 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRI: Mixing Features of Reference Images for Novel Object Pose Estimation
Jan 11, 2026We present MixRI, a lightweight network that solves the CAD-based novel object pose estimation problem in RGB images. It can be instantly applied to a novel object at test time without finetuning. We design our network to meet the demands of real-world applications, emphasizing reduced memory requirements and fast inference time. Unlike existing works that utilize many reference images and have large network parameters, we directly match points based on the multi-view information between the query and reference images with a lightweight network. Thanks to our reference image fusion strategy, we significantly decrease the number of reference images, thus decreasing the time needed to process these images and the memory required to store them. Furthermore, with our lightweight network, our method requires less inference time. Though with fewer reference images, experiments on seven core datasets in the BOP challenge show that our method achieves comparable results with other methods that require more reference images and larger network parameters.
* Accepted by ICCV 2025
OpenMaterial: A Comprehensive Dataset of Complex Materials for 3D Reconstruction
Jun 13, 2024Recent advances in deep learning such as neural radiance fields and implicit neural representations have significantly propelled the field of 3D reconstruction. However, accurately reconstructing objects with complex optical properties, such as metals and glass, remains a formidable challenge due to their unique specular and light-transmission characteristics. To facilitate the development of solutions to these challenges, we introduce the OpenMaterial dataset, comprising 1001 objects made of 295 distinct materials-including conductors, dielectrics, plastics, and their roughened variants- and captured under 723 diverse lighting conditions. To this end, we utilized physics-based rendering with laboratory-measured Indices of Refraction (IOR) and generated high-fidelity multiview images that closely replicate real-world objects. OpenMaterial provides comprehensive annotations, including 3D shape, material type, camera pose, depth, and object mask. It stands as the first large-scale dataset enabling quantitative evaluations of existing algorithms on objects with diverse and challenging materials, thereby paving the way for the development of 3D reconstruction algorithms capable of handling complex material properties.
DVMNet: Computing Relative Pose for Unseen Objects Beyond Hypotheses
Mar 20, 2024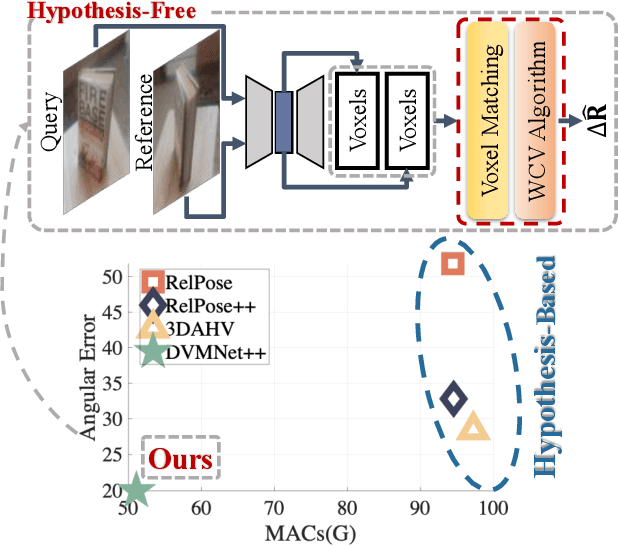



Determining the relative pose of an object between two images is pivotal to the success of generalizable object pose estimation. Existing approaches typically approximate the continuous pose representation with a large number of discrete pose hypotheses, which incurs a computationally expensive process of scoring each hypothesis at test time. By contrast, we present a Deep Voxel Matching Network (DVMNet) that eliminates the need for pose hypotheses and computes the relative object pose in a single pass. To this end, we map the two input RGB images, reference and query, to their respective voxelized 3D representations. We then pass the resulting voxels through a pose estimation module, where the voxels are aligned and the pose is computed in an end-to-end fashion by solving a least-squares problem. To enhance robustness, we introduce a weighted closest voxel algorithm capable of mitigating the impact of noisy voxels. We conduct extensive experiments on the CO3D, LINEMOD, and Objaverse datasets, demonstrating that our method delivers more accurate relative pose estimates for novel objects at a lower computational cost compared to state-of-the-art methods. Our code is released at: https://github.com/sailor-z/DVMNet/.
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023



Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.
SE(3) Diffusion Model-based Point Cloud Registration for Robust 6D Object Pose Estimation
Oct 26, 2023In this paper, we introduce an SE(3) diffusion model-based point cloud registration framework for 6D object pose estimation in real-world scenarios. Our approach formulates the 3D registration task as a denoising diffusion process, which progressively refines the pose of the source point cloud to obtain a precise alignment with the model point cloud. Training our framework involves two operations: An SE(3) diffusion process and an SE(3) reverse process. The SE(3) diffusion process gradually perturbs the optimal rigid transformation of a pair of point clouds by continuously injecting noise (perturbation transformation). By contrast, the SE(3) reverse process focuses on learning a denoising network that refines the noisy transformation step-by-step, bringing it closer to the optimal transformation for accurate pose estimation. Unlike standard diffusion models used in linear Euclidean spaces, our diffusion model operates on the SE(3) manifold. This requires exploiting the linear Lie algebra $\mathfrak{se}(3)$ associated with SE(3) to constrain the transformation transitions during the diffusion and reverse processes. Additionally, to effectively train our denoising network, we derive a registration-specific variational lower bound as the optimization objective for model learning. Furthermore, we show that our denoising network can be constructed with a surrogate registration model, making our approach applicable to different deep registration networks. Extensive experiments demonstrate that our diffusion registration framework presents outstanding pose estimation performance on the real-world TUD-L, LINEMOD, and Occluded-LINEMOD datasets.
AutoSynth: Learning to Generate 3D Training Data for Object Point Cloud Registration
Sep 20, 2023In the current deep learning paradigm, the amount and quality of training data are as critical as the network architecture and its training details. However, collecting, processing, and annotating real data at scale is difficult, expensive, and time-consuming, particularly for tasks such as 3D object registration. While synthetic datasets can be created, they require expertise to design and include a limited number of categories. In this paper, we introduce a new approach called AutoSynth, which automatically generates 3D training data for point cloud registration. Specifically, AutoSynth automatically curates an optimal dataset by exploring a search space encompassing millions of potential datasets with diverse 3D shapes at a low cost.To achieve this, we generate synthetic 3D datasets by assembling shape primitives, and develop a meta-learning strategy to search for the best training data for 3D registration on real point clouds. For this search to remain tractable, we replace the point cloud registration network with a much smaller surrogate network, leading to a $4056.43$ times speedup. We demonstrate the generality of our approach by implementing it with two different point cloud registration networks, BPNet and IDAM. Our results on TUD-L, LINEMOD and Occluded-LINEMOD evidence that a neural network trained on our searched dataset yields consistently better performance than the same one trained on the widely used ModelNet40 dataset.
Robust Outlier Rejection for 3D Registration with Variational Bayes
Apr 04, 2023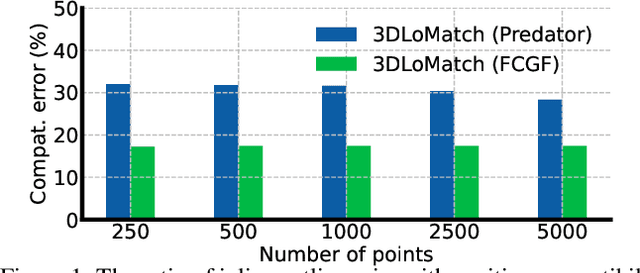
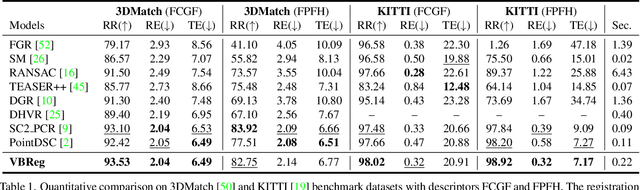
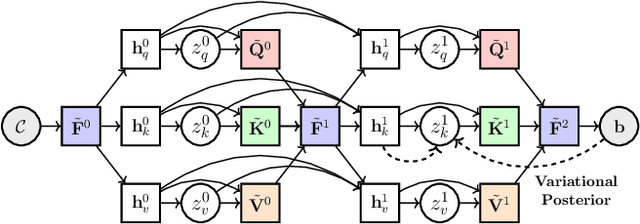
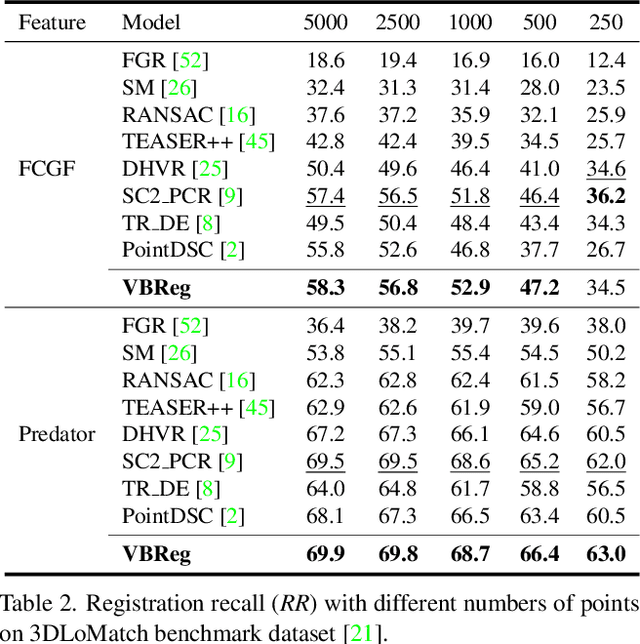
Learning-based outlier (mismatched correspondence) rejection for robust 3D registration generally formulates the outlier removal as an inlier/outlier classification problem. The core for this to be successful is to learn the discriminative inlier/outlier feature representations. In this paper, we develop a novel variational non-local network-based outlier rejection framework for robust alignment. By reformulating the non-local feature learning with variational Bayesian inference, the Bayesian-driven long-range dependencies can be modeled to aggregate discriminative geometric context information for inlier/outlier distinction. Specifically, to achieve such Bayesian-driven contextual dependencies, each query/key/value component in our non-local network predicts a prior feature distribution and a posterior one. Embedded with the inlier/outlier label, the posterior feature distribution is label-dependent and discriminative. Thus, pushing the prior to be close to the discriminative posterior in the training step enables the features sampled from this prior at test time to model high-quality long-range dependencies. Notably, to achieve effective posterior feature guidance, a specific probabilistic graphical model is designed over our non-local model, which lets us derive a variational low bound as our optimization objective for model training. Finally, we propose a voting-based inlier searching strategy to cluster the high-quality hypothetical inliers for transformation estimation. Extensive experiments on 3DMatch, 3DLoMatch, and KITTI datasets verify the effectiveness of our method.
Learning-based Point Cloud Registration for 6D Object Pose Estimation in the Real World
Mar 29, 2022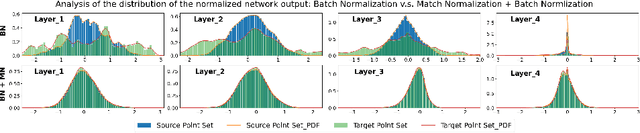
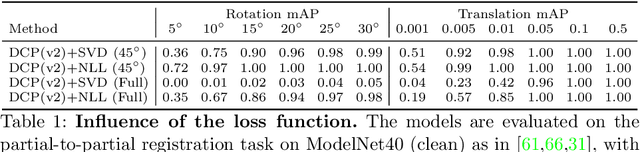
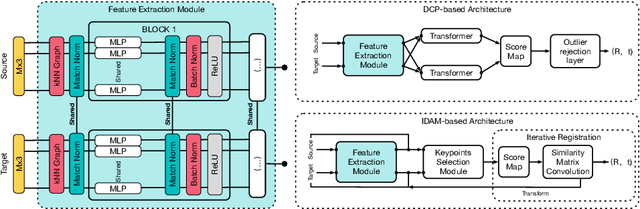
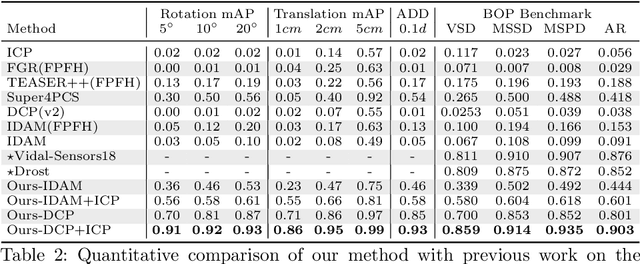
In this work, we tackle the task of estimating the 6D pose of an object from point cloud data. While recent learning-based approaches to addressing this task have shown great success on synthetic datasets, we have observed them to fail in the presence of real-world data. We thus analyze the causes of these failures, which we trace back to the difference between the feature distributions of the source and target point clouds, and the sensitivity of the widely-used SVD-based loss function to the range of rotation between the two point clouds. We address the first challenge by introducing a new normalization strategy, Match Normalization, and the second via the use of a loss function based on the negative log likelihood of point correspondences. Our two contributions are general and can be applied to many existing learning-based 3D object registration frameworks, which we illustrate by implementing them in two of them, DCP and IDAM. Our experiments on the real-scene TUD-L, LINEMOD and Occluded-LINEMOD datasets evidence the benefits of our strategies. They allow for the first time learning-based 3D object registration methods to achieve meaningful results on real-world data. We therefore expect them to be key to the future development of point cloud registration methods.
What Stops Learning-based 3D Registration from Working in the Real World?
Nov 19, 2021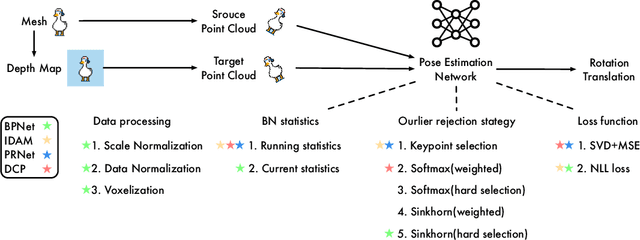



Much progress has been made on the task of learning-based 3D point cloud registration, with existing methods yielding outstanding results on standard benchmarks, such as ModelNet40, even in the partial-to-partial matching scenario. Unfortunately, these methods still struggle in the presence of real data. In this work, we identify the sources of these failures, analyze the reasons behind them, and propose solutions to tackle them. We summarise our findings into a set of guidelines and demonstrate their effectiveness by applying them to different baseline methods, DCP and IDAM. In short, our guidelines improve both their training convergence and testing accuracy. Ultimately, this translates to a best-practice 3D registration network (BPNet), constituting the first learning-based method able to handle previously-unseen objects in real-world data. Despite being trained only on synthetic data, our model generalizes to real data without any fine-tuning, reaching an accuracy of up to 67% on point clouds of unseen objects obtained with a commercial sensor.
Robust Differentiable SVD
Apr 08, 2021



Eigendecomposition of symmetric matrices is at the heart of many computer vision algorithms. However, the derivatives of the eigenvectors tend to be numerically unstable, whether using the SVD to compute them analytically or using the Power Iteration (PI) method to approximate them. This instability arises in the presence of eigenvalues that are close to each other. This makes integrating eigendecomposition into deep networks difficult and often results in poor convergence, particularly when dealing with large matrices. While this can be mitigated by partitioning the data into small arbitrary groups, doing so has no theoretical basis and makes it impossible to exploit the full power of eigendecomposition. In previous work, we mitigated this using SVD during the forward pass and PI to compute the gradients during the backward pass. However, the iterative deflation procedure required to compute multiple eigenvectors using PI tends to accumulate errors and yield inaccurate gradients. Here, we show that the Taylor expansion of the SVD gradient is theoretically equivalent to the gradient obtained using PI without relying in practice on an iterative process and thus yields more accurate gradients. We demonstrate the benefits of this increased accuracy for image classification and style transfer.
* IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) PREPRINT 2021