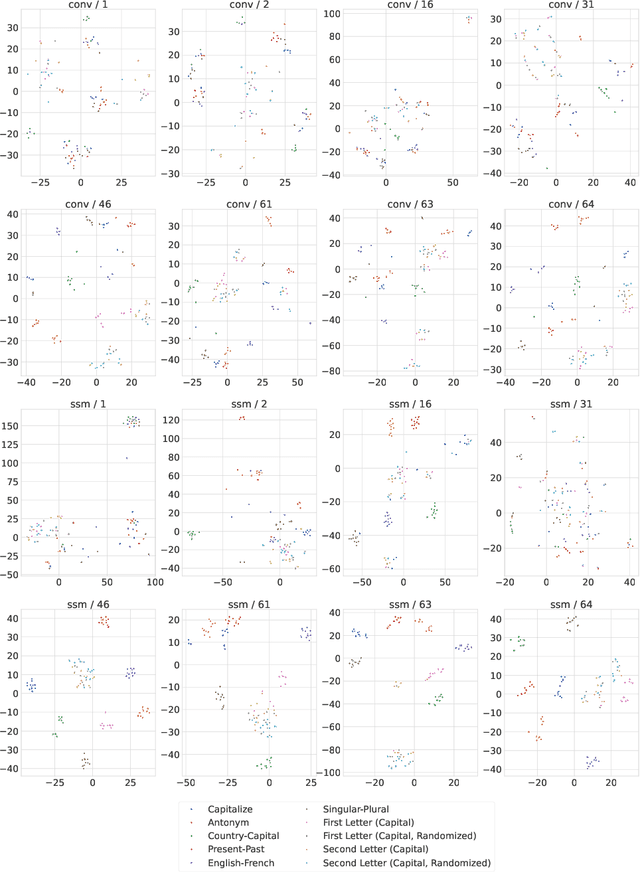
A new breed of gated-linear recurrent neural networks has reached state-of-the-art performance on a range of sequence modeling problems. Such models naturally handle long sequences efficiently, as the cost of processing a new input is independent of sequence length. Here, we explore another advantage of these stateful sequence models, inspired by the success of model merging through parameter interpolation. Building on parallels between fine-tuning and in-context learning, we investigate whether we can treat internal states as task vectors that can be stored, retrieved, and then linearly combined, exploiting the linearity of recurrence. We study this form of fast model merging on Mamba-2.8b, a pretrained recurrent model, and present preliminary evidence that simple linear state interpolation methods suffice to improve next-token perplexity as well as downstream in-context learning task performance.
Scaling Laws for Fine-Grained Mixture of Experts
Feb 12, 2024



Mixture of Experts (MoE) models have emerged as a primary solution for reducing the computational cost of Large Language Models. In this work, we analyze their scaling properties, incorporating an expanded range of variables. Specifically, we introduce a new hyperparameter, granularity, whose adjustment enables precise control over the size of the experts. Building on this, we establish scaling laws for fine-grained MoE, taking into account the number of training tokens, model size, and granularity. Leveraging these laws, we derive the optimal training configuration for a given computational budget. Our findings not only show that MoE models consistently outperform dense Transformers but also highlight that the efficiency gap between dense and MoE models widens as we scale up the model size and training budget. Furthermore, we demonstrate that the common practice of setting the size of experts in MoE to mirror the feed-forward layer is not optimal at almost any computational budget.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
Jan 08, 2024



State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
Mixture of Tokens: Efficient LLMs through Cross-Example Aggregation
Oct 24, 2023



Despite the promise of Mixture of Experts (MoE) models in increasing parameter counts of Transformer models while maintaining training and inference costs, their application carries notable drawbacks. The key strategy of these models is to, for each processed token, activate at most a few experts - subsets of an extensive feed-forward layer. But this approach is not without its challenges. The operation of matching experts and tokens is discrete, which makes MoE models prone to issues like training instability and uneven expert utilization. Existing techniques designed to address these concerns, such as auxiliary losses or balance-aware matching, result either in lower model performance or are more difficult to train. In response to these issues, we propose Mixture of Tokens, a fully-differentiable model that retains the benefits of MoE architectures while avoiding the aforementioned difficulties. Rather than routing tokens to experts, this approach mixes tokens from different examples prior to feeding them to experts, enabling the model to learn from all token-expert combinations. Importantly, this mixing can be disabled to avoid mixing of different sequences during inference. Crucially, this method is fully compatible with both masked and causal Large Language Model training and inference.