 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAPLAN: A 3D Point Descriptor for Shape Completion
Jul 31, 2020

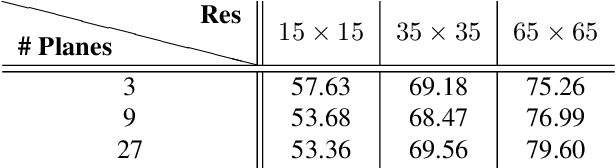
We present a novel 3D shape completion method that operates directly on unstructured point clouds, thus avoiding resource-intensive data structures like voxel grids. To this end, we introduce KAPLAN, a 3D point descriptor that aggregates local shape information via a series of 2D convolutions. The key idea is to project the points in a local neighborhood onto multiple planes with different orientations. In each of those planes, point properties like normals or point-to-plane distances are aggregated into a 2D grid and abstracted into a feature representation with an efficient 2D convolutional encoder. Since all planes are encoded jointly, the resulting representation nevertheless can capture their correlations and retains knowledge about the underlying 3D shape, without expensive 3D convolutions. Experiments on public datasets show that KAPLAN achieves state-of-the-art performance for 3D shape completion.
Learned Multi-View Texture Super-Resolution
Jan 14, 2020

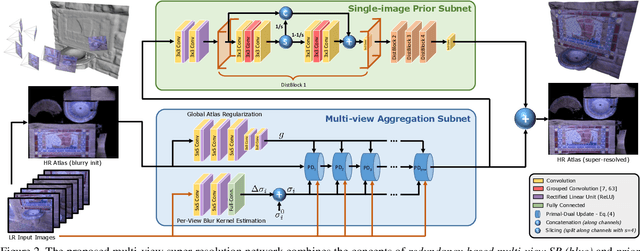
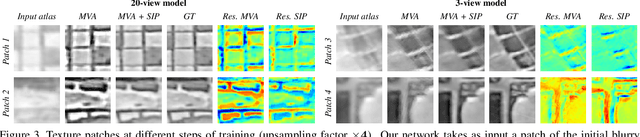
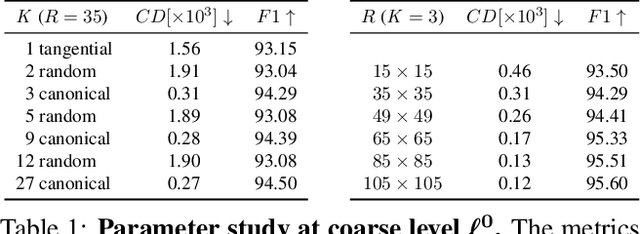
We present a super-resolution method capable of creating a high-resolution texture map for a virtual 3D object from a set of lower-resolution images of that object. Our architecture unifies the concepts of (i) multi-view super-resolution based on the redundancy of overlapping views and (ii) single-view super-resolution based on a learned prior of high-resolution (HR) image structure. The principle of multi-view super-resolution is to invert the image formation process and recover the latent HR texture from multiple lower-resolution projections. We map that inverse problem into a block of suitably designed neural network layers, and combine it with a standard encoder-decoder network for learned single-image super-resolution. Wiring the image formation model into the network avoids having to learn perspective mapping from textures to images, and elegantly handles a varying number of input views. Experiments demonstrate that the combination of multi-view observations and learned prior yields improved texture maps.
Semantic 3D Reconstruction with Finite Element Bases
Oct 04, 2017

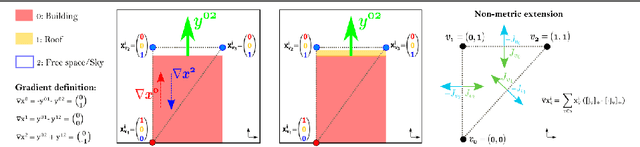

We propose a novel framework for the discretisation of multi-label problems on arbitrary, continuous domains. Our work bridges the gap between general FEM discretisations, and labeling problems that arise in a variety of computer vision tasks, including for instance those derived from the generalised Potts model. Starting from the popular formulation of labeling as a convex relaxation by functional lifting, we show that FEM discretisation is valid for the most general case, where the regulariser is anisotropic and non-metric. While our findings are generic and applicable to different vision problems, we demonstrate their practical implementation in the context of semantic 3D reconstruction, where such regularisers have proved particularly beneficial. The proposed FEM approach leads to a smaller memory footprint as well as faster computation, and it constitutes a very simple way to enable variable, adaptive resolution within the same model.
Semantically Informed Multiview Surface Refinement
Jun 26, 2017
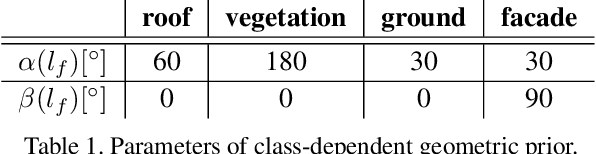
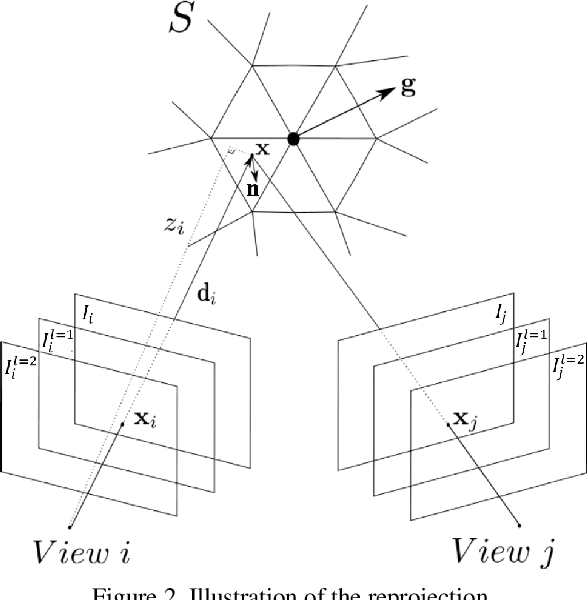

We present a method to jointly refine the geometry and semantic segmentation of 3D surface meshes. Our method alternates between updating the shape and the semantic labels. In the geometry refinement step, the mesh is deformed with variational energy minimization, such that it simultaneously maximizes photo-consistency and the compatibility of the semantic segmentations across a set of calibrated images. Label-specific shape priors account for interactions between the geometry and the semantic labels in 3D. In the semantic segmentation step, the labels on the mesh are updated with MRF inference, such that they are compatible with the semantic segmentations in the input images. Also, this step includes prior assumptions about the surface shape of different semantic classes. The priors induce a tight coupling, where semantic information influences the shape update and vice versa. Specifically, we introduce priors that favor (i) adaptive smoothing, depending on the class label; (ii) straightness of class boundaries; and (iii) semantic labels that are consistent with the surface orientation. The novel mesh-based reconstruction is evaluated in a series of experiments with real and synthetic data. We compare both to state-of-the-art, voxel-based semantic 3D reconstruction, and to purely geometric mesh refinement, and demonstrate that the proposed scheme yields improved 3D geometry as well as an improved semantic segmentation.