 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAPLAN: A 3D Point Descriptor for Shape Completion
Jul 31, 2020

We present a novel 3D shape completion method that operates directly on unstructured point clouds, thus avoiding resource-intensive data structures like voxel grids. To this end, we introduce KAPLAN, a 3D point descriptor that aggregates local shape information via a series of 2D convolutions. The key idea is to project the points in a local neighborhood onto multiple planes with different orientations. In each of those planes, point properties like normals or point-to-plane distances are aggregated into a 2D grid and abstracted into a feature representation with an efficient 2D convolutional encoder. Since all planes are encoded jointly, the resulting representation nevertheless can capture their correlations and retains knowledge about the underlying 3D shape, without expensive 3D convolutions. Experiments on public datasets show that KAPLAN achieves state-of-the-art performance for 3D shape completion.
Learned Multi-View Texture Super-Resolution
Jan 14, 2020

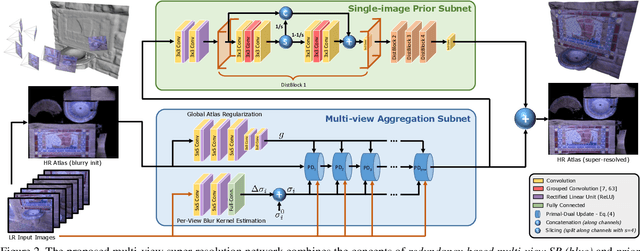
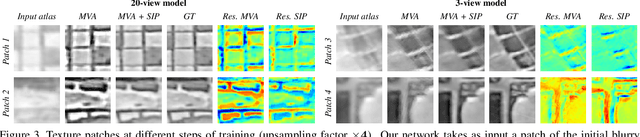
We present a super-resolution method capable of creating a high-resolution texture map for a virtual 3D object from a set of lower-resolution images of that object. Our architecture unifies the concepts of (i) multi-view super-resolution based on the redundancy of overlapping views and (ii) single-view super-resolution based on a learned prior of high-resolution (HR) image structure. The principle of multi-view super-resolution is to invert the image formation process and recover the latent HR texture from multiple lower-resolution projections. We map that inverse problem into a block of suitably designed neural network layers, and combine it with a standard encoder-decoder network for learned single-image super-resolution. Wiring the image formation model into the network avoids having to learn perspective mapping from textures to images, and elegantly handles a varying number of input views. Experiments demonstrate that the combination of multi-view observations and learned prior yields improved texture maps.
Learned Semantic Multi-Sensor Depth Map Fusion
Sep 02, 2019
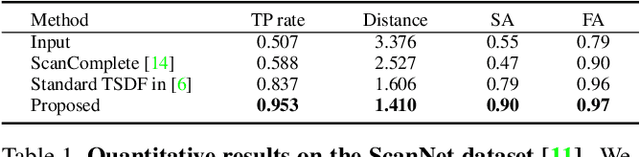
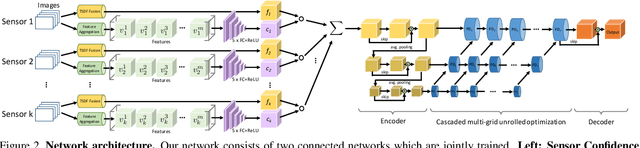

Volumetric depth map fusion based on truncated signed distance functions has become a standard method and is used in many 3D reconstruction pipelines. In this paper, we are generalizing this classic method in multiple ways: 1) Semantics: Semantic information enriches the scene representation and is incorporated into the fusion process. 2) Multi-Sensor: Depth information can originate from different sensors or algorithms with very different noise and outlier statistics which are considered during data fusion. 3) Scene denoising and completion: Sensors can fail to recover depth for certain materials and light conditions, or data is missing due to occlusions. Our method denoises the geometry, closes holes and computes a watertight surface for every semantic class. 4) Learning: We propose a neural network reconstruction method that unifies all these properties within a single powerful framework. Our method learns sensor or algorithm properties jointly with semantic depth fusion and scene completion and can also be used as an expert system, e.g. to unify the strengths of various photometric stereo algorithms. Our approach is the first to unify all these properties. Experimental evaluations on both synthetic and real data sets demonstrate clear improvements.