 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Multi-View Texture Super-Resolution
Paper and Code


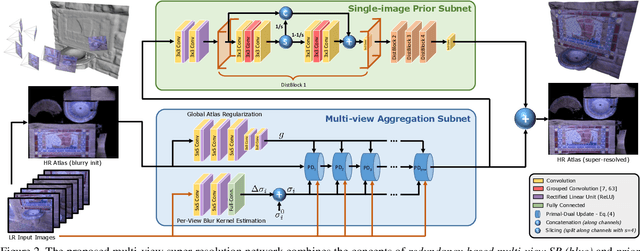
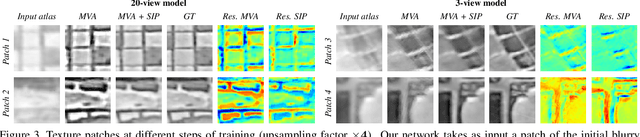
We present a super-resolution method capable of creating a high-resolution texture map for a virtual 3D object from a set of lower-resolution images of that object. Our architecture unifies the concepts of (i) multi-view super-resolution based on the redundancy of overlapping views and (ii) single-view super-resolution based on a learned prior of high-resolution (HR) image structure. The principle of multi-view super-resolution is to invert the image formation process and recover the latent HR texture from multiple lower-resolution projections. We map that inverse problem into a block of suitably designed neural network layers, and combine it with a standard encoder-decoder network for learned single-image super-resolution. Wiring the image formation model into the network avoids having to learn perspective mapping from textures to images, and elegantly handles a varying number of input views. Experiments demonstrate that the combination of multi-view observations and learned prior yields improved texture maps.