 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley Pruning for Neural Network Compression
Jul 19, 2024Neural network pruning is a rich field with a variety of approaches. In this work, we propose to connect the existing pruning concepts such as leave-one-out pruning and oracle pruning and develop them into a more general Shapley value-based framework that targets the compression of convolutional neural networks. To allow for practical applications in utilizing the Shapley value, this work presents the Shapley value approximations, and performs the comparative analysis in terms of cost-benefit utility for the neural network compression. The proposed ranks are evaluated against a new benchmark, Oracle rank, constructed based on oracle sets. The broad experiments show that the proposed normative ranking and its approximations show practical results, obtaining state-of-the-art network compression.
Implicit Neural Representations for Image Compression
Dec 08, 2021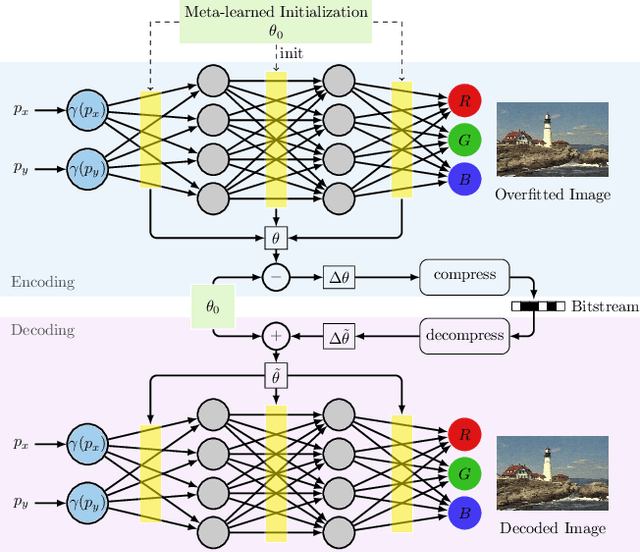
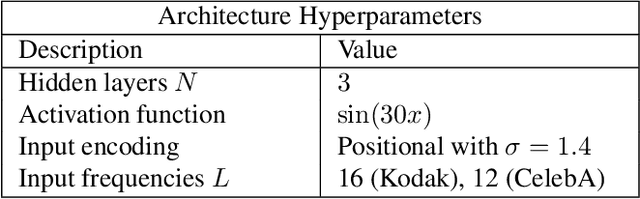

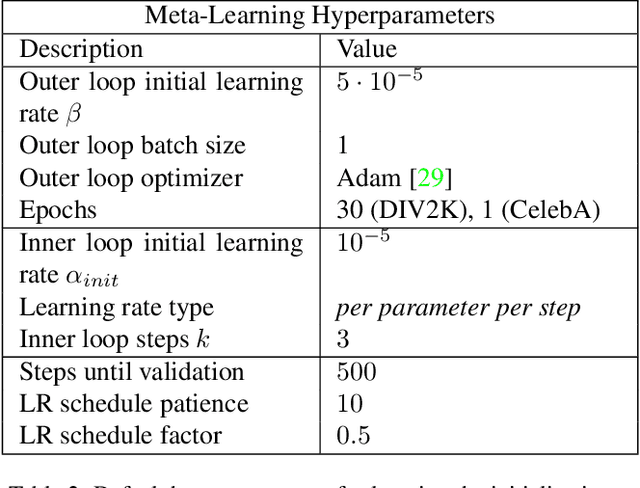
Recently Implicit Neural Representations (INRs) gained attention as a novel and effective representation for various data types. Thus far, prior work mostly focused on optimizing their reconstruction performance. This work investigates INRs from a novel perspective, i.e., as a tool for image compression. To this end, we propose the first comprehensive compression pipeline based on INRs including quantization, quantization-aware retraining and entropy coding. Encoding with INRs, i.e. overfitting to a data sample, is typically orders of magnitude slower. To mitigate this drawback, we leverage meta-learned initializations based on MAML to reach the encoding in fewer gradient updates which also generally improves rate-distortion performance of INRs. We find that our approach to source compression with INRs vastly outperforms similar prior work, is competitive with common compression algorithms designed specifically for images and closes the gap to state-of-the-art learned approaches based on Rate-Distortion Autoencoders. Moreover, we provide an extensive ablation study on the importance of individual components of our method which we hope facilitates future research on this novel approach to image compression.
Safe Motion Planning for Autonomous Driving using an Adversarial Road Model
May 15, 2020



This paper presents a game-theoretic path-following formulation where the opponent is an adversary road model. This formulation allows us to compute safe sets using tools from viability theory, that can be used as terminal constraints in an optimization-based motion planner. Based on the adversary road model, we first derive an analytical discriminating domain, which even allows guaranteeing safety in the case when steering rate constraints are considered. Second, we compute the discriminating kernel and show that the output of the gridding based algorithm can be accurately approximated by a fully connected neural network, which can again be used as a terminal constraint. Finally, we show that by using our proposed safe sets, an optimization-based motion planner can successfully drive on city and country roads with prediction horizons too short for other baselines to complete the task.
Learning Unsupervised Hierarchical Part Decomposition of 3D Objects from a Single RGB Image
Apr 02, 2020


Humans perceive the 3D world as a set of distinct objects that are characterized by various low-level (geometry, reflectance) and high-level (connectivity, adjacency, symmetry) properties. Recent methods based on convolutional neural networks (CNNs) demonstrated impressive progress in 3D reconstruction, even when using a single 2D image as input. However, the majority of these methods focuses on recovering the local 3D geometry of an object without considering its part-based decomposition or relations between parts. We address this challenging problem by proposing a novel formulation that allows to jointly recover the geometry of a 3D object as a set of primitives as well as their latent hierarchical structure without part-level supervision. Our model recovers the higher level structural decomposition of various objects in the form of a binary tree of primitives, where simple parts are represented with fewer primitives and more complex parts are modeled with more components. Our experiments on the ShapeNet and D-FAUST datasets demonstrate that considering the organization of parts indeed facilitates reasoning about 3D geometry.
3D Appearance Super-Resolution with Deep Learning
Jun 04, 2019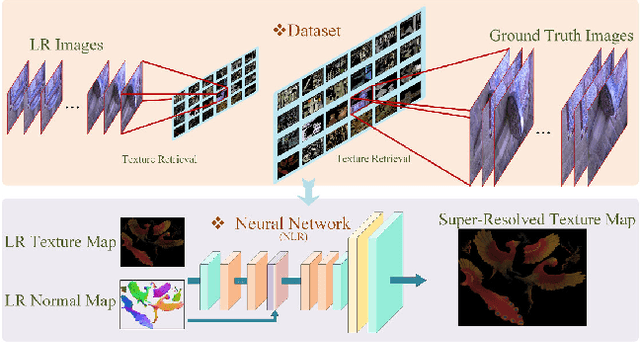

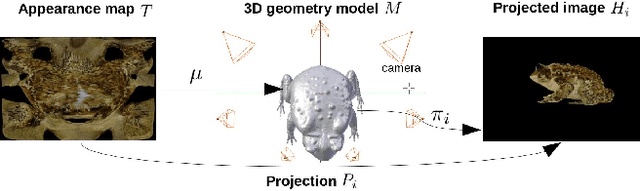
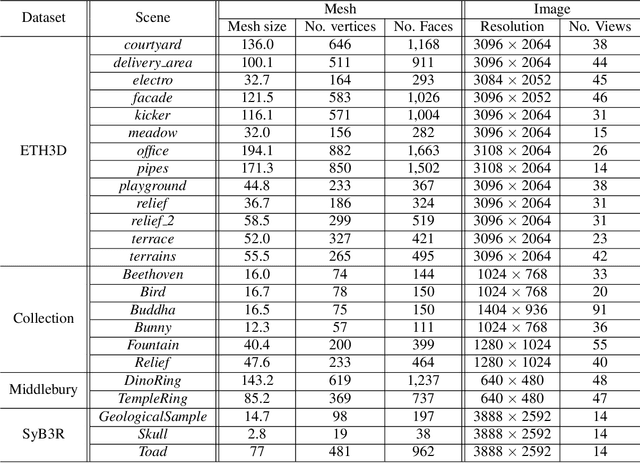
We tackle the problem of retrieving high-resolution (HR) texture maps of objects that are captured from multiple view points. In the multi-view case, model-based super-resolution (SR) methods have been recently proved to recover high quality texture maps. On the other hand, the advent of deep learning-based methods has already a significant impact on the problem of video and image SR. Yet, a deep learning-based approach to super-resolve the appearance of 3D objects is still missing. The main limitation of exploiting the power of deep learning techniques in the multi-view case is the lack of data. We introduce a 3D appearance SR (3DASR) dataset based on the existing ETH3D [42], SyB3R [31], MiddleBury, and our Collection of 3D scenes from TUM [21], Fountain [51] and Relief [53]. We provide the high- and low-resolution texture maps, the 3D geometric model, images and projection matrices. We exploit the power of 2D learning-based SR methods and design networks suitable for the 3D multi-view case. We incorporate the geometric information by introducing normal maps and further improve the learning process. Experimental results demonstrate that our proposed networks successfully incorporate the 3D geometric information and super-resolve the texture maps.
RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials
Jan 06, 2019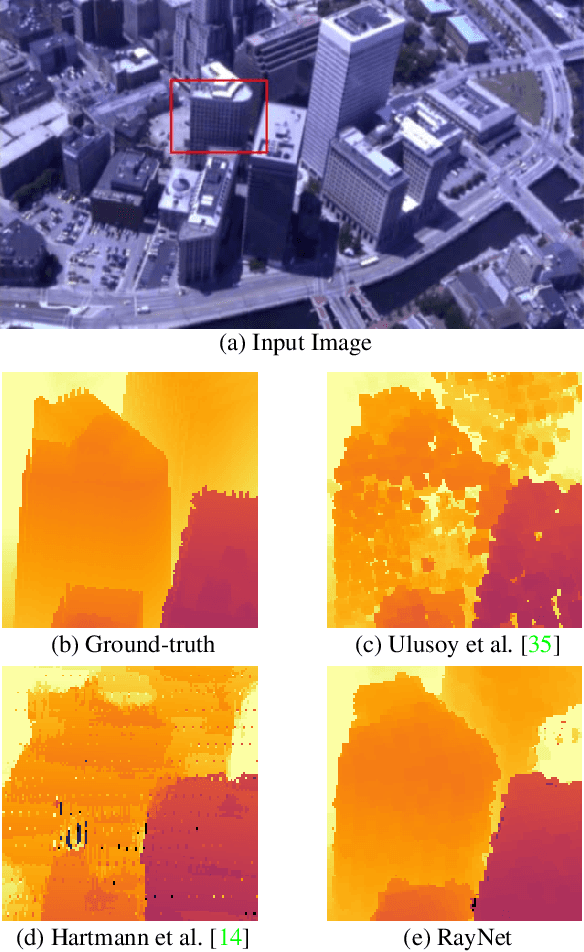


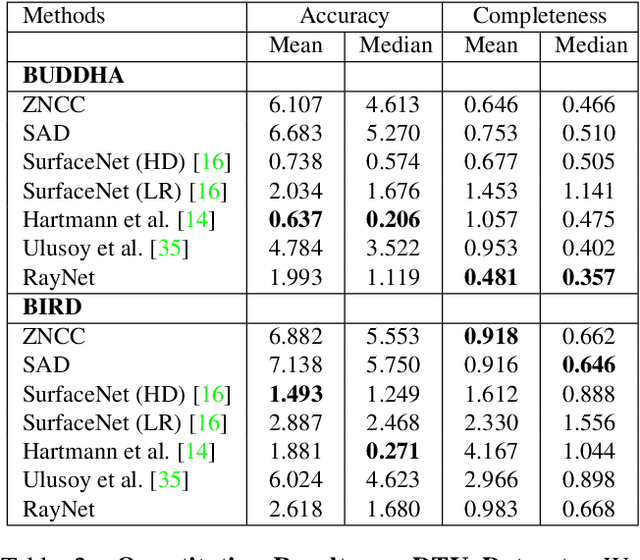
In this paper, we consider the problem of reconstructing a dense 3D model using images captured from different views. Recent methods based on convolutional neural networks (CNN) allow learning the entire task from data. However, they do not incorporate the physics of image formation such as perspective geometry and occlusion. Instead, classical approaches based on Markov Random Fields (MRF) with ray-potentials explicitly model these physical processes, but they cannot cope with large surface appearance variations across different viewpoints. In this paper, we propose RayNet, which combines the strengths of both frameworks. RayNet integrates a CNN that learns view-invariant feature representations with an MRF that explicitly encodes the physics of perspective projection and occlusion. We train RayNet end-to-end using empirical risk minimization. We thoroughly evaluate our approach on challenging real-world datasets and demonstrate its benefits over a piece-wise trained baseline, hand-crafted models as well as other learning-based approaches.
Unsupervised Deep Single-Image Intrinsic Decomposition using Illumination-Varying Image Sequences
Sep 03, 2018



Machine learning based Single Image Intrinsic Decomposition (SIID) methods decompose a captured scene into its albedo and shading images by using the knowledge of a large set of known and realistic ground truth decompositions. Collecting and annotating such a dataset is an approach that cannot scale to sufficient variety and realism. We free ourselves from this limitation by training on unannotated images. Our method leverages the observation that two images of the same scene but with different lighting provide useful information on their intrinsic properties: by definition, albedo is invariant to lighting conditions, and cross-combining the estimated albedo of a first image with the estimated shading of a second one should lead back to the second one's input image. We transcribe this relationship into a siamese training scheme for a deep convolutional neural network that decomposes a single image into albedo and shading. The siamese setting allows us to introduce a new loss function including such cross-combinations, and to train solely on (time-lapse) images, discarding the need for any ground truth annotations. As a result, our method has the good properties of i) taking advantage of the time-varying information of image sequences in the (pre-computed) training step, ii) not requiring ground truth data to train on, and iii) being able to decompose single images of unseen scenes at runtime. To demonstrate and evaluate our work, we additionally propose a new rendered dataset containing illumination-varying scenes and a set of quantitative metrics to evaluate SIID algorithms. Despite its unsupervised nature, our results compete with state of the art methods, including supervised and non data-driven methods.