 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming into Comics: Region-Aware RL Improves Fine-Grained Comic Understanding in Vision-Language Models
Nov 09, 2025Complex visual narratives, such as comics, present a significant challenge to Vision-Language Models (VLMs). Despite excelling on natural images, VLMs often struggle with stylized line art, onomatopoeia, and densely packed multi-panel layouts. To address this gap, we introduce AI4VA-FG, the first fine-grained and comprehensive benchmark for VLM-based comic understanding. It spans tasks from foundational recognition and detection to high-level character reasoning and narrative construction, supported by dense annotations for characters, poses, and depth. Beyond that, we evaluate state-of-the-art proprietary models, including GPT-4o and Gemini-2.5, and open-source models such as Qwen2.5-VL, revealing substantial performance deficits across core tasks of our benchmarks and underscoring that comic understanding remains an unsolved challenge. To enhance VLMs' capabilities in this domain, we systematically investigate post-training strategies, including supervised fine-tuning on solutions (SFT-S), supervised fine-tuning on reasoning trajectories (SFT-R), and reinforcement learning (RL). Beyond that, inspired by the emerging "Thinking with Images" paradigm, we propose Region-Aware Reinforcement Learning (RARL) for VLMs, which trains models to dynamically attend to relevant regions through zoom-in operations. We observe that when applied to the Qwen2.5-VL model, RL and RARL yield significant gains in low-level entity recognition and high-level storyline ordering, paving the way for more accurate and efficient VLM applications in the comics domain.
Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models
Apr 02, 2025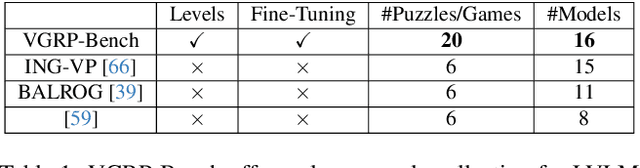
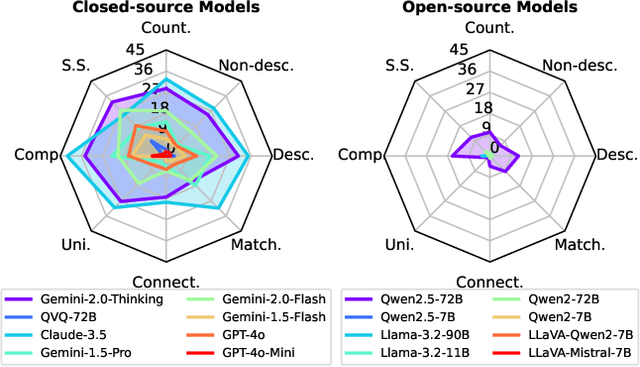
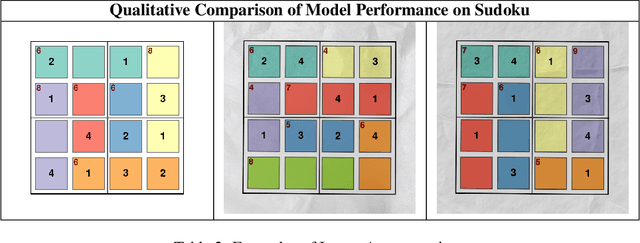
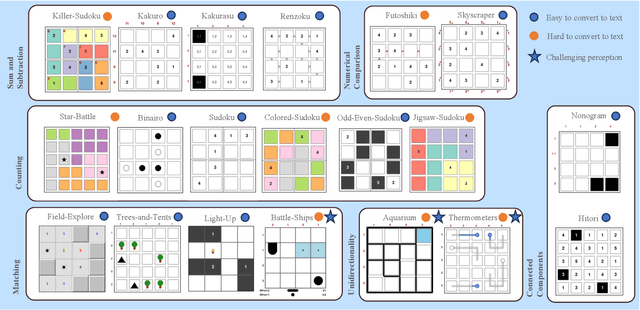
Large Vision-Language Models (LVLMs) struggle with puzzles, which require precise perception, rule comprehension, and logical reasoning. Assessing and enhancing their performance in this domain is crucial, as it reflects their ability to engage in structured reasoning - an essential skill for real-world problem-solving. However, existing benchmarks primarily evaluate pre-trained models without additional training or fine-tuning, often lack a dedicated focus on reasoning, and fail to establish a systematic evaluation framework. To address these limitations, we introduce VGRP-Bench, a Visual Grid Reasoning Puzzle Benchmark featuring 20 diverse puzzles. VGRP-Bench spans multiple difficulty levels, and includes extensive experiments not only on existing chat LVLMs (e.g., GPT-4o), but also on reasoning LVLMs (e.g., Gemini-Thinking). Our results reveal that even the state-of-the-art LVLMs struggle with these puzzles, highlighting fundamental limitations in their puzzle-solving capabilities. Most importantly, through systematic experiments, we identify and analyze key factors influencing LVLMs' puzzle-solving performance, including the number of clues, grid size, and rule complexity. Furthermore, we explore two Supervised Fine-Tuning (SFT) strategies that can be used in post-training: SFT on solutions (S-SFT) and SFT on synthetic reasoning processes (R-SFT). While both methods significantly improve performance on trained puzzles, they exhibit limited generalization to unseen ones. We will release VGRP-Bench to facilitate further research on LVLMs for complex, real-world problem-solving. Project page: https://yufan-ren.com/subpage/VGRP-Bench/.
FDS: Frequency-Aware Denoising Score for Text-Guided Latent Diffusion Image Editing
Mar 24, 2025



Text-guided image editing using Text-to-Image (T2I) models often fails to yield satisfactory results, frequently introducing unintended modifications, such as the loss of local detail and color changes. In this paper, we analyze these failure cases and attribute them to the indiscriminate optimization across all frequency bands, even though only specific frequencies may require adjustment. To address this, we introduce a simple yet effective approach that enables the selective optimization of specific frequency bands within localized spatial regions for precise edits. Our method leverages wavelets to decompose images into different spatial resolutions across multiple frequency bands, enabling precise modifications at various levels of detail. To extend the applicability of our approach, we provide a comparative analysis of different frequency-domain techniques. Additionally, we extend our method to 3D texture editing by performing frequency decomposition on the triplane representation, enabling frequency-aware adjustments for 3D textures. Quantitative evaluations and user studies demonstrate the effectiveness of our method in producing high-quality and precise edits.
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023



Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.
Efficient Temporally-Aware DeepFake Detection using H.264 Motion Vectors
Nov 17, 2023Video DeepFakes are fake media created with Deep Learning (DL) that manipulate a person's expression or identity. Most current DeepFake detection methods analyze each frame independently, ignoring inconsistencies and unnatural movements between frames. Some newer methods employ optical flow models to capture this temporal aspect, but they are computationally expensive. In contrast, we propose using the related but often ignored Motion Vectors (MVs) and Information Masks (IMs) from the H.264 video codec, to detect temporal inconsistencies in DeepFakes. Our experiments show that this approach is effective and has minimal computational costs, compared with per-frame RGB-only methods. This could lead to new, real-time temporally-aware DeepFake detection methods for video calls and streaming.
VolRecon: Volume Rendering of Signed Ray Distance Functions for Generalizable Multi-View Reconstruction
Dec 15, 2022


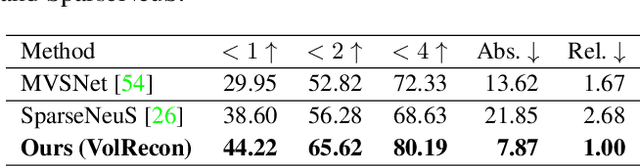
With the success of neural volume rendering in novel view synthesis, neural implicit reconstruction with volume rendering has become popular. However, most methods optimize per-scene functions and are unable to generalize to novel scenes. We introduce VolRecon, a generalizable implicit reconstruction method with Signed Ray Distance Function (SRDF). To reconstruct with fine details and little noise, we combine projection features, aggregated from multi-view features with a view transformer, and volume features interpolated from a coarse global feature volume. A ray transformer computes SRDF values of all the samples along a ray to estimate the surface location, which are used for volume rendering of color and depth. Extensive experiments on DTU and ETH3D demonstrate the effectiveness and generalization ability of our method. On DTU, our method outperforms SparseNeuS by about 30% in sparse view reconstruction and achieves comparable quality as MVSNet in full view reconstruction. Besides, our method shows good generalization ability on the large-scale ETH3D benchmark. Project page: https://fangjinhuawang.github.io/VolRecon.
BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks
Nov 22, 2019


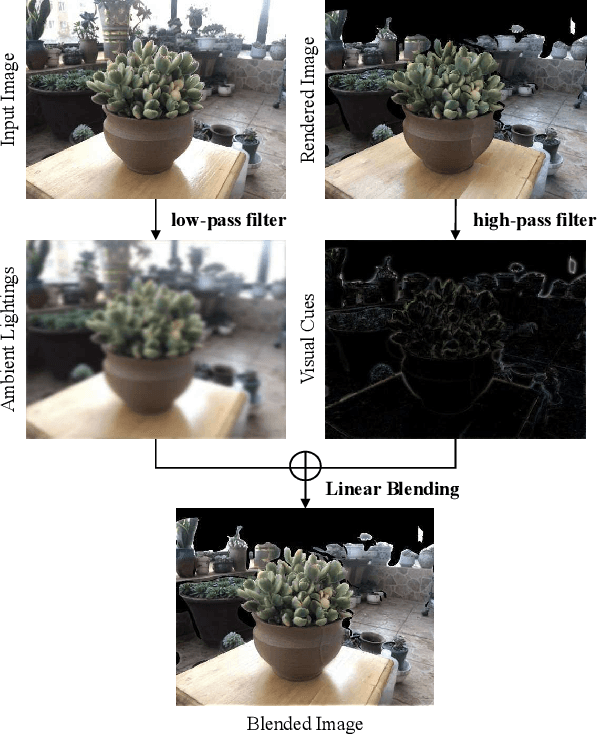
While deep learning has recently achieved great success on multi-view stereo (MVS), limited training data makes the trained model hard to be generalized to unseen scenarios. Compared with other computer vision tasks, it is rather difficult to collect a large-scale MVS dataset as it requires expensive active scanners and labor-intensive process to obtain ground truth 3D structures. In this paper, we introduce BlendedMVS, a novel large-scale dataset, to provide sufficient training ground truth for learning-based MVS. To create the dataset, we apply a 3D reconstruction pipeline to recover high-quality textured meshes from images of well-selected scenes. Then, we render these mesh models to color images and depth maps. The rendered color images are further blended with the input images to generate photo-realistic blended images as the training input. Our dataset contains over 17k high-resolution images covering a variety of scenes, including cities, architectures, sculptures and small objects. Extensive experiments demonstrate that BlendedMVS endows the trained model with significantly better generalization ability compared with other MVS datasets. The entire dataset with pretrained models will be made publicly available at https://github.com/YoYo000/BlendedMVS.