 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inter-Superpoint Affinity for Weakly Supervised 3D Instance Segmentation
Oct 11, 2022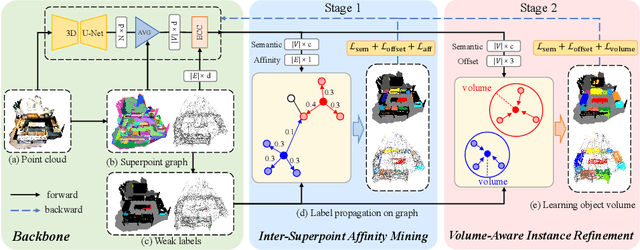
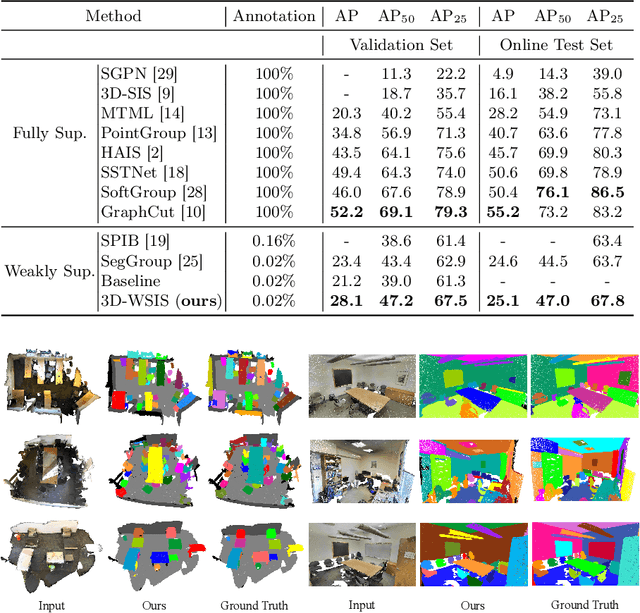
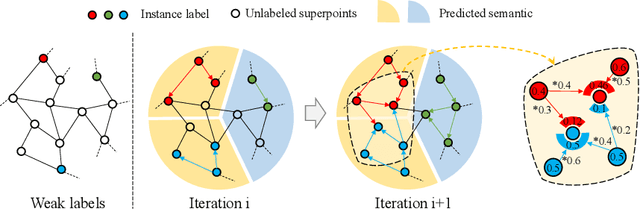
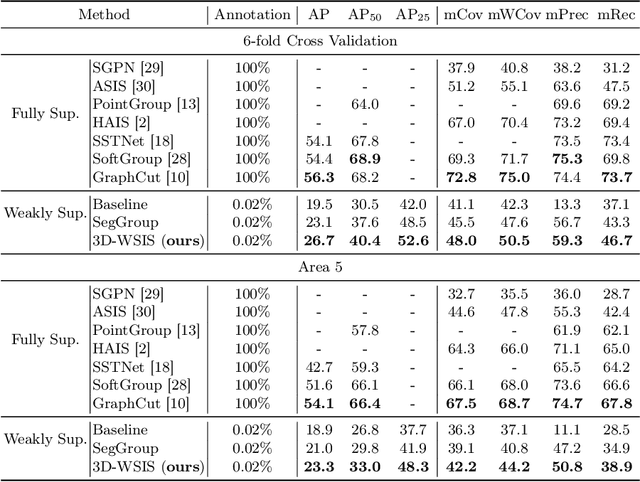
Due to the few annotated labels of 3D point clouds, how to learn discriminative features of point clouds to segment object instances is a challenging problem. In this paper, we propose a simple yet effective 3D instance segmentation framework that can achieve good performance by annotating only one point for each instance. Specifically, to tackle extremely few labels for instance segmentation, we first oversegment the point cloud into superpoints in an unsupervised manner and extend the point-level annotations to the superpoint level. Then, based on the superpoint graph, we propose an inter-superpoint affinity mining module that considers the semantic and spatial relations to adaptively learn inter-superpoint affinity to generate high-quality pseudo labels via semantic-aware random walk. Finally, we propose a volume-aware instance refinement module to segment high-quality instances by applying volume constraints of objects in clustering on the superpoint graph. Extensive experiments on the ScanNet-v2 and S3DIS datasets demonstrate that our method achieves state-of-the-art performance in the weakly supervised point cloud instance segmentation task, and even outperforms some fully supervised methods.
3D Siamese Transformer Network for Single Object Tracking on Point Clouds
Jul 26, 2022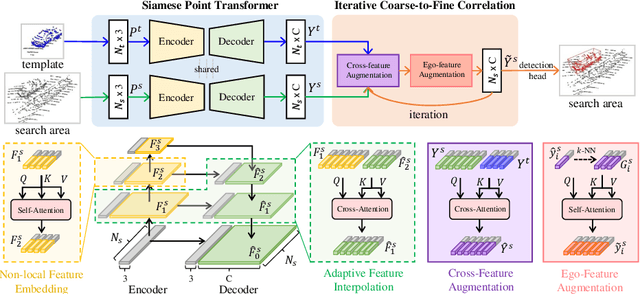
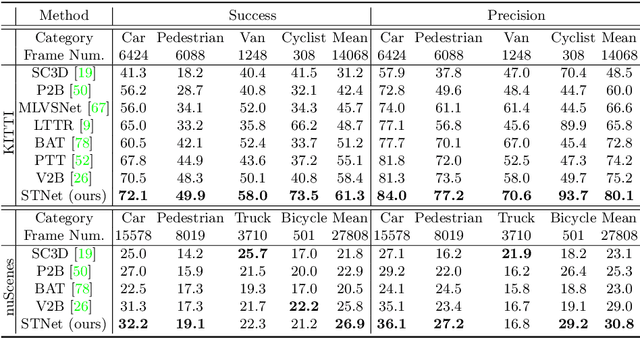
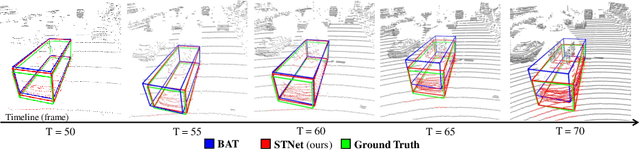
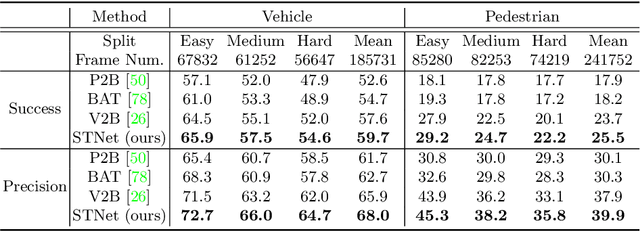
Siamese network based trackers formulate 3D single object tracking as cross-correlation learning between point features of a template and a search area. Due to the large appearance variation between the template and search area during tracking, how to learn the robust cross correlation between them for identifying the potential target in the search area is still a challenging problem. In this paper, we explicitly use Transformer to form a 3D Siamese Transformer network for learning robust cross correlation between the template and the search area of point clouds. Specifically, we develop a Siamese point Transformer network to learn shape context information of the target. Its encoder uses self-attention to capture non-local information of point clouds to characterize the shape information of the object, and the decoder utilizes cross-attention to upsample discriminative point features. After that, we develop an iterative coarse-to-fine correlation network to learn the robust cross correlation between the template and the search area. It formulates the cross-feature augmentation to associate the template with the potential target in the search area via cross attention. To further enhance the potential target, it employs the ego-feature augmentation that applies self-attention to the local k-NN graph of the feature space to aggregate target features. Experiments on the KITTI, nuScenes, and Waymo datasets show that our method achieves state-of-the-art performance on the 3D single object tracking task.