 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration-Driven Robust Feature Matching for 3D Siamese Object Tracking
Sep 14, 2022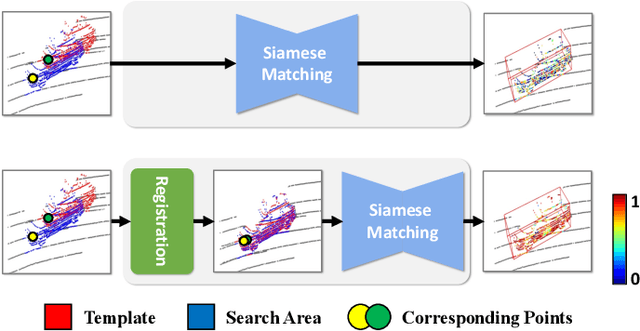
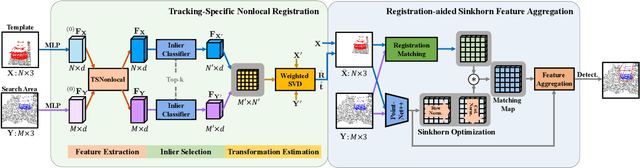
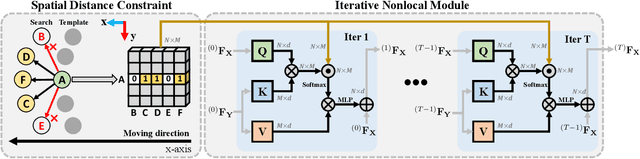
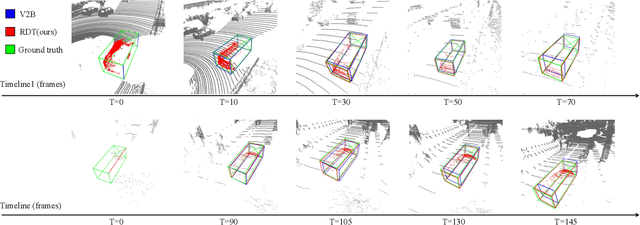
Learning robust feature matching between the template and search area is crucial for 3D Siamese tracking. The core of Siamese feature matching is how to assign high feature similarity on the corresponding points between the template and search area for precise object localization. In this paper, we propose a novel point cloud registration-driven Siamese tracking framework, with the intuition that spatially aligned corresponding points (via 3D registration) tend to achieve consistent feature representations. Specifically, our method consists of two modules, including a tracking-specific nonlocal registration module and a registration-aided Sinkhorn template-feature aggregation module. The registration module targets at the precise spatial alignment between the template and search area. The tracking-specific spatial distance constraint is proposed to refine the cross-attention weights in the nonlocal module for discriminative feature learning. Then, we use the weighted SVD to compute the rigid transformation between the template and search area, and align them to achieve the desired spatially aligned corresponding points. For the feature aggregation model, we formulate the feature matching between the transformed template and search area as an optimal transport problem and utilize the Sinkhorn optimization to search for the outlier-robust matching solution. Also, a registration-aided spatial distance map is built to improve the matching robustness in indistinguishable regions (e.g., smooth surface). Finally, guided by the obtained feature matching map, we aggregate the target information from the template into the search area to construct the target-specific feature, which is then fed into a CenterPoint-like detection head for object localization. Extensive experiments on KITTI, NuScenes and Waymo datasets verify the effectiveness of our proposed method.
3D Siamese Transformer Network for Single Object Tracking on Point Clouds
Jul 26, 2022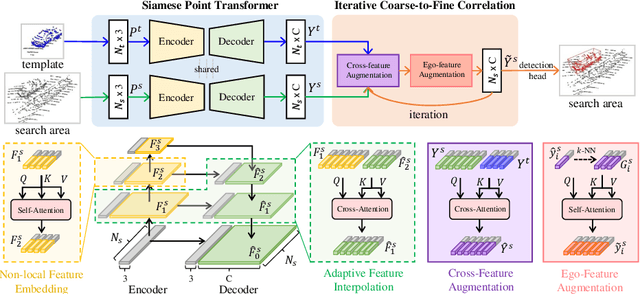
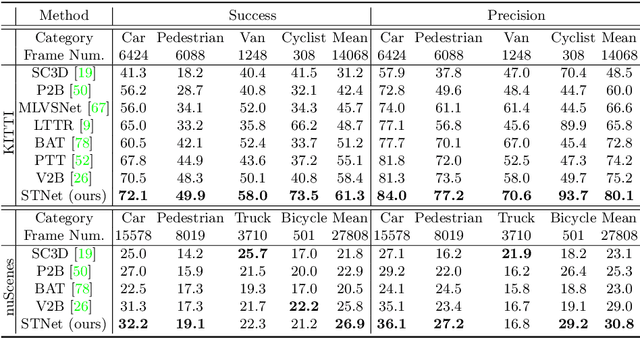
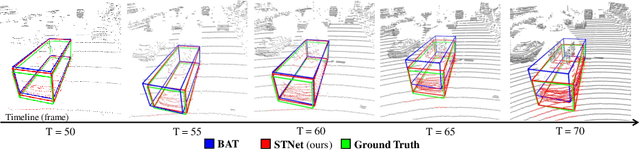
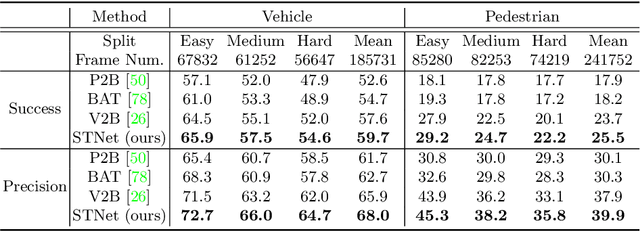
Siamese network based trackers formulate 3D single object tracking as cross-correlation learning between point features of a template and a search area. Due to the large appearance variation between the template and search area during tracking, how to learn the robust cross correlation between them for identifying the potential target in the search area is still a challenging problem. In this paper, we explicitly use Transformer to form a 3D Siamese Transformer network for learning robust cross correlation between the template and the search area of point clouds. Specifically, we develop a Siamese point Transformer network to learn shape context information of the target. Its encoder uses self-attention to capture non-local information of point clouds to characterize the shape information of the object, and the decoder utilizes cross-attention to upsample discriminative point features. After that, we develop an iterative coarse-to-fine correlation network to learn the robust cross correlation between the template and the search area. It formulates the cross-feature augmentation to associate the template with the potential target in the search area via cross attention. To further enhance the potential target, it employs the ego-feature augmentation that applies self-attention to the local k-NN graph of the feature space to aggregate target features. Experiments on the KITTI, nuScenes, and Waymo datasets show that our method achieves state-of-the-art performance on the 3D single object tracking task.