 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImLoc: Revisiting Visual Localization with Image-based Representation
Jan 07, 2026Existing visual localization methods are typically either 2D image-based, which are easy to build and maintain but limited in effective geometric reasoning, or 3D structure-based, which achieve high accuracy but require a centralized reconstruction and are difficult to update. In this work, we revisit visual localization with a 2D image-based representation and propose to augment each image with estimated depth maps to capture the geometric structure. Supported by the effective use of dense matchers, this representation is not only easy to build and maintain, but achieves highest accuracy in challenging conditions. With compact compression and a GPU-accelerated LO-RANSAC implementation, the whole pipeline is efficient in both storage and computation and allows for a flexible trade-off between accuracy and highest memory efficiency. Our method achieves a new state-of-the-art accuracy on various standard benchmarks and outperforms existing memory-efficient methods at comparable map sizes. Code will be available at https://github.com/cvg/Hierarchical-Localization.
From Indoor to Open World: Revealing the Spatial Reasoning Gap in MLLMs
Dec 22, 2025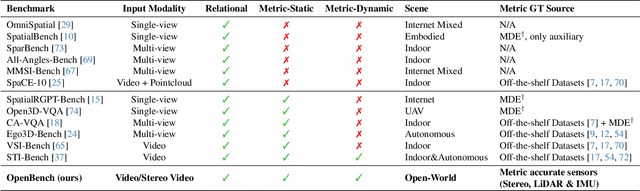

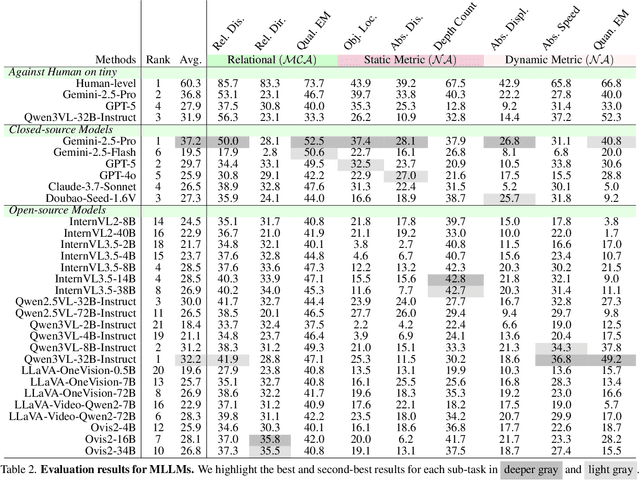
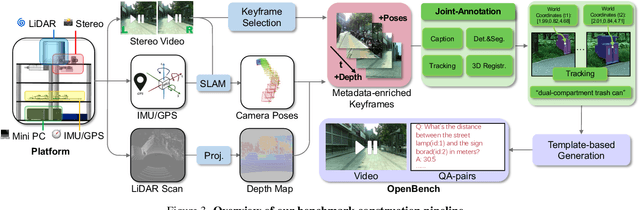
While Multimodal Large Language Models (MLLMs) have achieved impressive performance on semantic tasks, their spatial intelligence--crucial for robust and grounded AI systems--remains underdeveloped. Existing benchmarks fall short of diagnosing this limitation: they either focus on overly simplified qualitative reasoning or rely on domain-specific indoor data, constrained by the lack of outdoor datasets with verifiable metric ground truth. To bridge this gap, we introduce a large-scale benchmark built from pedestrian-perspective videos captured with synchronized stereo cameras, LiDAR, and IMU/GPS sensors. This dataset provides metrically precise 3D information, enabling the automatic generation of spatial reasoning questions that span a hierarchical spectrum--from qualitative relational reasoning to quantitative metric and kinematic understanding. Evaluations reveal that the performance gains observed in structured indoor benchmarks vanish in open-world settings. Further analysis using synthetic abnormal scenes and blinding tests confirms that current MLLMs depend heavily on linguistic priors instead of grounded visual reasoning. Our benchmark thus provides a principled platform for diagnosing these limitations and advancing physically grounded spatial intelligence.
Lightweight and Accurate Multi-View Stereo with Confidence-Aware Diffusion Model
Sep 18, 2025To reconstruct the 3D geometry from calibrated images, learning-based multi-view stereo (MVS) methods typically perform multi-view depth estimation and then fuse depth maps into a mesh or point cloud. To improve the computational efficiency, many methods initialize a coarse depth map and then gradually refine it in higher resolutions. Recently, diffusion models achieve great success in generation tasks. Starting from a random noise, diffusion models gradually recover the sample with an iterative denoising process. In this paper, we propose a novel MVS framework, which introduces diffusion models in MVS. Specifically, we formulate depth refinement as a conditional diffusion process. Considering the discriminative characteristic of depth estimation, we design a condition encoder to guide the diffusion process. To improve efficiency, we propose a novel diffusion network combining lightweight 2D U-Net and convolutional GRU. Moreover, we propose a novel confidence-based sampling strategy to adaptively sample depth hypotheses based on the confidence estimated by diffusion model. Based on our novel MVS framework, we propose two novel MVS methods, DiffMVS and CasDiffMVS. DiffMVS achieves competitive performance with state-of-the-art efficiency in run-time and GPU memory. CasDiffMVS achieves state-of-the-art performance on DTU, Tanks & Temples and ETH3D. Code is available at: https://github.com/cvg/diffmvs.
Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces
Mar 24, 2025



We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs. See our project page at https://openfungraph.github.io
R-SCoRe: Revisiting Scene Coordinate Regression for Robust Large-Scale Visual Localization
Jan 02, 2025



Learning-based visual localization methods that use scene coordinate regression (SCR) offer the advantage of smaller map sizes. However, on datasets with complex illumination changes or image-level ambiguities, it remains a less robust alternative to feature matching methods. This work aims to close the gap. We introduce a covisibility graph-based global encoding learning and data augmentation strategy, along with a depth-adjusted reprojection loss to facilitate implicit triangulation. Additionally, we revisit the network architecture and local feature extraction module. Our method achieves state-of-the-art on challenging large-scale datasets without relying on network ensembles or 3D supervision. On Aachen Day-Night, we are 10$\times$ more accurate than previous SCR methods with similar map sizes and require at least 5$\times$ smaller map sizes than any other SCR method while still delivering superior accuracy. Code will be available at: https://github.com/cvg/scrstudio .
DepthSplat: Connecting Gaussian Splatting and Depth
Oct 17, 2024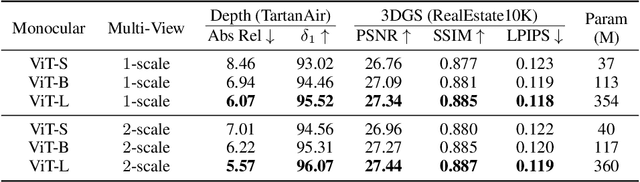
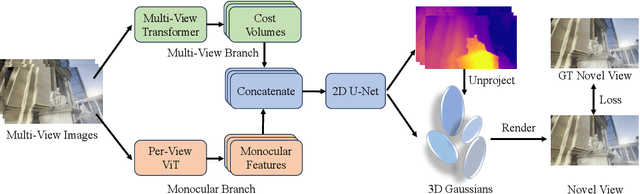
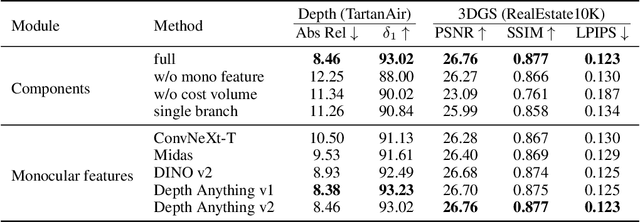

Gaussian splatting and single/multi-view depth estimation are typically studied in isolation. In this paper, we present DepthSplat to connect Gaussian splatting and depth estimation and study their interactions. More specifically, we first contribute a robust multi-view depth model by leveraging pre-trained monocular depth features, leading to high-quality feed-forward 3D Gaussian splatting reconstructions. We also show that Gaussian splatting can serve as an unsupervised pre-training objective for learning powerful depth models from large-scale unlabelled datasets. We validate the synergy between Gaussian splatting and depth estimation through extensive ablation and cross-task transfer experiments. Our DepthSplat achieves state-of-the-art performance on ScanNet, RealEstate10K and DL3DV datasets in terms of both depth estimation and novel view synthesis, demonstrating the mutual benefits of connecting both tasks. Our code, models, and video results are available at https://haofeixu.github.io/depthsplat/.
Learning-based Multi-View Stereo: A Survey
Aug 27, 2024



3D reconstruction aims to recover the dense 3D structure of a scene. It plays an essential role in various applications such as Augmented/Virtual Reality (AR/VR), autonomous driving and robotics. Leveraging multiple views of a scene captured from different viewpoints, Multi-View Stereo (MVS) algorithms synthesize a comprehensive 3D representation, enabling precise reconstruction in complex environments. Due to its efficiency and effectiveness, MVS has become a pivotal method for image-based 3D reconstruction. Recently, with the success of deep learning, many learning-based MVS methods have been proposed, achieving impressive performance against traditional methods. We categorize these learning-based methods as: depth map-based, voxel-based, NeRF-based, 3D Gaussian Splatting-based, and large feed-forward methods. Among these, we focus significantly on depth map-based methods, which are the main family of MVS due to their conciseness, flexibility and scalability. In this survey, we provide a comprehensive review of the literature at the time of this writing. We investigate these learning-based methods, summarize their performances on popular benchmarks, and discuss promising future research directions in this area.
GLACE: Global Local Accelerated Coordinate Encoding
Jun 06, 2024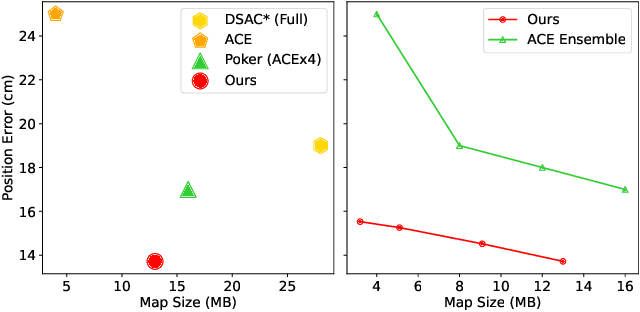
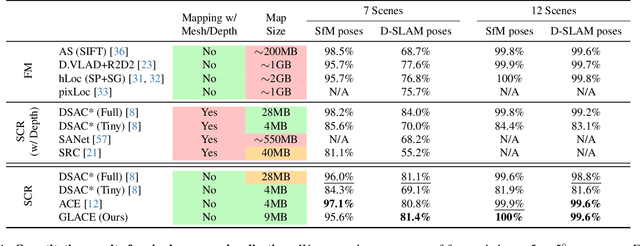
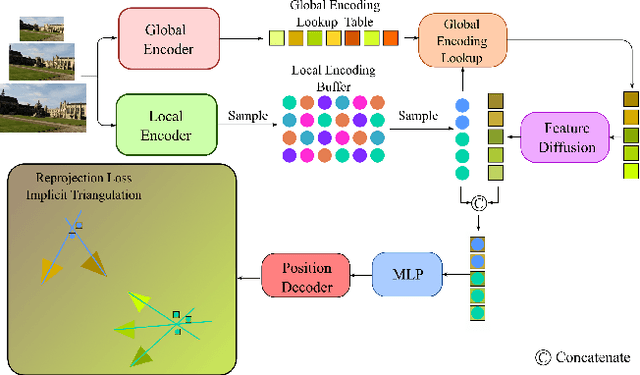
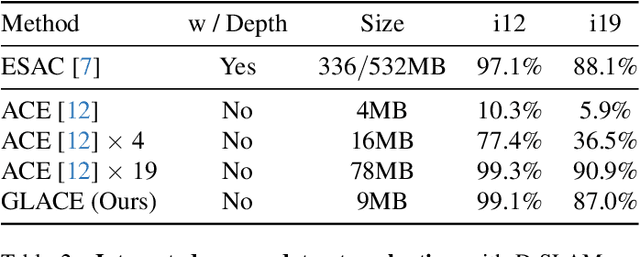
Scene coordinate regression (SCR) methods are a family of visual localization methods that directly regress 2D-3D matches for camera pose estimation. They are effective in small-scale scenes but face significant challenges in large-scale scenes that are further amplified in the absence of ground truth 3D point clouds for supervision. Here, the model can only rely on reprojection constraints and needs to implicitly triangulate the points. The challenges stem from a fundamental dilemma: The network has to be invariant to observations of the same landmark at different viewpoints and lighting conditions, etc., but at the same time discriminate unrelated but similar observations. The latter becomes more relevant and severe in larger scenes. In this work, we tackle this problem by introducing the concept of co-visibility to the network. We propose GLACE, which integrates pre-trained global and local encodings and enables SCR to scale to large scenes with only a single small-sized network. Specifically, we propose a novel feature diffusion technique that implicitly groups the reprojection constraints with co-visibility and avoids overfitting to trivial solutions. Additionally, our position decoder parameterizes the output positions for large-scale scenes more effectively. Without using 3D models or depth maps for supervision, our method achieves state-of-the-art results on large-scale scenes with a low-map-size model. On Cambridge landmarks, with a single model, we achieve 17% lower median position error than Poker, the ensemble variant of the state-of-the-art SCR method ACE. Code is available at: https://github.com/cvg/glace.
UniSDF: Unifying Neural Representations for High-Fidelity 3D Reconstruction of Complex Scenes with Reflections
Dec 20, 2023Neural 3D scene representations have shown great potential for 3D reconstruction from 2D images. However, reconstructing real-world captures of complex scenes still remains a challenge. Existing generic 3D reconstruction methods often struggle to represent fine geometric details and do not adequately model reflective surfaces of large-scale scenes. Techniques that explicitly focus on reflective surfaces can model complex and detailed reflections by exploiting better reflection parameterizations. However, we observe that these methods are often not robust in real unbounded scenarios where non-reflective as well as reflective components are present. In this work, we propose UniSDF, a general purpose 3D reconstruction method that can reconstruct large complex scenes with reflections. We investigate both view-based as well as reflection-based color prediction parameterization techniques and find that explicitly blending these representations in 3D space enables reconstruction of surfaces that are more geometrically accurate, especially for reflective surfaces. We further combine this representation with a multi-resolution grid backbone that is trained in a coarse-to-fine manner, enabling faster reconstructions than prior methods. Extensive experiments on object-level datasets DTU, Shiny Blender as well as unbounded datasets Mip-NeRF 360 and Ref-NeRF real demonstrate that our method is able to robustly reconstruct complex large-scale scenes with fine details and reflective surfaces. Please see our project page at https://fangjinhuawang.github.io/UniSDF.
VolRecon: Volume Rendering of Signed Ray Distance Functions for Generalizable Multi-View Reconstruction
Dec 15, 2022


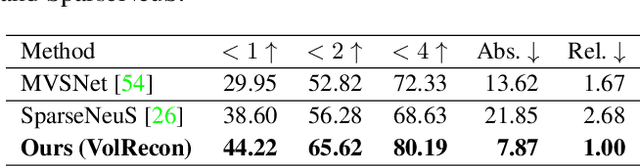
With the success of neural volume rendering in novel view synthesis, neural implicit reconstruction with volume rendering has become popular. However, most methods optimize per-scene functions and are unable to generalize to novel scenes. We introduce VolRecon, a generalizable implicit reconstruction method with Signed Ray Distance Function (SRDF). To reconstruct with fine details and little noise, we combine projection features, aggregated from multi-view features with a view transformer, and volume features interpolated from a coarse global feature volume. A ray transformer computes SRDF values of all the samples along a ray to estimate the surface location, which are used for volume rendering of color and depth. Extensive experiments on DTU and ETH3D demonstrate the effectiveness and generalization ability of our method. On DTU, our method outperforms SparseNeuS by about 30% in sparse view reconstruction and achieves comparable quality as MVSNet in full view reconstruction. Besides, our method shows good generalization ability on the large-scale ETH3D benchmark. Project page: https://fangjinhuawang.github.io/VolRecon.