 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImLoc: Revisiting Visual Localization with Image-based Representation
Jan 07, 2026Existing visual localization methods are typically either 2D image-based, which are easy to build and maintain but limited in effective geometric reasoning, or 3D structure-based, which achieve high accuracy but require a centralized reconstruction and are difficult to update. In this work, we revisit visual localization with a 2D image-based representation and propose to augment each image with estimated depth maps to capture the geometric structure. Supported by the effective use of dense matchers, this representation is not only easy to build and maintain, but achieves highest accuracy in challenging conditions. With compact compression and a GPU-accelerated LO-RANSAC implementation, the whole pipeline is efficient in both storage and computation and allows for a flexible trade-off between accuracy and highest memory efficiency. Our method achieves a new state-of-the-art accuracy on various standard benchmarks and outperforms existing memory-efficient methods at comparable map sizes. Code will be available at https://github.com/cvg/Hierarchical-Localization.
R-SCoRe: Revisiting Scene Coordinate Regression for Robust Large-Scale Visual Localization
Jan 02, 2025



Learning-based visual localization methods that use scene coordinate regression (SCR) offer the advantage of smaller map sizes. However, on datasets with complex illumination changes or image-level ambiguities, it remains a less robust alternative to feature matching methods. This work aims to close the gap. We introduce a covisibility graph-based global encoding learning and data augmentation strategy, along with a depth-adjusted reprojection loss to facilitate implicit triangulation. Additionally, we revisit the network architecture and local feature extraction module. Our method achieves state-of-the-art on challenging large-scale datasets without relying on network ensembles or 3D supervision. On Aachen Day-Night, we are 10$\times$ more accurate than previous SCR methods with similar map sizes and require at least 5$\times$ smaller map sizes than any other SCR method while still delivering superior accuracy. Code will be available at: https://github.com/cvg/scrstudio .
GLACE: Global Local Accelerated Coordinate Encoding
Jun 06, 2024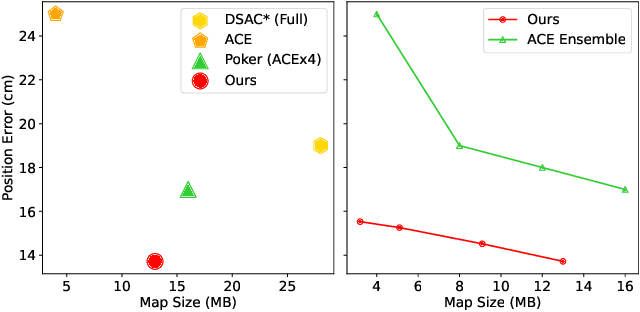
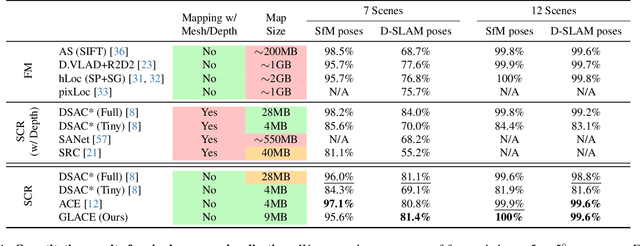
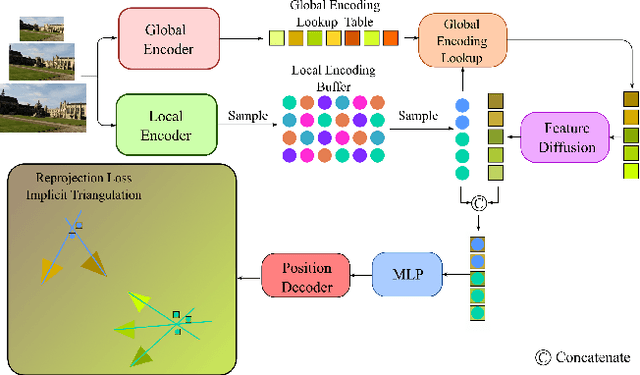
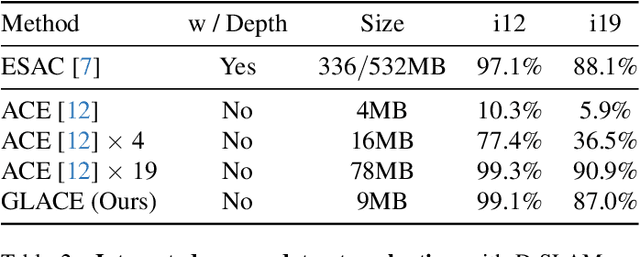
Scene coordinate regression (SCR) methods are a family of visual localization methods that directly regress 2D-3D matches for camera pose estimation. They are effective in small-scale scenes but face significant challenges in large-scale scenes that are further amplified in the absence of ground truth 3D point clouds for supervision. Here, the model can only rely on reprojection constraints and needs to implicitly triangulate the points. The challenges stem from a fundamental dilemma: The network has to be invariant to observations of the same landmark at different viewpoints and lighting conditions, etc., but at the same time discriminate unrelated but similar observations. The latter becomes more relevant and severe in larger scenes. In this work, we tackle this problem by introducing the concept of co-visibility to the network. We propose GLACE, which integrates pre-trained global and local encodings and enables SCR to scale to large scenes with only a single small-sized network. Specifically, we propose a novel feature diffusion technique that implicitly groups the reprojection constraints with co-visibility and avoids overfitting to trivial solutions. Additionally, our position decoder parameterizes the output positions for large-scale scenes more effectively. Without using 3D models or depth maps for supervision, our method achieves state-of-the-art results on large-scale scenes with a low-map-size model. On Cambridge landmarks, with a single model, we achieve 17% lower median position error than Poker, the ensemble variant of the state-of-the-art SCR method ACE. Code is available at: https://github.com/cvg/glace.
F$^3$Loc: Fusion and Filtering for Floorplan Localization
Mar 05, 2024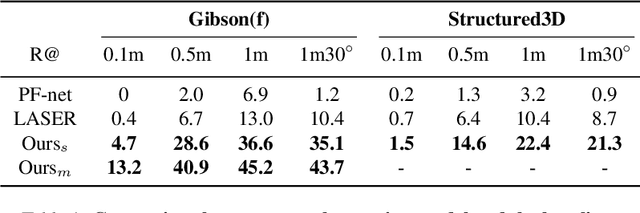
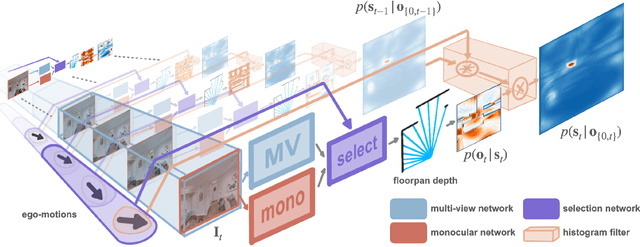
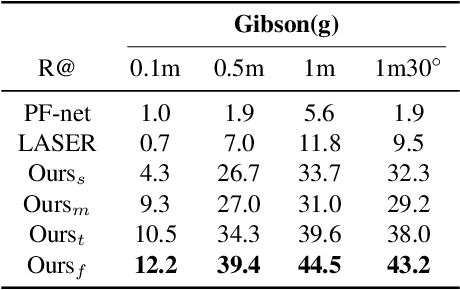
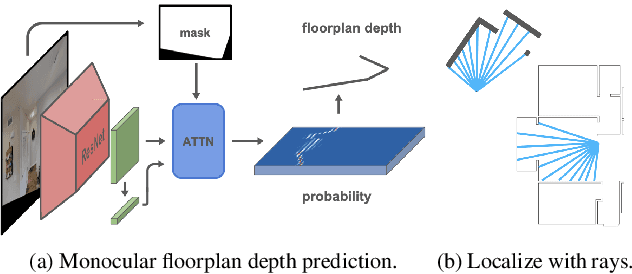
In this paper we propose an efficient data-driven solution to self-localization within a floorplan. Floorplan data is readily available, long-term persistent and inherently robust to changes in the visual appearance. Our method does not require retraining per map and location or demand a large database of images of the area of interest. We propose a novel probabilistic model consisting of an observation and a novel temporal filtering module. Operating internally with an efficient ray-based representation, the observation module consists of a single and a multiview module to predict horizontal depth from images and fuses their results to benefit from advantages offered by either methodology. Our method operates on conventional consumer hardware and overcomes a common limitation of competing methods that often demand upright images. Our full system meets real-time requirements, while outperforming the state-of-the-art by a significant margin.
IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo
Dec 09, 2021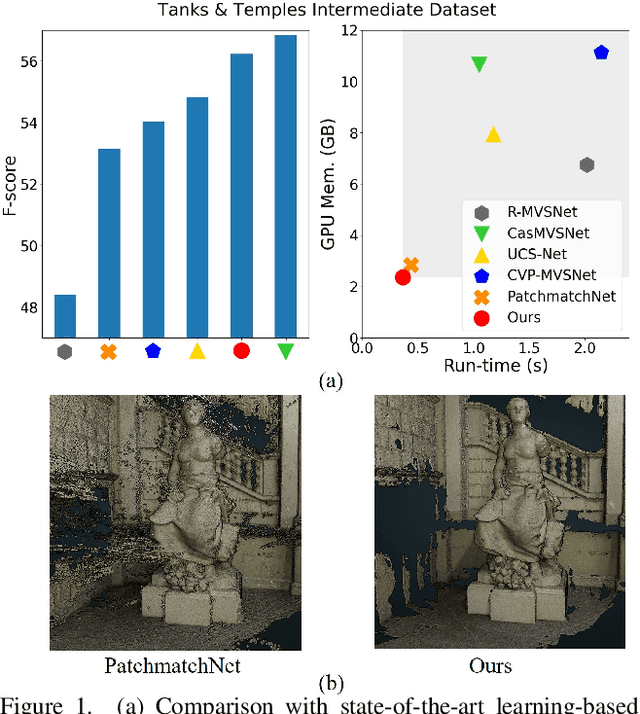
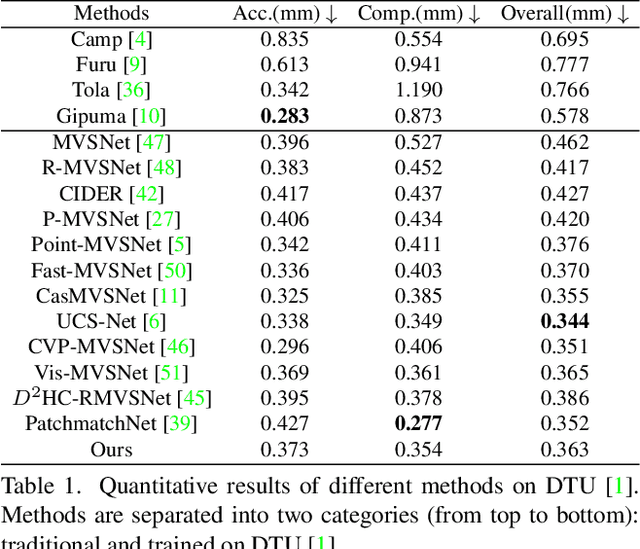
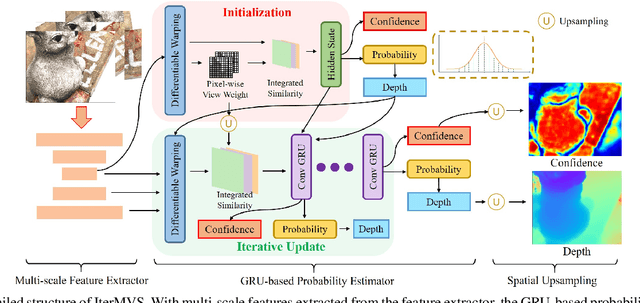
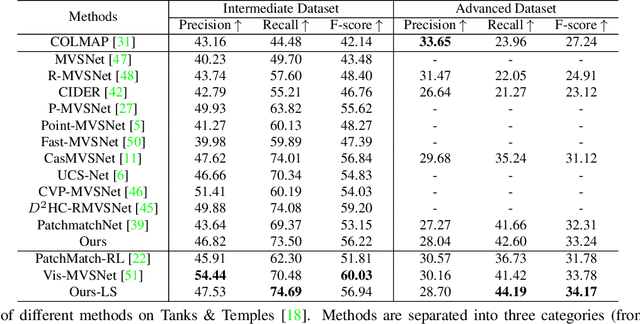
We present IterMVS, a new data-driven method for high-resolution multi-view stereo. We propose a novel GRU-based estimator that encodes pixel-wise probability distributions of depth in its hidden state. Ingesting multi-scale matching information, our model refines these distributions over multiple iterations and infers depth and confidence. To extract the depth maps, we combine traditional classification and regression in a novel manner. We verify the efficiency and effectiveness of our method on DTU, Tanks&Temples and ETH3D. While being the most efficient method in both memory and run-time, our model achieves competitive performance on DTU and better generalization ability on Tanks&Temples as well as ETH3D than most state-of-the-art methods. Code is available at https://github.com/FangjinhuaWang/IterMVS.
DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Dec 03, 2020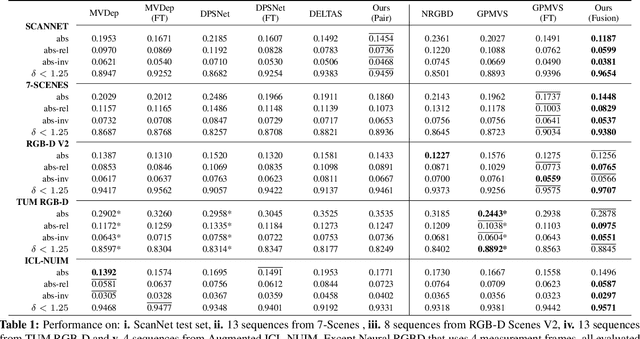
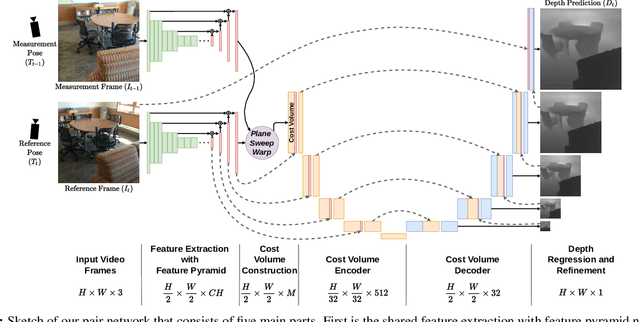
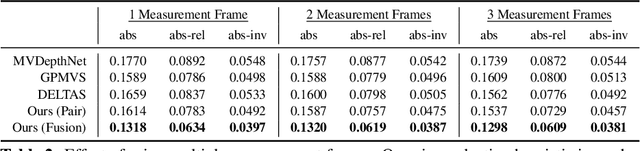
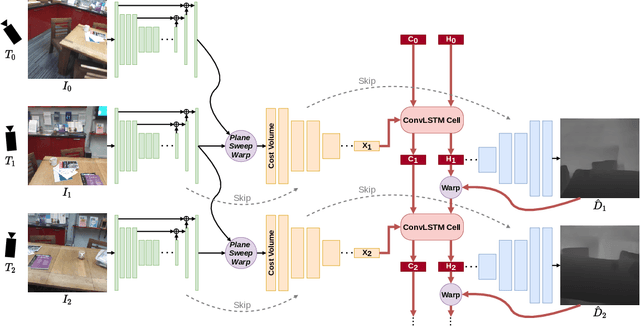
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: https://github.com/ardaduz/deep-video-mvs
PatchmatchNet: Learned Multi-View Patchmatch Stereo
Dec 02, 2020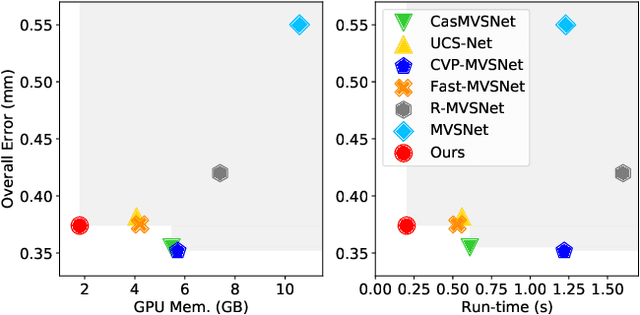
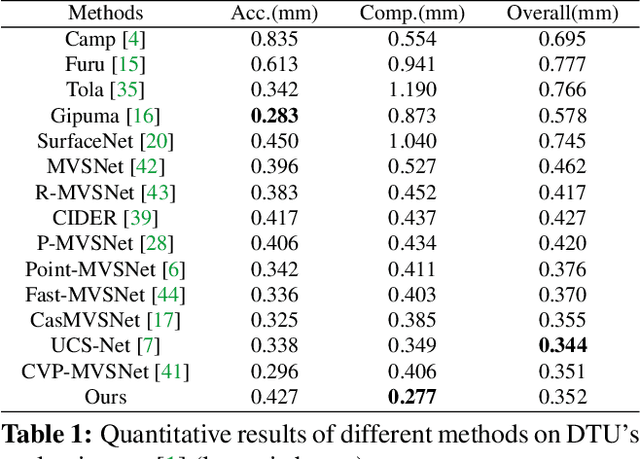
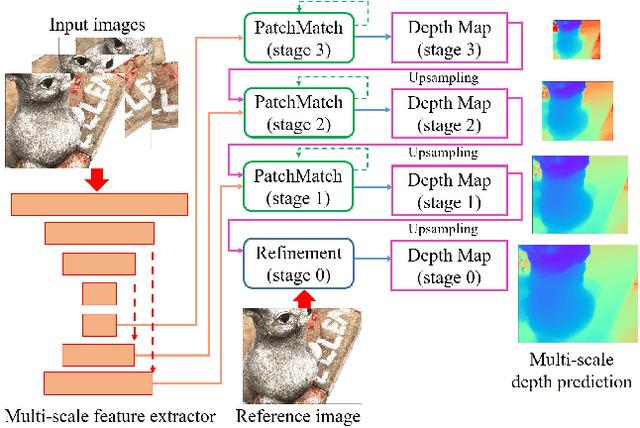
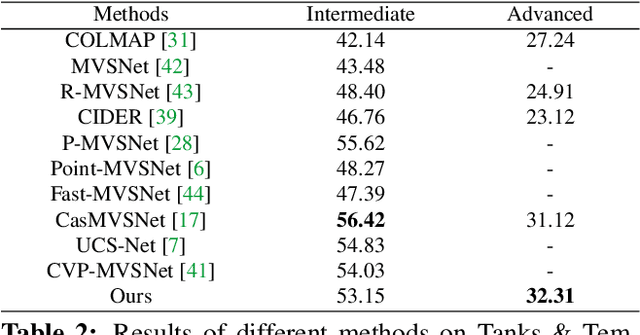
We present PatchmatchNet, a novel and learnable cascade formulation of Patchmatch for high-resolution multi-view stereo. With high computation speed and low memory requirement, PatchmatchNet can process higher resolution imagery and is more suited to run on resource limited devices than competitors that employ 3D cost volume regularization. For the first time we introduce an iterative multi-scale Patchmatch in an end-to-end trainable architecture and improve the Patchmatch core algorithm with a novel and learned adaptive propagation and evaluation scheme for each iteration. Extensive experiments show a very competitive performance and generalization for our method on DTU, Tanks & Temples and ETH3D, but at a significantly higher efficiency than all existing top-performing models: at least two and a half times faster than state-of-the-art methods with twice less memory usage.
Self-Supervised Learning for Stereo Reconstruction on Aerial Images
Jul 29, 2019
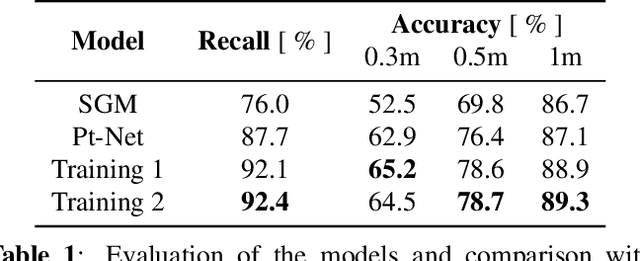
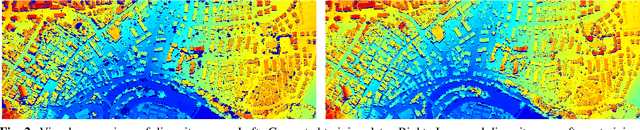
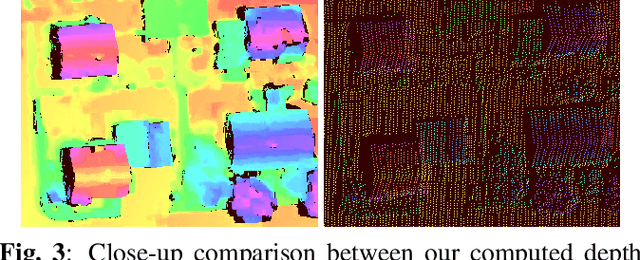
Recent developments established deep learning as an inevitable tool to boost the performance of dense matching and stereo estimation. On the downside, learning these networks requires a substantial amount of training data to be successful. Consequently, the application of these models outside of the laboratory is far from straight forward. In this work we propose a self-supervised training procedure that allows us to adapt our network to the specific (imaging) characteristics of the dataset at hand, without the requirement of external ground truth data. We instead generate interim training data by running our intermediate network on the whole dataset, followed by conservative outlier filtering. Bootstrapped from a pre-trained version of our hybrid CNN-CRF model, we alternate the generation of training data and network training. With this simple concept we are able to lift the completeness and accuracy of the pre-trained version significantly. We also show that our final model compares favorably to other popular stereo estimation algorithms on an aerial dataset.
Learning Energy Based Inpainting for Optical Flow
Nov 09, 2018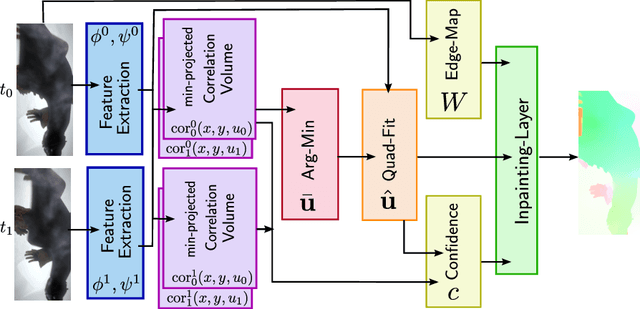
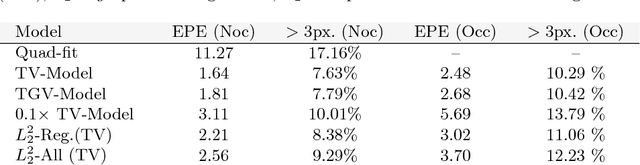


Modern optical flow methods are often composed of a cascade of many independent steps or formulated as a black box neural network that is hard to interpret and analyze. In this work we seek for a plain, interpretable, but learnable solution. We propose a novel inpainting based algorithm that approaches the problem in three steps: feature selection and matching, selection of supporting points and energy based inpainting. To facilitate the inference we propose an optimization layer that allows to backpropagate through 10K iterations of a first-order method without any numerical or memory problems. Compared to recent state-of-the-art networks, our modular CNN is very lightweight and competitive with other, more involved, inpainting based methods.
3D Fluid Flow Estimation with Integrated Particle Reconstruction
Apr 10, 2018


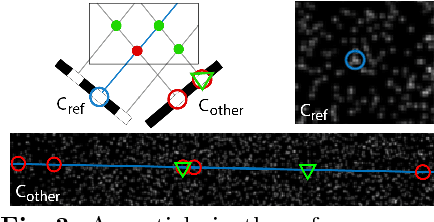
The standard approach to densely reconstruct the motion in a volume of fluid is to inject high-contrast tracer particles and record their motion with multiple high-speed cameras. Almost all existing work processes the acquired multi-view video in two separate steps: first, a per-frame reconstruction of the particles, usually in the form of soft occupancy likelihoods in a voxel representation; followed by 3D motion estimation, with some form of dense matching between the precomputed voxel grids from different time steps. In this sequential procedure, the first step cannot use temporal consistency considerations to support the reconstruction, while the second step has no access to the original, high-resolution image data. We show, for the first time, how to jointly reconstruct both the individual tracer particles and a dense 3D fluid motion field from the image data, using an integrated energy minimization. Our hybrid Lagrangian/Eulerian model explicitly reconstructs individual particles, and at the same time recovers a dense 3D motion field in the entire domain. Making particles explicit greatly reduces the memory consumption and allows one to use the high-resolution input images for matching. Whereas the dense motion field makes it possible to include physical a-priori constraints and account for the incompressibility and viscosity of the fluid. The method exhibits greatly (~70%) improved results over a recent baseline with two separate steps for 3D reconstruction and motion estimation. Our results with only two time steps are comparable to those of state-of-the-art tracking-based methods that require much longer sequences.