 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-360: Geometry-Consistent Zero-Shot Panoramic Depth Estimation
Mar 19, 2026This paper presents VGGT-360, a novel training-free framework for zero-shot, geometry-consistent panoramic depth estimation. Unlike prior view-independent training-free approaches, VGGT-360 reformulates the task as panoramic reprojection over multi-view reconstructed 3D models by leveraging the intrinsic 3D consistency of VGGT-like foundation models, thereby unifying fragmented per-view reasoning into a coherent panoramic understanding. To achieve robust and accurate estimation, VGGT-360 integrates three plug-and-play modules that form a unified panorama-to-3D-to-depth framework: (i) Uncertainty-guided adaptive projection slices panoramas into perspective views to bridge the domain gap between panoramic inputs and VGGT's perspective prior. It estimates gradient-based uncertainty to allocate denser views to geometry-poor regions, yielding geometry-informative inputs for VGGT. (ii) Structure-saliency enhanced attention strengthens VGGT's robustness during 3D reconstruction by injecting structure-aware confidence into its attention layers, guiding focus toward geometrically reliable regions and enhancing cross-view coherence. (iii) Correlation-weighted 3D model correction refines the reconstructed 3D model by reweighting overlapping points using attention-inferred correlation scores, providing a consistent geometric basis for accurate panoramic reprojection. Extensive experiments show that VGGT-360 outperforms both trained and training-free state-of-the-art methods across multiple resolutions and diverse indoor and outdoor datasets.
Generative Point Cloud Registration
Dec 10, 2025In this paper, we propose a novel 3D registration paradigm, Generative Point Cloud Registration, which bridges advanced 2D generative models with 3D matching tasks to enhance registration performance. Our key idea is to generate cross-view consistent image pairs that are well-aligned with the source and target point clouds, enabling geometry-color feature fusion to facilitate robust matching. To ensure high-quality matching, the generated image pair should feature both 2D-3D geometric consistency and cross-view texture consistency. To achieve this, we introduce Match-ControlNet, a matching-specific, controllable 2D generative model. Specifically, it leverages the depth-conditioned generation capability of ControlNet to produce images that are geometrically aligned with depth maps derived from point clouds, ensuring 2D-3D geometric consistency. Additionally, by incorporating a coupled conditional denoising scheme and coupled prompt guidance, Match-ControlNet further promotes cross-view feature interaction, guiding texture consistency generation. Our generative 3D registration paradigm is general and could be seamlessly integrated into various registration methods to enhance their performance. Extensive experiments on 3DMatch and ScanNet datasets verify the effectiveness of our approach.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
Mask6D: Masked Pose Priors For 6D Object Pose Estimation
Jul 09, 2025Robust 6D object pose estimation in cluttered or occluded conditions using monocular RGB images remains a challenging task. One reason is that current pose estimation networks struggle to extract discriminative, pose-aware features using 2D feature backbones, especially when the available RGB information is limited due to target occlusion in cluttered scenes. To mitigate this, we propose a novel pose estimation-specific pre-training strategy named Mask6D. Our approach incorporates pose-aware 2D-3D correspondence maps and visible mask maps as additional modal information, which is combined with RGB images for the reconstruction-based model pre-training. Essentially, this 2D-3D correspondence maps a transformed 3D object model to 2D pixels, reflecting the pose information of the target in camera coordinate system. Meanwhile, the integrated visible mask map can effectively guide our model to disregard cluttered background information. In addition, an object-focused pre-training loss function is designed to further facilitate our network to remove the background interference. Finally, we fine-tune our pre-trained pose prior-aware network via conventional pose training strategy to realize the reliable pose prediction. Extensive experiments verify that our method outperforms previous end-to-end pose estimation methods.
Diff-Reg v2: Diffusion-Based Matching Matrix Estimation for Image Matching and 3D Registration
Mar 07, 2025



Establishing reliable correspondences is crucial for all registration tasks, including 2D image registration, 3D point cloud registration, and 2D-3D image-to-point cloud registration. However, these tasks are often complicated by challenges such as scale inconsistencies, symmetry, and large deformations, which can lead to ambiguous matches. Previous feature-based and correspondence-based methods typically rely on geometric or semantic features to generate or polish initial potential correspondences. Some methods typically leverage specific geometric priors, such as topological preservation, to devise diverse and innovative strategies tailored to a given enhancement goal, which cannot be exhaustively enumerated. Additionally, many previous approaches rely on a single-step prediction head, which can struggle with local minima in complex matching scenarios. To address these challenges, we introduce an innovative paradigm that leverages a diffusion model in matrix space for robust matching matrix estimation. Our model treats correspondence estimation as a denoising diffusion process in the matching matrix space, gradually refining the intermediate matching matrix to the optimal one. Specifically, we apply the diffusion model in the doubly stochastic matrix space for 3D-3D and 2D-3D registration tasks. In the 2D image registration task, we deploy the diffusion model in a matrix subspace where dual-softmax projection regularization is applied. For all three registration tasks, we provide adaptive matching matrix embedding implementations tailored to the specific characteristics of each task while maintaining a consistent "match-to-warp" encoding pattern. Furthermore, we adopt a lightweight design for the denoising module. In inference, once points or image features are extracted and fixed, this module performs multi-step denoising predictions through reverse sampling.
Diff-Reg v1: Diffusion Matching Model for Registration Problem
Mar 29, 2024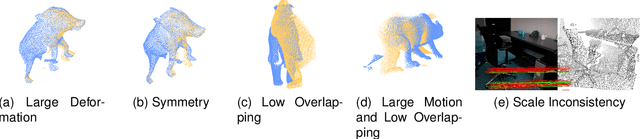
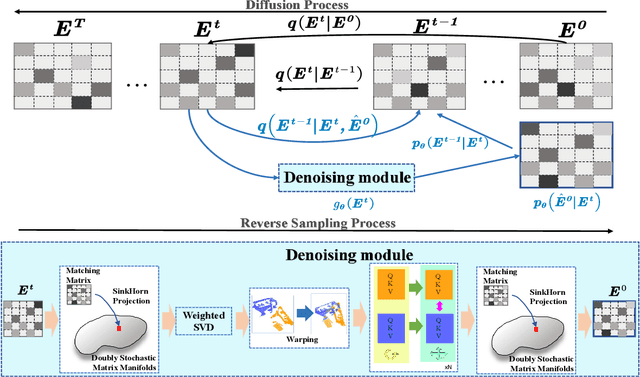
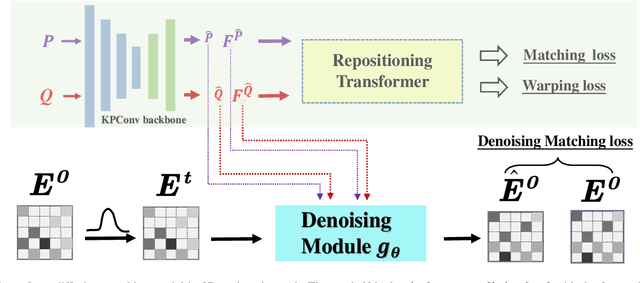
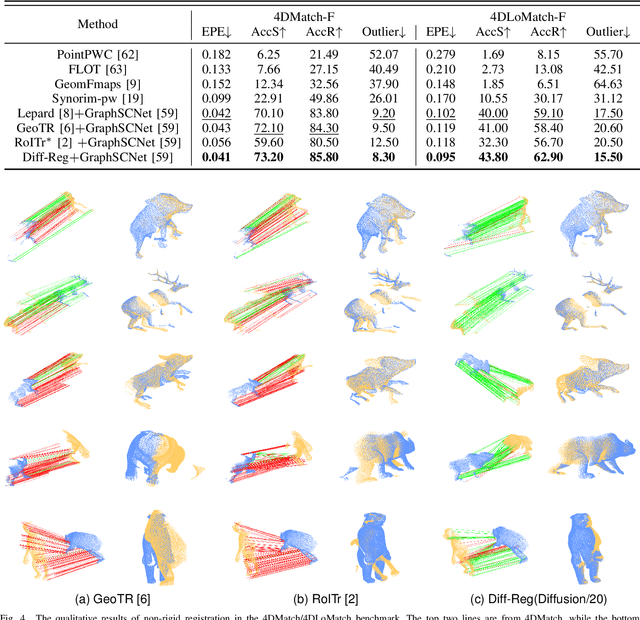
Establishing reliable correspondences is essential for registration tasks such as 3D and 2D3D registration. Existing methods commonly leverage geometric or semantic point features to generate potential correspondences. However, these features may face challenges such as large deformation, scale inconsistency, and ambiguous matching problems (e.g., symmetry). Additionally, many previous methods, which rely on single-pass prediction, may struggle with local minima in complex scenarios. To mitigate these challenges, we introduce a diffusion matching model for robust correspondence construction. Our approach treats correspondence estimation as a denoising diffusion process within the doubly stochastic matrix space, which gradually denoises (refines) a doubly stochastic matching matrix to the ground-truth one for high-quality correspondence estimation. It involves a forward diffusion process that gradually introduces Gaussian noise into the ground truth matching matrix and a reverse denoising process that iteratively refines the noisy matching matrix. In particular, the feature extraction from the backbone occurs only once during the inference phase. Our lightweight denoising module utilizes the same feature at each reverse sampling step. Evaluation of our method on both 3D and 2D3D registration tasks confirms its effectiveness.
Diff-PCR: Diffusion-Based Correspondence Searching in Doubly Stochastic Matrix Space for Point Cloud Registration
Jan 17, 2024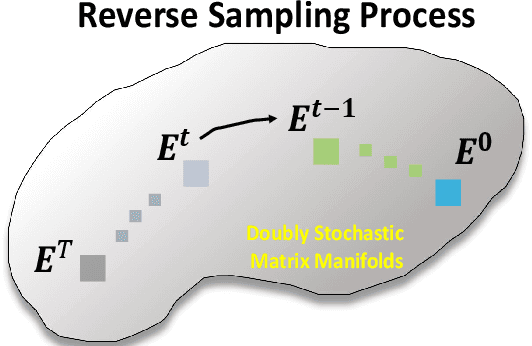
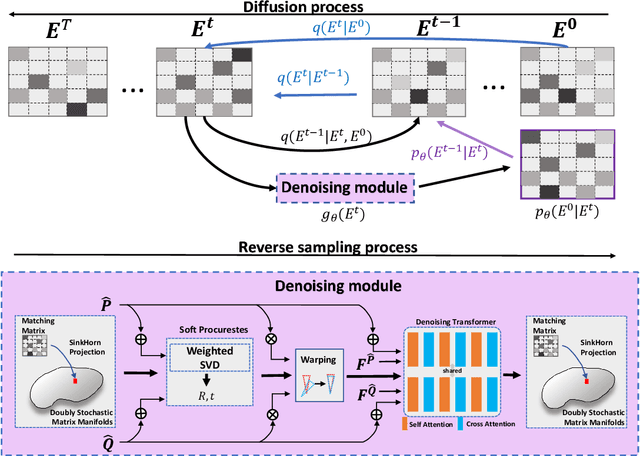
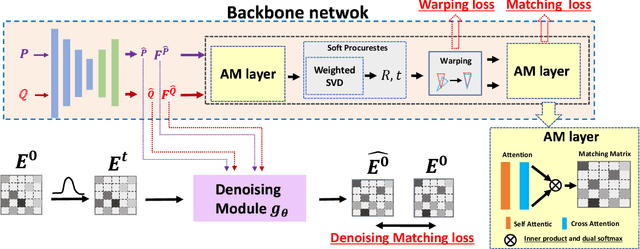

Efficiently finding optimal correspondences between point clouds is crucial for solving both rigid and non-rigid point cloud registration problems. Existing methods often rely on geometric or semantic feature embedding to establish correspondences and estimate transformations or flow fields. Recently, state-of-the-art methods have employed RAFT-like iterative updates to refine the solution. However, these methods have certain limitations. Firstly, their iterative refinement design lacks transparency, and their iterative updates follow a fixed path during the refinement process, which can lead to suboptimal results. Secondly, these methods overlook the importance of refining or optimizing correspondences (or matching matrices) as a precursor to solving transformations or flow fields. They typically compute candidate correspondences based on distances in the point feature space. However, they only project the candidate matching matrix into some matrix space once with Sinkhorn or dual softmax operations to obtain final correspondences. This one-shot projected matching matrix may be far from the globally optimal one, and these approaches do not consider the distribution of the target matching matrix. In this paper, we propose a novel approach that exploits the Denoising Diffusion Model to predict a searching gradient for the optimal matching matrix within the Doubly Stochastic Matrix Space. During the reverse denoising process, our method iteratively searches for better solutions along this denoising gradient, which points towards the maximum likelihood direction of the target matching matrix. Our method offers flexibility by allowing the search to start from any initial matching matrix provided by the online backbone or white noise. Experimental evaluations on the 3DMatch/3DLoMatch and 4DMatch/4DLoMatch datasets demonstrate the effectiveness of our newly designed framework.
SE(3) Diffusion Model-based Point Cloud Registration for Robust 6D Object Pose Estimation
Oct 26, 2023In this paper, we introduce an SE(3) diffusion model-based point cloud registration framework for 6D object pose estimation in real-world scenarios. Our approach formulates the 3D registration task as a denoising diffusion process, which progressively refines the pose of the source point cloud to obtain a precise alignment with the model point cloud. Training our framework involves two operations: An SE(3) diffusion process and an SE(3) reverse process. The SE(3) diffusion process gradually perturbs the optimal rigid transformation of a pair of point clouds by continuously injecting noise (perturbation transformation). By contrast, the SE(3) reverse process focuses on learning a denoising network that refines the noisy transformation step-by-step, bringing it closer to the optimal transformation for accurate pose estimation. Unlike standard diffusion models used in linear Euclidean spaces, our diffusion model operates on the SE(3) manifold. This requires exploiting the linear Lie algebra $\mathfrak{se}(3)$ associated with SE(3) to constrain the transformation transitions during the diffusion and reverse processes. Additionally, to effectively train our denoising network, we derive a registration-specific variational lower bound as the optimization objective for model learning. Furthermore, we show that our denoising network can be constructed with a surrogate registration model, making our approach applicable to different deep registration networks. Extensive experiments demonstrate that our diffusion registration framework presents outstanding pose estimation performance on the real-world TUD-L, LINEMOD, and Occluded-LINEMOD datasets.
Implicit Obstacle Map-driven Indoor Navigation Model for Robust Obstacle Avoidance
Aug 24, 2023



Robust obstacle avoidance is one of the critical steps for successful goal-driven indoor navigation tasks.Due to the obstacle missing in the visual image and the possible missed detection issue, visual image-based obstacle avoidance techniques still suffer from unsatisfactory robustness. To mitigate it, in this paper, we propose a novel implicit obstacle map-driven indoor navigation framework for robust obstacle avoidance, where an implicit obstacle map is learned based on the historical trial-and-error experience rather than the visual image. In order to further improve the navigation efficiency, a non-local target memory aggregation module is designed to leverage a non-local network to model the intrinsic relationship between the target semantic and the target orientation clues during the navigation process so as to mine the most target-correlated object clues for the navigation decision. Extensive experimental results on AI2-Thor and RoboTHOR benchmarks verify the excellent obstacle avoidance and navigation efficiency of our proposed method. The core source code is available at https://github.com/xwaiyy123/object-navigation.
Robust Outlier Rejection for 3D Registration with Variational Bayes
Apr 04, 2023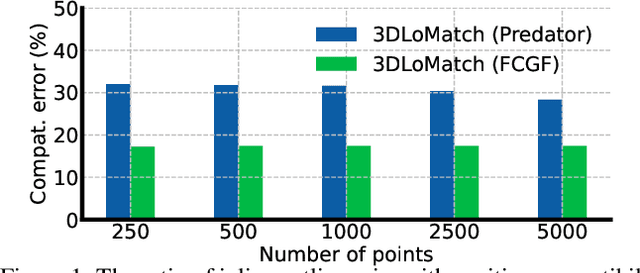
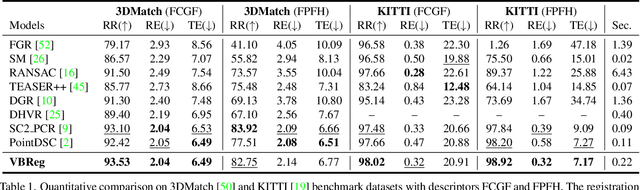
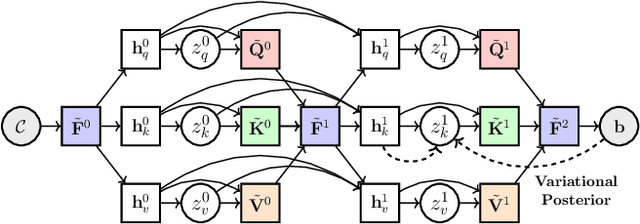
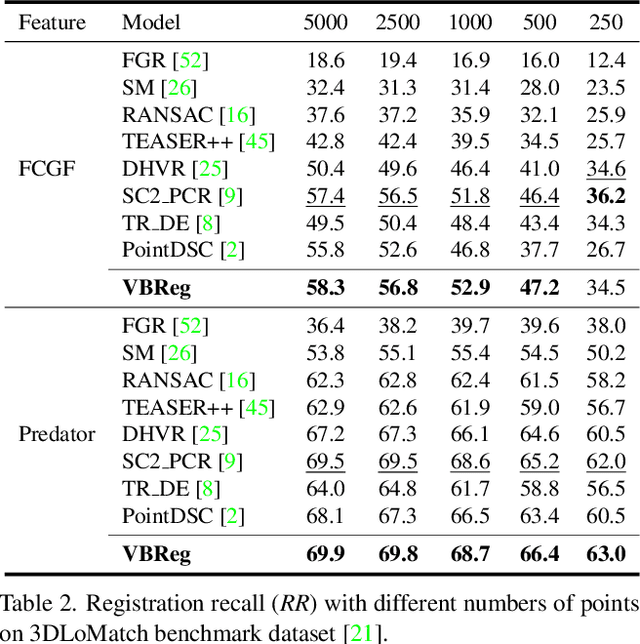
Learning-based outlier (mismatched correspondence) rejection for robust 3D registration generally formulates the outlier removal as an inlier/outlier classification problem. The core for this to be successful is to learn the discriminative inlier/outlier feature representations. In this paper, we develop a novel variational non-local network-based outlier rejection framework for robust alignment. By reformulating the non-local feature learning with variational Bayesian inference, the Bayesian-driven long-range dependencies can be modeled to aggregate discriminative geometric context information for inlier/outlier distinction. Specifically, to achieve such Bayesian-driven contextual dependencies, each query/key/value component in our non-local network predicts a prior feature distribution and a posterior one. Embedded with the inlier/outlier label, the posterior feature distribution is label-dependent and discriminative. Thus, pushing the prior to be close to the discriminative posterior in the training step enables the features sampled from this prior at test time to model high-quality long-range dependencies. Notably, to achieve effective posterior feature guidance, a specific probabilistic graphical model is designed over our non-local model, which lets us derive a variational low bound as our optimization objective for model training. Finally, we propose a voting-based inlier searching strategy to cluster the high-quality hypothetical inliers for transformation estimation. Extensive experiments on 3DMatch, 3DLoMatch, and KITTI datasets verify the effectiveness of our method.