 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Ownership Verification for Pre-trained Masked Models
Jul 16, 2025High-quality open-source datasets have emerged as a pivotal catalyst driving the swift advancement of deep learning, while facing the looming threat of potential exploitation. Protecting these datasets is of paramount importance for the interests of their owners. The verification of dataset ownership has evolved into a crucial approach in this domain; however, existing verification techniques are predominantly tailored to supervised models and contrastive pre-trained models, rendering them ill-suited for direct application to the increasingly prevalent masked models. In this work, we introduce the inaugural methodology addressing this critical, yet unresolved challenge, termed Dataset Ownership Verification for Masked Modeling (DOV4MM). The central objective is to ascertain whether a suspicious black-box model has been pre-trained on a particular unlabeled dataset, thereby assisting dataset owners in safeguarding their rights. DOV4MM is grounded in our empirical observation that when a model is pre-trained on the target dataset, the difficulty of reconstructing masked information within the embedding space exhibits a marked contrast to models not pre-trained on that dataset. We validated the efficacy of DOV4MM through ten masked image models on ImageNet-1K and four masked language models on WikiText-103. The results demonstrate that DOV4MM rejects the null hypothesis, with a $p$-value considerably below 0.05, surpassing all prior approaches. Code is available at https://github.com/xieyc99/DOV4MM.
Mask6D: Masked Pose Priors For 6D Object Pose Estimation
Jul 09, 2025Robust 6D object pose estimation in cluttered or occluded conditions using monocular RGB images remains a challenging task. One reason is that current pose estimation networks struggle to extract discriminative, pose-aware features using 2D feature backbones, especially when the available RGB information is limited due to target occlusion in cluttered scenes. To mitigate this, we propose a novel pose estimation-specific pre-training strategy named Mask6D. Our approach incorporates pose-aware 2D-3D correspondence maps and visible mask maps as additional modal information, which is combined with RGB images for the reconstruction-based model pre-training. Essentially, this 2D-3D correspondence maps a transformed 3D object model to 2D pixels, reflecting the pose information of the target in camera coordinate system. Meanwhile, the integrated visible mask map can effectively guide our model to disregard cluttered background information. In addition, an object-focused pre-training loss function is designed to further facilitate our network to remove the background interference. Finally, we fine-tune our pre-trained pose prior-aware network via conventional pose training strategy to realize the reliable pose prediction. Extensive experiments verify that our method outperforms previous end-to-end pose estimation methods.
Training Data Provenance Verification: Did Your Model Use Synthetic Data from My Generative Model for Training?
Mar 12, 2025High-quality open-source text-to-image models have lowered the threshold for obtaining photorealistic images significantly, but also face potential risks of misuse. Specifically, suspects may use synthetic data generated by these generative models to train models for specific tasks without permission, when lacking real data resources especially. Protecting these generative models is crucial for the well-being of their owners. In this work, we propose the first method to this important yet unresolved issue, called Training data Provenance Verification (TrainProVe). The rationale behind TrainProVe is grounded in the principle of generalization error bound, which suggests that, for two models with the same task, if the distance between their training data distributions is smaller, their generalization ability will be closer. We validate the efficacy of TrainProVe across four text-to-image models (Stable Diffusion v1.4, latent consistency model, PixArt-$\alpha$, and Stable Cascade). The results show that TrainProVe achieves a verification accuracy of over 99\% in determining the provenance of suspicious model training data, surpassing all previous methods. Code is available at https://github.com/xieyc99/TrainProVe.
Dataset Ownership Verification in Contrastive Pre-trained Models
Feb 11, 2025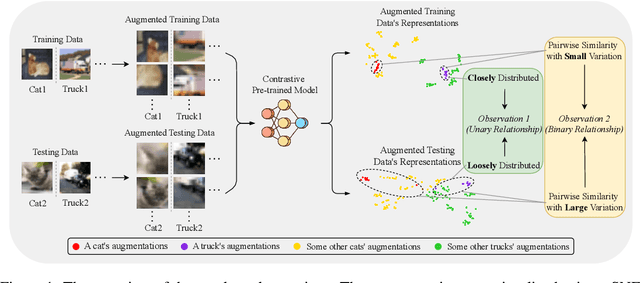
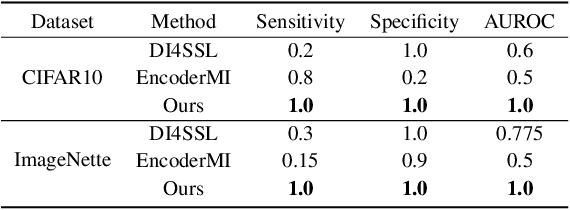
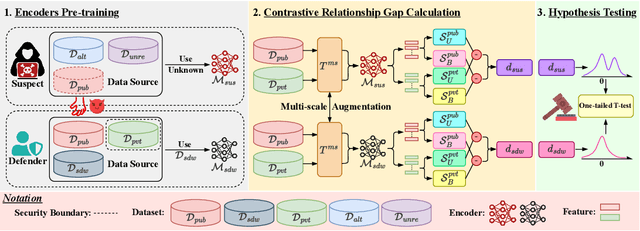
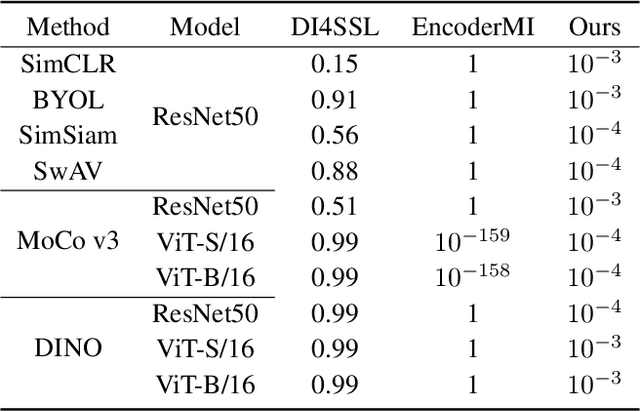
High-quality open-source datasets, which necessitate substantial efforts for curation, has become the primary catalyst for the swift progress of deep learning. Concurrently, protecting these datasets is paramount for the well-being of the data owner. Dataset ownership verification emerges as a crucial method in this domain, but existing approaches are often limited to supervised models and cannot be directly extended to increasingly popular unsupervised pre-trained models. In this work, we propose the first dataset ownership verification method tailored specifically for self-supervised pre-trained models by contrastive learning. Its primary objective is to ascertain whether a suspicious black-box backbone has been pre-trained on a specific unlabeled dataset, aiding dataset owners in upholding their rights. The proposed approach is motivated by our empirical insights that when models are trained with the target dataset, the unary and binary instance relationships within the embedding space exhibit significant variations compared to models trained without the target dataset. We validate the efficacy of this approach across multiple contrastive pre-trained models including SimCLR, BYOL, SimSiam, MOCO v3, and DINO. The results demonstrate that our method rejects the null hypothesis with a $p$-value markedly below $0.05$, surpassing all previous methodologies. Our code is available at https://github.com/xieyc99/DOV4CL.