 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSince Faithfulness Fails: The Performance Limits of Neural Causal Discovery
Feb 22, 2025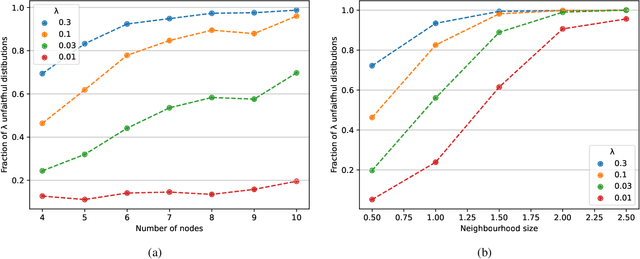



Neural causal discovery methods have recently improved in terms of scalability and computational efficiency. However, our systematic evaluation highlights significant room for improvement in their accuracy when uncovering causal structures. We identify a fundamental limitation: neural networks cannot reliably distinguish between existing and non-existing causal relationships in the finite sample regime. Our experiments reveal that neural networks, as used in contemporary causal discovery approaches, lack the precision needed to recover ground-truth graphs, even for small graphs and relatively large sample sizes. Furthermore, we identify the faithfulness property as a critical bottleneck: (i) it is likely to be violated across any reasonable dataset size range, and (ii) its violation directly undermines the performance of neural discovery methods. These findings lead us to conclude that progress within the current paradigm is fundamentally constrained, necessitating a paradigm shift in this domain.
tsGT: Stochastic Time Series Modeling With Transformer
Mar 15, 2024Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
Trust Your $ abla$: Gradient-based Intervention Targeting for Causal Discovery
Nov 24, 2022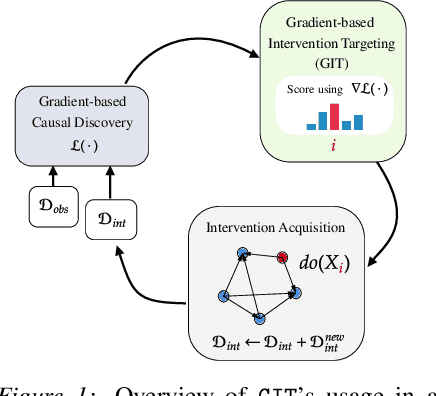

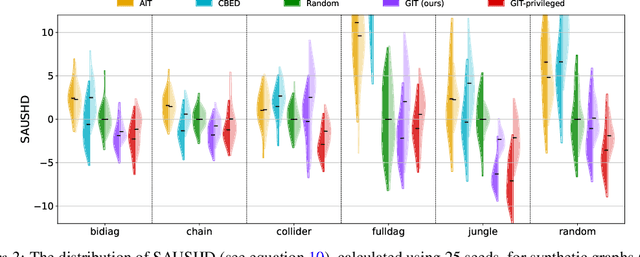

Inferring causal structure from data is a challenging task of fundamental importance in science. Observational data are often insufficient to identify a system's causal structure uniquely. While conducting interventions (i.e., experiments) can improve the identifiability, such samples are usually challenging and expensive to obtain. Hence, experimental design approaches for causal discovery aim to minimize the number of interventions by estimating the most informative intervention target. In this work, we propose a novel Gradient-based Intervention Targeting method, abbreviated GIT, that 'trusts' the gradient estimator of a gradient-based causal discovery framework to provide signals for the intervention acquisition function. We provide extensive experiments in simulated and real-world datasets and demonstrate that GIT performs on par with competitive baselines, surpassing them in the low-data regime.
Continuous Control With Ensemble Deep Deterministic Policy Gradients
Nov 30, 2021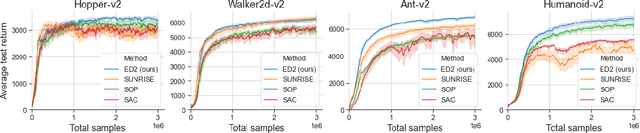
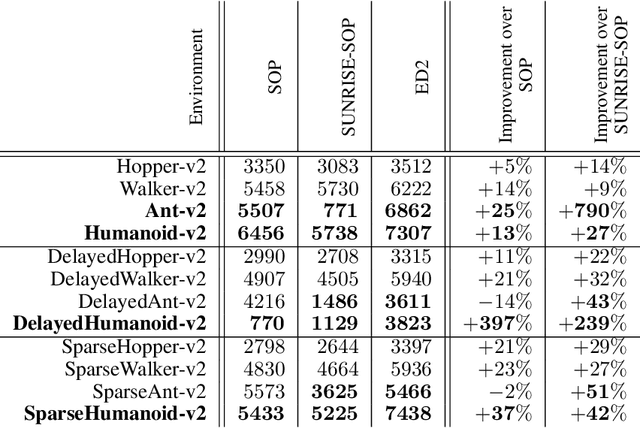
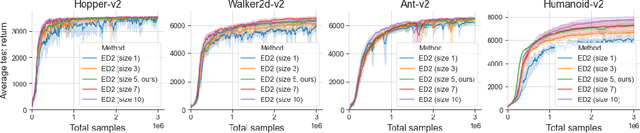

The growth of deep reinforcement learning (RL) has brought multiple exciting tools and methods to the field. This rapid expansion makes it important to understand the interplay between individual elements of the RL toolbox. We approach this task from an empirical perspective by conducting a study in the continuous control setting. We present multiple insights of fundamental nature, including: an average of multiple actors trained from the same data boosts performance; the existing methods are unstable across training runs, epochs of training, and evaluation runs; a commonly used additive action noise is not required for effective training; a strategy based on posterior sampling explores better than the approximated UCB combined with the weighted Bellman backup; the weighted Bellman backup alone cannot replace the clipped double Q-Learning; the critics' initialization plays the major role in ensemble-based actor-critic exploration. As a conclusion, we show how existing tools can be brought together in a novel way, giving rise to the Ensemble Deep Deterministic Policy Gradients (ED2) method, to yield state-of-the-art results on continuous control tasks from OpenAI Gym MuJoCo. From the practical side, ED2 is conceptually straightforward, easy to code, and does not require knowledge outside of the existing RL toolbox.