 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-centric Cross-modal Feature Distillation for Event-based Object Detection
Nov 09, 2023Event cameras are gaining popularity due to their unique properties, such as their low latency and high dynamic range. One task where these benefits can be crucial is real-time object detection. However, RGB detectors still outperform event-based detectors due to the sparsity of the event data and missing visual details. In this paper, we develop a novel knowledge distillation approach to shrink the performance gap between these two modalities. To this end, we propose a cross-modality object detection distillation method that by design can focus on regions where the knowledge distillation works best. We achieve this by using an object-centric slot attention mechanism that can iteratively decouple features maps into object-centric features and corresponding pixel-features used for distillation. We evaluate our novel distillation approach on a synthetic and a real event dataset with aligned grayscale images as a teacher modality. We show that object-centric distillation allows to significantly improve the performance of the event-based student object detector, nearly halving the performance gap with respect to the teacher.
Leveraging 2D Data to Learn Textured 3D Mesh Generation
Apr 08, 2020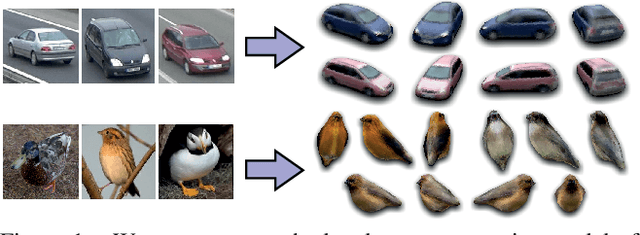
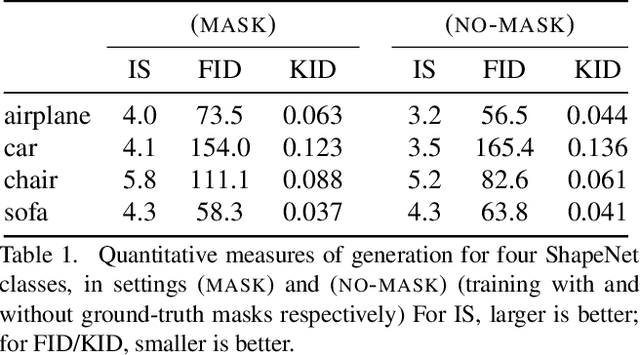
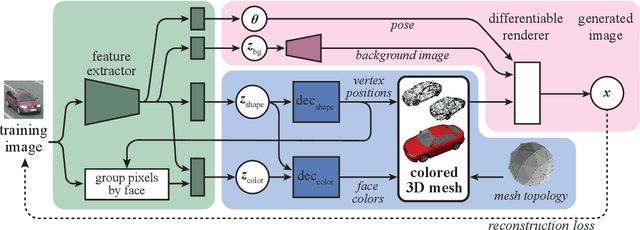
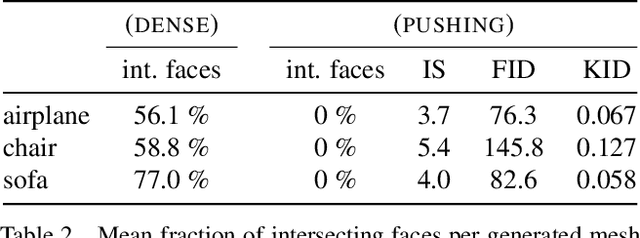
Numerous methods have been proposed for probabilistic generative modelling of 3D objects. However, none of these is able to produce textured objects, which renders them of limited use for practical tasks. In this work, we present the first generative model of textured 3D meshes. Training such a model would traditionally require a large dataset of textured meshes, but unfortunately, existing datasets of meshes lack detailed textures. We instead propose a new training methodology that allows learning from collections of 2D images without any 3D information. To do so, we train our model to explain a distribution of images by modelling each image as a 3D foreground object placed in front of a 2D background. Thus, it learns to generate meshes that when rendered, produce images similar to those in its training set. A well-known problem when generating meshes with deep networks is the emergence of self-intersections, which are problematic for many use-cases. As a second contribution we therefore introduce a new generation process for 3D meshes that guarantees no self-intersections arise, based on the physical intuition that faces should push one another out of the way as they move. We conduct extensive experiments on our approach, reporting quantitative and qualitative results on both synthetic data and natural images. These show our method successfully learns to generate plausible and diverse textured 3D samples for five challenging object classes.
Learned Multi-View Texture Super-Resolution
Jan 14, 2020

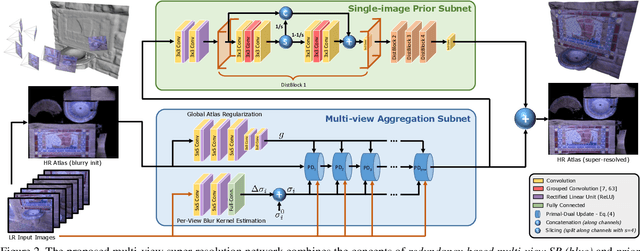
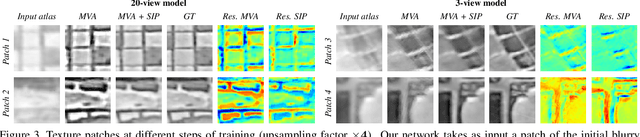
We present a super-resolution method capable of creating a high-resolution texture map for a virtual 3D object from a set of lower-resolution images of that object. Our architecture unifies the concepts of (i) multi-view super-resolution based on the redundancy of overlapping views and (ii) single-view super-resolution based on a learned prior of high-resolution (HR) image structure. The principle of multi-view super-resolution is to invert the image formation process and recover the latent HR texture from multiple lower-resolution projections. We map that inverse problem into a block of suitably designed neural network layers, and combine it with a standard encoder-decoder network for learned single-image super-resolution. Wiring the image formation model into the network avoids having to learn perspective mapping from textures to images, and elegantly handles a varying number of input views. Experiments demonstrate that the combination of multi-view observations and learned prior yields improved texture maps.
3D Appearance Super-Resolution with Deep Learning
Jun 04, 2019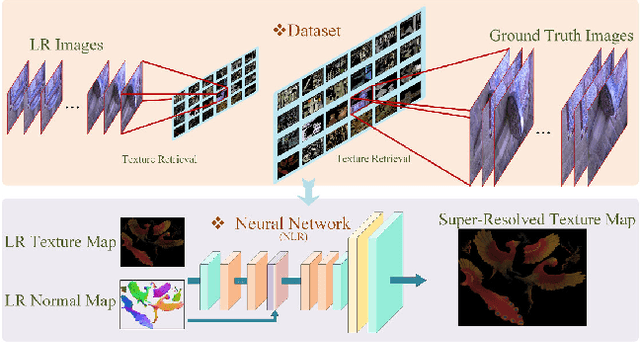

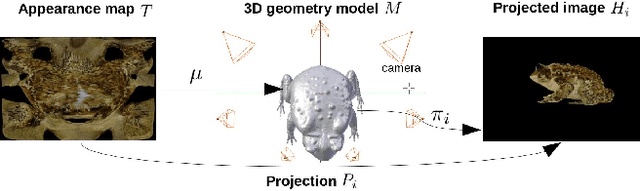
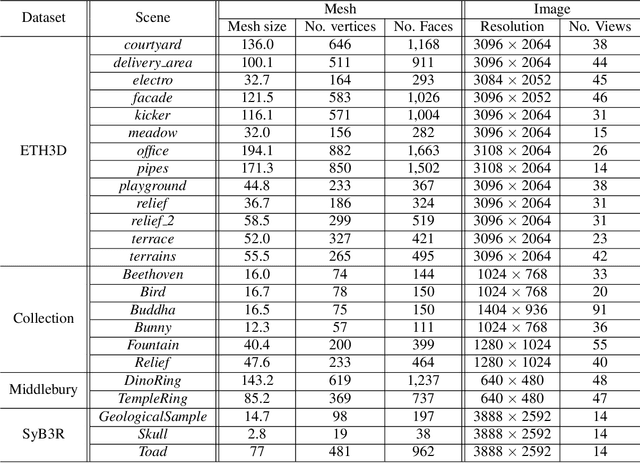
We tackle the problem of retrieving high-resolution (HR) texture maps of objects that are captured from multiple view points. In the multi-view case, model-based super-resolution (SR) methods have been recently proved to recover high quality texture maps. On the other hand, the advent of deep learning-based methods has already a significant impact on the problem of video and image SR. Yet, a deep learning-based approach to super-resolve the appearance of 3D objects is still missing. The main limitation of exploiting the power of deep learning techniques in the multi-view case is the lack of data. We introduce a 3D appearance SR (3DASR) dataset based on the existing ETH3D [42], SyB3R [31], MiddleBury, and our Collection of 3D scenes from TUM [21], Fountain [51] and Relief [53]. We provide the high- and low-resolution texture maps, the 3D geometric model, images and projection matrices. We exploit the power of 2D learning-based SR methods and design networks suitable for the 3D multi-view case. We incorporate the geometric information by introducing normal maps and further improve the learning process. Experimental results demonstrate that our proposed networks successfully incorporate the 3D geometric information and super-resolve the texture maps.